
Utilizzare BigQuery DataFrames in dbt
dbt (data build tool) è un framework open source da riga di comando progettato per la trasformazione dei dati all'interno dei data warehouse moderni. dbt facilita le trasformazioni dei dati modulari tramite la creazione di modelli riutilizzabili basati su SQL e Python. Lo strumento orchestra l'esecuzione di queste trasformazioni all'interno del data warehouse di destinazione, concentrandosi sulla fase di trasformazione della pipeline ELT. Per saperne di più, consulta la documentazione di dbt.
In dbt, un modello Python è una trasformazione dei dati definita ed eseguita utilizzando il codice Python all'interno del progetto dbt. Anziché scrivere SQL per la logica di trasformazione, scrivi script Python che dbt orchestra per l'esecuzione nell'ambiente del data warehouse. Un modello Python ti consente di eseguire trasformazioni dei dati che potrebbero essere complesse o inefficienti da esprimere in SQL. In questo modo, puoi sfruttare le funzionalità di Python pur beneficiando della struttura del progetto, dell'orchestrazione, della gestione delle dipendenze, dei test e delle funzionalità di documentazione di dbt. Per saperne di più, consulta la sezione Modelli Python.
L'dbt-bigqueryadattatore
supporta l'esecuzione del codice Python definito in
BigQuery DataFrames. Questa funzionalità è disponibile in
dbt Cloud e
dbt Core.
Puoi anche ottenere questa funzionalità clonando l'ultima versione dell'adattatore dbt-bigquery.
Prima di iniziare
Per utilizzare l'adattatore dbt-bigquery, abilita le seguenti API nel tuo progetto:
- API BigQuery (
bigquery.googleapis.com) - API Storage di Cloud (
storage.googleapis.com) - API Compute Engine (
compute.googleapis.com) - API Dataform (
dataform.googleapis.com) - API Identity and Access Management (
iam.googleapis.com) - API Vertex AI (
aiplatform.googleapis.com)
Ruoli richiesti per abilitare le API
Per abilitare le API, devi disporre del ruolo IAM Amministratore utilizzo dei servizi (roles/serviceusage.serviceUsageAdmin), che
contiene l'autorizzazione serviceusage.services.enable. Scopri come concedere
i ruoli.
Ruoli obbligatori
L'adattatore dbt-bigquery supporta l'autenticazione basata su OAuth e basata su account di servizio. Le sezioni seguenti descrivono i ruoli richiesti a seconda di come prevedi di eseguire l'autenticazione.
OAuth
Se prevedi di eseguire l'autenticazione all'adattatore dbt-bigquery utilizzando OAuth, chiedi all'amministratore di concederti i seguenti ruoli:
- Ruolo Utente BigQuery
(
roles/bigquery.user) sul progetto - Ruolo Editor dati BigQuery
(
roles/bigquery.dataEditor) sul progetto o sul set di dati in cui vengono salvate le tabelle - Ruolo Utente Colab Enterprise
(
roles/colabEnterprise.user) sul progetto - Ruolo Storage Admin
(
roles/storage.admin) sul bucket Cloud Storage di gestione temporanea per il codice e i log di gestione temporanea
Service account
Se prevedi di eseguire l'autenticazione all'adattatore dbt-bigquery utilizzando un service account nel tuo progetto, chiedi all'amministratore di concedere i seguenti ruoli al account di servizio che prevedi di utilizzare:
- Ruolo Utente BigQuery
(
roles/bigquery.user) - Ruolo Editor dati BigQuery
(
roles/bigquery.dataEditor) - Ruolo Utente Colab Enterprise
(
roles/colabEnterprise.user) - Ruolo Storage Admin
(
roles/storage.admin)
Se esegui l'autenticazione utilizzando un service account, assicurati anche di aver concesso il
ruolo Utente account di servizio
(roles/iam.serviceAccountUser) per il service account che prevedi di utilizzare.
Simulazione dell'identità dei service account
Se prevedi di eseguire l'autenticazione all'adattatore dbt-bigquery utilizzando OAuth, ma vuoi che l'elaborazione dei dati e l'esecuzione del notebook avvengano con l'identità di un account di servizio nello stesso progetto in cui vengono eseguiti i job, chiedi all'amministratore di concederti i seguenti ruoli:
- Ruolo Creatore token account di servizio
(
roles/iam.serviceAccountTokenCreator) - Utente account di servizio
(
roles/iam.serviceAccountUser)
Il account di servizio con identità simulata deve disporre anche di tutti i ruoli richiesti per l' autenticazione.
Service account tra progetti
Se prevedi di eseguire l'autenticazione all'adattatore dbt-bigquery utilizzando un service account in un progetto diverso, il progetto delle credenziali, da cui vengono eseguiti i job, il progetto di esecuzione, chiedi all'amministratore di:
- Disattivare il vincolo
constraints/iam.disableCrossProjectServiceAccountUsagenel progetto delle credenziali. Oltre a tutti i ruoli richiesti per account di servizio account, concedi i seguenti ruoli al account di servizio nel progetto delle credenziali:
- Ruolo Vertex AI Service Agent
(roles/aiplatform.serviceAgent) a
service-PROJECT_NUMBER@gcp-sa-aiplatform.s3ns-system.iam.gserviceaccount.com - Ruolo Vertex AI Colab Service Agent
(roles/aiplatform.colabServiceAgent) a
service-PROJECT_NUMBER@gcp-sa-vertex-nb.s3ns-system.iam.gserviceaccount.com - Ruolo Compute Engine Service Agent
(roles/compute.serviceAgent) a
service-PROJECT_NUMBER@compute-system.s3ns-system.iam.gserviceaccount.com
- Ruolo Vertex AI Service Agent
(roles/aiplatform.serviceAgent) a
Se prevedi di eseguire l'autenticazione all'adattatore dbt-bigquery utilizzando OAuth, ma vuoi che l'elaborazione dei dati e l'esecuzione del notebook avvengano con l'identità di un account di servizio in un progetto diverso da quello in cui vengono eseguiti i job, chiedi all'amministratore di:
- Seguire i passaggi descritti in precedenza per i service account tra progetti per il account di servizio in un altro progetto.
- Concedere a te e al account di servizio i ruoli richiesti per la account di servizio account
VPC condiviso
Se utilizzi Colab Enterprise in un ambiente VPC condiviso, chiedi all'amministratore di concedere i seguenti ruoli e autorizzazioni:
compute.subnetworks.useautorizzazione: concedi questa autorizzazione al account di servizio utilizzato dal runtime di Colab Enterprise nel progetto host o in subnet specifiche. Questa autorizzazione è inclusa nel ruolo Utente rete Compute (roles/compute.networkUser).compute.subnetworks.getautorizzazione: concedi questa autorizzazione al account di servizio utilizzato dal runtime di Colab Enterprise nel progetto host o in subnet specifiche. Questa autorizzazione è inclusa nel ruolo Visualizzatore rete Compute (roles/compute.networkViewer).Ruolo Utente rete Compute (
roles/compute.networkUser): concedi questo ruolo al service agent della piattaforma Gemini Enterprise Agent agent,service-PROJECT_NUMBER@gcp-sa-aiplatform.s3ns-system.iam.gserviceaccount.com, nel progetto host VPC condiviso.Ruolo Utente rete Compute (
roles/compute.networkUser): se viene utilizzata la funzionalità di job di esecuzione del notebook, concedi questo ruolo all'agente di servizio di Colab Enterprise,service-PROJECT_NUMBER@gcp-sa-vertex-nb.s3ns-system.iam.gserviceaccount.com, nel progetto host VPC condiviso.
Per saperne di più sulla concessione dei ruoli, consulta Gestisci l'accesso a progetti, cartelle e organizzazioni.
Potresti anche riuscire a ottenere le autorizzazioni richieste tramite i ruoli personalizzati o altri ruoli predefiniti.
Ambiente di esecuzione Python
L'dbt-bigquery adapter utilizza il
servizio di esecuzione dei notebook Colab Enterprise
per eseguire il codice Python di BigQuery DataFrames. Un notebook Colab Enterprise viene creato ed eseguito automaticamente dall'adattatore dbt-bigquery per ogni modello Python. Puoi scegliere il
Cloud de Confiance progetto in cui eseguire il notebook. Il notebook esegue il codice Python del modello, che viene convertito in BigQuery SQL dalla libreria BigQuery DataFrames. Il codice BigQuery SQL viene quindi eseguito nel progetto configurato. Il seguente diagramma mostra il flusso di controllo:
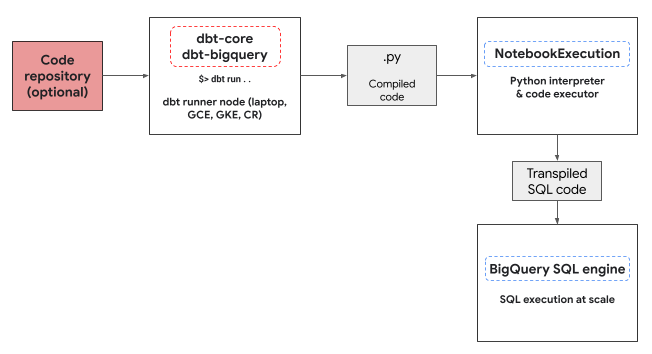
Se nel progetto non è già disponibile un modello di notebook e l'utente che esegue il codice dispone delle autorizzazioni per creare il modello, l'adattatore dbt-bigquery crea e utilizza automaticamente il modello di notebook predefinito. Puoi
anche specificare un modello di notebook diverso utilizzando una
configurazione dbt.
L'esecuzione del notebook richiede un bucket Cloud Storage di gestione temporanea per archiviare il codice e i log. Tuttavia, l'adattatore dbt-bigquery copia i log nei
log dbt, quindi non devi
esaminare il bucket.
Funzionalità supportate
L'adattatore dbt-bigquery supporta le seguenti funzionalità per i modelli Python dbt che eseguono BigQuery DataFrames:
- Caricamento dei dati da una tabella BigQuery esistente con la macro
dbt.source(). - Caricamento dei dati da altri modelli dbt con la macro
dbt.ref()per creare dipendenze e grafici aciclici diretti (DAG) con i modelli Python. - Specifica e utilizzo dei pacchetti Python di PyPi che possono essere utilizzati con l'esecuzione del codice Python. Per saperne di più, consulta la sezione Configurazioni.
- Specifica di un modello di runtime del notebook personalizzato per i modelli BigQuery DataFrames.
L'adattatore dbt-bigquery supporta le seguenti strategie di materializzazione:
- Materializzazione della tabella, in cui i dati vengono ricreati come tabella a ogni esecuzione.
- Materializzazione incrementale con una strategia di unione, in cui i dati nuovi o aggiornati vengono aggiunti a una tabella esistente, spesso utilizzando una strategia di unione per gestire le modifiche.
Configurare dbt per utilizzare BigQuery DataFrames
Se utilizzi
dbt Core,
devi utilizzare un file profiles.yml per l'utilizzo con BigQuery DataFrames.
L'esempio seguente utilizza il metodo oauth:
your_project_name:
outputs:
dev:
compute_region: us-central1
dataset: your_bq_dateset
gcs_bucket: your_gcs_bucket
job_execution_timeout_seconds: 300
job_retries: 1
location: US
method: oauth
priority: interactive
project: your_gcp_project
threads: 1
type: bigquery
target: dev
Se utilizzi
dbt Cloud,
puoi
connetterti alla tua piattaforma dati
direttamente nell'interfaccia dbt Cloud. In questo scenario, non hai bisogno di un file profiles.yml. Per saperne di più, consulta la sezione
Informazioni su profiles.yml.
Di seguito è riportato un esempio di configurazione a livello di progetto per il file dbt_project.yml:
# Name your project! Project names should contain only lowercase characters
# and underscores. A good package name should reflect your organization's
# name or the intended use of these models.
name: 'your_project_name'
version: '1.0.0'
# Configuring models
# Full documentation: https://docs.getdbt.com/docs/configuring-models
# In this example config, we tell dbt to build all models in the example/
# directory as views. These settings can be overridden in the individual model
# files using the config(...) macro.
models:
your_project_name:
submission_method: bigframes
notebook_template_id: 7018811640745295872
packages: ["scikit-learn", "mlflow"]
timeout: 3000
# Config indicated by + and applies to all files under models/example/
example:
+materialized: view
Alcuni parametri possono essere configurati anche utilizzando il metodo dbt.config all'interno del codice Python. Se queste impostazioni sono in conflitto con il file dbt_project.yml, le configurazioni con dbt.config avranno la precedenza.
Per saperne di più, consulta le sezioni Configurazioni dei modelli e dbt_project.yml.
Configurazioni
Puoi configurare le seguenti impostazioni utilizzando il metodo dbt.config nel modello Python. Queste configurazioni sostituiscono la configurazione a livello di progetto.
| Configurazione | Obbligatorio | Utilizzo |
|---|---|---|
submission_method |
Sì | submission_method=bigframes |
notebook_template_id |
No | Se non specificato, viene creato e utilizzato un modello predefinito. |
packages |
No | Se necessario, specifica l'elenco aggiuntivo di pacchetti Python. |
timeout |
No | (Facoltativo) Estendi il timeout di esecuzione del job. |
Esempi di modelli Python
Le sezioni seguenti presentano scenari di esempio e modelli Python.
Caricare i dati da una tabella BigQuery
Per utilizzare i dati di una tabella BigQuery esistente come origine nel modello Python, devi prima definire questa origine in un file YAML. L'esempio seguente è definito in un file source.yml.
version: 2
sources:
- name: my_project_source # A custom name for this source group
database: bigframes-dev # Your Google Cloud project ID
schema: yyy_test_us # The BigQuery dataset containing the table
tables:
- name: dev_sql1 # The name of your BigQuery table
Poi, crei il modello Python, che può utilizzare le origini dati configurate in questo file YAML:
def model(dbt, session):
# Configure the model to use BigFrames for submission
dbt.config(submission_method="bigframes")
# Load data from the 'dev_sql1' table within 'my_project_source'
source_data = dbt.source('my_project_source', 'dev_sql1')
# Example transformation: Create a new column 'id_new'
source_data['id_new'] = source_data['id'] * 10
return source_data
Fare riferimento a un altro modello
Puoi creare modelli che dipendono dall'output di altri modelli dbt, come mostrato nell'esempio seguente. Questa operazione è utile per creare pipeline di dati modulari.
def model(dbt, session):
# Configure the model to use BigFrames
dbt.config(submission_method="bigframes")
# Reference another dbt model named 'dev_sql1'.
# It assumes you have a model defined in 'dev_sql1.sql' or 'dev_sql1.py'.
df_from_sql = dbt.ref("dev_sql1")
# Example transformation on the data from the referenced model
df_from_sql['id'] = df_from_sql['id'] * 100
return df_from_sql
Specificare una dipendenza del pacchetto
Se il modello Python richiede librerie di terze parti specifiche come MLflow o Boto3, puoi dichiarare il pacchetto nella configurazione del modello, come mostrato nell' esempio seguente. Questi pacchetti vengono installati nell'ambiente di esecuzione.
def model(dbt, session):
# Configure the model for BigFrames and specify required packages
dbt.config(
submission_method="bigframes",
packages=["mlflow", "boto3"] # List the packages your model needs
)
# Import the specified packages for use in your model
import mlflow
import boto3
# Example: Create a DataFrame showing the versions of the imported packages
data = {
"mlflow_version": [mlflow.__version__],
"boto3_version": [boto3.__version__],
"note": ["This demonstrates accessing package versions after import."]
}
bdf = bpd.DataFrame(data)
return bdf
Specificare un modello non predefinito
Per un maggiore controllo sull'ambiente di esecuzione o per utilizzare impostazioni preconfigurate, puoi specificare un modello di notebook non predefinito per il modello BigQuery DataFrames, come mostrato nell'esempio seguente.
def model(dbt, session):
dbt.config(
submission_method="bigframes",
# ID of your pre-created notebook template
notebook_template_id="857350349023451yyyy",
)
data = {"int": [1, 2, 3], "str": ['a', 'b', 'c']}
return bpd.DataFrame(data=data)
Materializzare le tabelle
Quando dbt esegue i modelli Python, deve sapere come salvare i risultati nel data warehouse. Questa operazione viene chiamata materializzazione.
Per la materializzazione standard delle tabelle, dbt crea o sostituisce completamente una tabella nel warehouse con l'output del modello ogni volta che viene eseguito. Questa operazione viene eseguita
per impostazione predefinita o impostando esplicitamente la proprietà materialized='table', come
mostrato nell'esempio seguente.
def model(dbt, session):
dbt.config(
submission_method="bigframes",
# Instructs dbt to create/replace this model as a table
materialized='table',
)
data = {"int_column": [1, 2], "str_column": ['a', 'b']}
return bpd.DataFrame(data=data)
La materializzazione incrementale con una strategia di unione consente a dbt di aggiornare la tabella solo con le righe nuove o modificate. Questa operazione è utile per i set di dati di grandi dimensioni perché la ricreazione completa di una tabella ogni volta può essere inefficiente. La strategia di unione è un modo comune per gestire questi aggiornamenti.
Questo approccio integra in modo intelligente le modifiche eseguendo le seguenti operazioni:
- Aggiornamento delle righe esistenti che sono state modificate.
- Aggiunta di nuove righe.
- (Facoltativo, a seconda della configurazione) Eliminazione delle righe non più presenti nell'origine.
Per utilizzare la strategia di unione, devi specificare una proprietà unique_key che dbt può utilizzare per identificare le righe corrispondenti tra l'output del modello e la tabella esistente, come mostrato nell'esempio seguente.
def model(dbt, session):
dbt.config(
submission_method="bigframes",
materialized='incremental',
incremental_strategy='merge',
unique_key='int', # Specifies the column to identify unique rows
)
# In this example:
# - Row with 'int' value 1 remains unchanged.
# - Row with 'int' value 2 has been updated.
# - Row with 'int' value 4 is a new addition.
# The 'merge' strategy will ensure that only the updated row ('int 2')
# and the new row ('int 4') are processed and integrated into the table.
data = {"int": [1, 2, 4], "str": ['a', 'bbbb', 'd']}
return bpd.DataFrame(data=data)
Risoluzione dei problemi
Puoi osservare l'esecuzione di Python nei log dbt.
Inoltre, puoi visualizzare il codice e i log (incluse le esecuzioni precedenti) nella pagina Esecuzioni di Colab Enterprise.
Vai a Esecuzioni di Colab Enterprise
Fatturazione
Quando utilizzi l'adattatore dbt-bigquery con BigQuery DataFrames,
vengono applicati Cloud de Confiance by S3NS addebiti per:
Esecuzione del notebook: ti viene addebitata l'esecuzione del runtime del notebook. Per saperne di più, consulta la sezione Prezzi del runtime del notebook.
Esecuzione di query BigQuery: nel notebook, BigQuery DataFrames converte Python in SQL ed esegue il codice in BigQuery. Ti vengono addebitati costi in base alla configurazione del progetto e alla query, come descritto per i prezzi di BigQuery DataFrames.
Puoi utilizzare la seguente etichetta di fatturazione nella console di fatturazione BigQuery per filtrare il report sulla fatturazione per l'esecuzione del notebook e per le esecuzioni di BigQuery attivate dall'adattatore dbt-bigquery:
- Etichetta di esecuzione di BigQuery:
bigframes-dbt-api
Passaggi successivi
- Per saperne di più su dbt e BigQuery DataFrames, consulta la sezione Utilizzare BigQuery DataFrames con i modelli Python dbt.
- Per saperne di più sui modelli Python dbt, consulta le sezioni Modelli Python e Configurazione dei modelli Python.
- Per saperne di più sui notebook Colab Enterprise, consulta la sezione Creare un notebook Colab Enterprise utilizzando la Cloud de Confiance console.
- Per saperne di più sui Cloud de Confiance by S3NS partner, consulta la sezione Cloud de Confiance by S3NS Partner BigQuery.