
遷移評估
您可以透過 BigQuery 遷移評估,規劃及檢查現有資料倉儲遷移至 BigQuery 的作業。執行 BigQuery 遷移評估後,系統會產生報表,評估在 BigQuery 中儲存資料的費用,瞭解 BigQuery 如何最佳化現有工作負載以節省成本,並準備遷移計畫,其中會列出將資料倉儲遷移至 BigQuery 所需的時間和工作量。
本文說明如何使用 BigQuery 遷移評估,以及查看評估結果的各種方式。本文適用於熟悉 Cloud de Confiance 控制台和批次 SQL 翻譯器的使用者。
事前準備
如要準備及執行 BigQuery 遷移評估,請按照下列步驟操作:
從資料倉儲擷取中繼資料和查詢記錄。
將中繼資料和查詢記錄上傳至 Cloud Storage bucket。
選用:查詢評估結果,找出詳細或特定的評估資訊。
從資料倉儲擷取中繼資料和查詢記錄
準備評估和建議時,需要中繼資料和查詢記錄。
如要擷取執行評估作業所需的中繼資料和查詢記錄,請選取資料倉儲:
Databricks
如要尋求支援或針對這項功能提供意見回饋,請傳送電子郵件至 bq-edw-migration-support@google.com。
如要開始擷取 Databricks 評估的中繼資料,請先在 Databricks 環境中下載並執行擷取工具。
這項擷取工具是筆記本,可產生 ZIP 封存檔案,其中包含多個 Databricks 檢視區塊的表示法。這些檢視畫面包含評估所需的資料。
下載擷取工具
筆記本的下載連結位於Cloud de Confiance 控制台的「評估」部分。檔案會以 ZIP 封存檔的形式提供,內含下列項目:
- 擷取筆記本
- 筆記本在擷取程序期間執行的公用程式 Python 指令碼。
匯入及設定擷取工具
- 使用 Databricks 使用者介面匯入上一個步驟中的 ZIP 檔案。
- 匯入後,開啟擷取筆記本,並完成所有標示為「設定」的步驟。
筆記本的驗證是設定步驟的一部分。筆記本支援兩種 Databricks 驗證方法:
您必須使用其中一種方法,才能繼續前往下一節。 如果可以,建議您使用服務主體,而非 PAT,因為 Databricks 認為 PAT 選項是舊版做法。
取得評估資料
完成所有設定步驟後,即可執行筆記本。啟用擷取筆記本後,請使用「全部執行」選項執行筆記本。
如果系統非常龐大,執行筆記本可能需要一天時間。如果是一般系統 (約有 50,000 個資料表),擷取作業會在 1 小時內完成。
選用:監控擷取筆記本進度
擷取筆記本會提供記錄,其中包含進度和錯誤資訊,方便您監控。特定筆記本執行的最新記錄訊息會包含擷取內容的相關資訊。
由於筆記本執行作業不會在發生第一個錯誤時停止,因此請分兩步驟檢查錯誤:
- 擷取完成後,請查看摘要中的錯誤計數或其他錯誤指標,例如找到的資料少於預期。如果結果可接受,您可以略過下一個步驟。
- 複製記錄輸出內容,並儲存為文字檔。
完成擷取程序
筆記本完成擷取程序後,您可以在筆記本的最後一個部分點選下載按鈕,下載結果。
Snowflake
需求條件
如要從 Snowflake 擷取中繼資料和查詢記錄,必須符合下列條件:
- 可連線至 Snowflake 執行個體的機器。
- Cloud de Confiance by S3NS 帳戶,並具備 Cloud Storage bucket 來儲存資料。
- 用於儲存結果的空白 BigQuery 資料集。或者,您也可以使用 Cloud de Confiance 控制台 UI 建立評估工作時,一併建立 BigQuery 資料集。
- 在資料庫上具有
IMPORTED PRIVILEGES存取權的 Snowflake 使用者Snowflake。建議您建立採用金鑰配對驗證的使用者。SERVICE這樣一來,您就能安全存取 Snowflake 資料平台,不必產生多重驗證權杖。- 如要建立新的服務使用者,請按照 Snowflake 官方指南操作。您必須產生 RSA 金鑰組,並將公開金鑰指派給 Snowflake 使用者。
- 服務使用者應具備
ACCOUNTADMIN角色,或由帳戶管理員授予資料庫的IMPORTED PRIVILEGES權限Snowflake。 - 除了金鑰組驗證,您也可以使用密碼驗證。不過,自 2025 年 8 月起,Snowflake 會對所有密碼驗證使用者強制執行 MFA。因此,使用擷取工具時,您必須核准 MFA 推播通知。
執行 dwh-migration-dumper 工具
下載 dwh-migration-dumper 指令列擷取工具。
下載 SHA256SUMS.txt 檔案,然後執行下列指令,確認 zip 檔案是否正確:
Bash
sha256sum --check SHA256SUMS.txt
Windows PowerShell
(Get-FileHash RELEASE_ZIP_FILENAME).Hash -eq ((Get-Content SHA256SUMS.txt) -Split " ")[0]
將 RELEASE_ZIP_FILENAME 替換為 dwh-migration-dumper 指令列擷取工具發布版本的下載 ZIP 檔案名稱,例如 dwh-migration-tools-v1.0.52.zip
True 結果會確認總和檢查碼驗證是否成功。
False 結果表示驗證錯誤。請確認總和檢查碼和 ZIP 檔案是從相同發布版本下載,並放在相同目錄中。
如要進一步瞭解如何使用 dwh-migration-dumper 工具,請參閱「產生中繼資料」頁面。
使用 dwh-migration-dumper 工具從 Snowflake 資料倉儲擷取記錄和中繼資料,並壓縮成兩個 zip 檔案。在可存取來源資料倉儲的機器上執行下列指令,產生檔案。
產生中繼資料 ZIP 檔案:
dwh-migration-dumper \ --connector snowflake \ --host HOST_NAME \ --user USER_NAME \ --role ROLE_NAME \ --warehouse WAREHOUSE \ --assessment \ --private-key-file PRIVATE_KEY_PATH \ --private-key-password PRIVATE_KEY_PASSWORD
產生包含查詢記錄的 ZIP 檔案:
dwh-migration-dumper \ --connector snowflake-logs \ --host HOST_NAME \ --user USER_NAME \ --role ROLE_NAME \ --warehouse WAREHOUSE \ --query-log-start STARTING_DATE \ --query-log-end ENDING_DATE \ --assessment \ --private-key-file PRIVATE_KEY_PATH \ --private-key-password PRIVATE_KEY_PASSWORD
更改下列內容:
HOST_NAME:Snowflake 執行個體的主機名稱。USER_NAME:用於資料庫連線的使用者名稱,使用者必須具備需求條件一節中詳述的存取權。PRIVATE_KEY_PATH:用於驗證的 RSA 私密金鑰路徑。PRIVATE_KEY_PASSWORD:(選用) 建立 RSA 私密金鑰時使用的密碼。只有在私密金鑰經過加密時才需要。ROLE_NAME:(選用,但強烈建議) 執行dwh-migration-dumper工具時的使用者角色,例如ACCOUNTADMIN。如果預設角色具有足夠的權限,技術上可以省略這個步驟,但指定角色可確保工作階段有權存取SNOWFLAKE.ACCOUNT_USAGE架構。- :用於執行傾印作業的倉庫。如果您有多個虛擬倉庫,可以指定任何倉庫來執行這項查詢。使用需求條件一節中詳述的存取權限執行這項查詢,即可擷取這個帳戶中的所有倉庫構件。
WAREHOUSE STARTING_DATE:(選用) 用於指出查詢記錄日期範圍的開始日期,格式為YYYY-MM-DD。ENDING_DATE:(選用) 用於指出查詢記錄日期範圍的結束日期,格式為YYYY-MM-DD。
您也可以產生多個 ZIP 檔案,內含涵蓋不重疊時間範圍的查詢記錄,並提供所有檔案以供評估。
Hadoop / Cloudera
如要尋求支援或針對這項功能提供意見回饋,請傳送電子郵件至 bq-edw-migration-support@google.com。
需求條件
如要從 Cloudera 擷取中繼資料,您必須具備下列條件:
- 可連線至 Cloudera Manager API 的機器。
- Cloud de Confiance by S3NS 帳戶,並具備 Cloud Storage bucket 來儲存資料。
- 用於儲存結果的空白 BigQuery 資料集。或者,您也可以在建立評估作業時建立 BigQuery 資料集。
執行 dwh-migration-dumper 工具
在指令列環境中,確認 zip 檔案是否正確:
sha256sum --check SHA256SUMS.txt
如要瞭解如何使用
dwh-migration-dumper工具,請參閱「產生翻譯和評估的中繼資料」。使用
dwh-migration-dumper工具將中繼資料和成效統計資料擷取至 zip 檔案:dwh-migration-dumper \ --connector cloudera-manager \ --user USER_NAME \ --password PASSWORD \ --url URL_PATH \ --yarn-application-types "APP_TYPES" \ --spark-history-service-names "SPARK_HISTORY_SERVICE_NAMES" \ --pagination-page-size PAGE_SIZE \ --start-date START_DATE \ --end-date END_DATE \ --assessment
更改下列內容:
USER_NAME:要連線至 Cloudera Manager 執行個體的使用者名稱。PASSWORD:Cloudera Manager 執行個體的密碼。URL_PATH:Cloudera Manager API 的網址路徑,例如https://localhost:7183/api/v55/。APP_TYPES(選用):以半形逗號分隔的 YARN 應用程式類型,這些類型會從叢集傾印。預設值為MAPREDUCE,SPARK,Oozie Launcher。SPARK_HISTORY_SERVICE_NAMES(選用):以半形逗號分隔的 Spark 記錄伺服器服務名稱清單,用於透過 Apache Knox 查詢 Spark 事件記錄,以擷取應用程式中繼資料。如果未提供,預設值為sparkhistory,spark3history。PAGE_SIZE(選用):每個 Cloudera 回應的記錄數。預設值為1000。START_DATE(選用):歷史記錄傾印的開始日期,採用 ISO 8601 格式,例如2025-05-29。預設值為目前日期前 90 天。END_DATE(選用):歷史記錄傾印的結束日期,格式為 ISO 8601,例如2025-05-30。預設值為目前日期。
在 Cloudera 叢集中使用 Oozie
如果您在 Cloudera 叢集中使用 Oozie,可以透過 Oozie 連接器傾印 Oozie 工作記錄。您可以使用 Oozie 搭配 Kerberos 驗證或基本驗證。
如要進行 Kerberos 驗證,請執行下列指令:
kinit dwh-migration-dumper \ --connector oozie \ --url URL_PATH \ --assessment
更改下列內容:
URL_PATH(選用):Oozie 伺服器網址路徑。如果未指定網址路徑,系統會從OOZIE_URL環境變數取得。
如要進行基本驗證,請執行下列指令:
dwh-migration-dumper \ --connector oozie \ --user USER_NAME \ --password PASSWORD \ --url URL_PATH \ --assessment
更改下列內容:
USER_NAME:Oozie 使用者的名稱。PASSWORD:使用者密碼。URL_PATH(選用):Oozie 伺服器網址路徑。如果未指定網址路徑,系統會從OOZIE_URL環境變數取得。
在 Cloudera 叢集中使用 Airflow
如果您在 Cloudera 叢集中使用 Airflow,可以透過 Airflow 連接器傾印 DAG 記錄:
dwh-migration-dumper \ --connector airflow \ --user USER_NAME \ --password PASSWORD \ --url URL \ --driver "DRIVER_PATH" \ --start-date START_DATE \ --end-date END_DATE \ --assessment
更改下列內容:
USER_NAME:Airflow 使用者的名稱PASSWORD:使用者密碼URL:Airflow 資料庫的 JDBC 字串DRIVER_PATH:JDBC 驅動程式的路徑START_DATE(選用):歷史記錄傾印的開始日期,採用 ISO 8601 格式END_DATE(選用):歷史記錄傾印的結束日期,採用 ISO 8601 格式
在 Cloudera 叢集中使用 Hive
如要使用 Hive 連接器,請參閱「Apache Hive」分頁。
Teradata
需求條件
- 連線至來源 Teradata 資料倉儲的機器 (支援 Teradata 15 以上版本)
- 具有 Cloud Storage bucket 的帳戶,可儲存資料 Cloud de Confiance by S3NS
- 用於儲存結果的空白 BigQuery 資料集
- 擁有資料集的讀取權限,即可查看結果
- 建議:使用擷取工具存取系統資料表時,具備來源資料庫的管理員層級存取權
必要條件:啟用記錄功能
dwh-migration-dumper 工具會擷取三種記錄:查詢記錄、公用程式記錄和資源用量記錄。您必須啟用下列記錄類型的記錄功能,才能查看更深入的洞察資料:
- 查詢記錄:從檢視畫面
dbc.QryLogV和資料表dbc.DBQLSqlTbl擷取。如要啟用記錄功能,請指定WITH SQL選項。 - 公用程式記錄:從表格
dbc.DBQLUtilityTbl中擷取。指定WITH UTILITYINFO選項,啟用記錄功能。 - 資源用量記錄:從
dbc.ResUsageScpu和dbc.ResUsageSpma資料表擷取。啟用這兩個資料表的 RSS 記錄。
執行 dwh-migration-dumper 工具
下載 SHA256SUMS.txt 檔案,然後執行下列指令,確認 zip 檔案是否正確:
Bash
sha256sum --check SHA256SUMS.txt
Windows PowerShell
(Get-FileHash RELEASE_ZIP_FILENAME).Hash -eq ((Get-Content SHA256SUMS.txt) -Split " ")[0]
將 RELEASE_ZIP_FILENAME 替換為 dwh-migration-dumper 指令列擷取工具發布版本的下載 ZIP 檔案名稱,例如 dwh-migration-tools-v1.0.52.zip
True 結果會確認總和檢查碼驗證是否成功。
False 結果表示驗證錯誤。請確認總和檢查碼和 ZIP 檔案是從相同發布版本下載,並放在相同目錄中。
如要瞭解如何設定及使用擷取工具,請參閱「產生翻譯和評估用的中繼資料」。
使用擷取工具從 Teradata 資料倉儲擷取記錄和中繼資料,並儲存為兩個 ZIP 檔案。在可存取來源資料倉儲的機器上執行下列指令,產生檔案。
產生中繼資料 ZIP 檔案:
dwh-migration-dumper \ --connector teradata \ --database DATABASES \ --driver path/terajdbc4.jar \ --host HOST \ --assessment \ --user USER \ --password PASSWORD
注意:--database 標記是 teradata 連接器的選用項目。如果省略,系統會擷取所有資料庫的中繼資料。這個標記僅適用於 teradata 連接器,無法與 teradata-logs 搭配使用。
產生包含查詢記錄的 ZIP 檔案:
dwh-migration-dumper \ --connector teradata-logs \ --driver path/terajdbc4.jar \ --host HOST \ --assessment \ --user USER \ --password PASSWORD
注意:使用 teradata-logs 連接器擷取查詢記錄時,不會使用 --database 旗標。系統一律會擷取所有資料庫的查詢記錄。
更改下列內容:
PATH:要用於這個連線的驅動程式 JAR 檔案絕對或相對路徑VERSION:驅動程式版本HOST:主機位址USER:用於資料庫連線的使用者名稱DATABASES:(選用) 以逗號分隔的清單,列出要擷取的資料庫名稱。如未提供,系統會擷取所有資料庫。PASSWORD:(選用) 用於資料庫連線的密碼。如果留空,系統會提示使用者輸入密碼。
根據預設,系統會從檢視區塊 dbc.QryLogV 和資料表 dbc.DBQLSqlTbl 中擷取查詢記錄。如要從其他位置擷取查詢記錄,可以使用 -Dteradata-logs.query-logs-table 和 -Dteradata-logs.sql-logs-table 旗標指定資料表或檢視區塊的名稱。
根據預設,公用程式記錄檔會從表格 dbc.DBQLUtilityTbl 中擷取。如要從其他位置擷取公用程式記錄,可以使用 -Dteradata-logs.utility-logs-table 旗標指定資料表名稱。
根據預設,資源用量記錄檔會從 dbc.ResUsageScpu 和 dbc.ResUsageSpma 資料表擷取。如要從其他位置擷取資源用量記錄,可以使用 -Dteradata-logs.res-usage-scpu-table 和 -Dteradata-logs.res-usage-spma-table 旗標指定表格名稱。
例如:
Bash
dwh-migration-dumper \ --connector teradata-logs \ --driver path/terajdbc4.jar \ --host HOST \ --assessment \ --user USER \ --password PASSWORD \ -Dteradata-logs.query-logs-table=pdcrdata.QryLogV_hst \ -Dteradata-logs.sql-logs-table=pdcrdata.DBQLSqlTbl_hst \ -Dteradata-logs.log-date-column=LogDate \ -Dteradata-logs.utility-logs-table=pdcrdata.DBQLUtilityTbl_hst \ -Dteradata-logs.res-usage-scpu-table=pdcrdata.ResUsageScpu_hst \ -Dteradata-logs.res-usage-spma-table=pdcrdata.ResUsageSpma_hst
Windows PowerShell
dwh-migration-dumper ` --connector teradata-logs ` --driver path\terajdbc4.jar ` --host HOST ` --assessment ` --user USER ` --password PASSWORD ` "-Dteradata-logs.query-logs-table=pdcrdata.QryLogV_hst" ` "-Dteradata-logs.sql-logs-table=pdcrdata.DBQLSqlTbl_hst" ` "-Dteradata-logs.log-date-column=LogDate" ` "-Dteradata-logs.utility-logs-table=pdcrdata.DBQLUtilityTbl_hst" ` "-Dteradata-logs.res-usage-scpu-table=pdcrdata.ResUsageScpu_hst" ` "-Dteradata-logs.res-usage-spma-table=pdcrdata.ResUsageSpma_hst"
根據預設,dwh-migration-dumper工具會擷取過去七天的查詢記錄。Google 建議您提供至少兩週的查詢記錄,以便查看更詳盡的洞察資料。您可以使用 --query-log-start 和 --query-log-end 標記指定自訂時間範圍。例如:
dwh-migration-dumper \ --connector teradata-logs \ --driver path/terajdbc4.jar \ --host HOST \ --assessment \ --user USER \ --password PASSWORD \ --query-log-start "2023-01-01 00:00:00" \ --query-log-end "2023-01-15 00:00:00"
您也可以產生多個 ZIP 檔案,內含不同時間範圍的查詢記錄,並全數提供給我們進行評估。
Redshift
需求條件
- 已連線至來源 Amazon Redshift 資料倉儲的機器
- 具有 Cloud Storage bucket 的帳戶,可儲存資料 Cloud de Confiance by S3NS
- 用於儲存結果的空白 BigQuery 資料集
- 擁有資料集的讀取權限,即可查看結果
- 建議:使用擷取工具存取系統資料表時,應具備資料庫超級使用者存取權
執行 dwh-migration-dumper 工具
下載 dwh-migration-dumper 指令列擷取工具。
下載 SHA256SUMS.txt 檔案,然後執行下列指令,確認 zip 檔案是否正確:
Bash
sha256sum --check SHA256SUMS.txt
Windows PowerShell
(Get-FileHash RELEASE_ZIP_FILENAME).Hash -eq ((Get-Content SHA256SUMS.txt) -Split " ")[0]
將 RELEASE_ZIP_FILENAME 替換為 dwh-migration-dumper 指令列擷取工具發布版本的下載 ZIP 檔案名稱,例如 dwh-migration-tools-v1.0.52.zip
True 結果會確認總和檢查碼驗證是否成功。
False 結果表示驗證錯誤。請確認總和檢查碼和 ZIP 檔案是從相同發布版本下載,並放在相同目錄中。
如要進一步瞭解如何使用 dwh-migration-dumper 工具,請參閱「產生中繼資料」頁面。
使用 dwh-migration-dumper 工具,從 Amazon Redshift 資料倉儲擷取記錄和中繼資料,並以兩個 zip 檔案的形式儲存。在可存取來源資料倉儲的機器上執行下列指令,產生檔案。
產生中繼資料 ZIP 檔案:
dwh-migration-dumper \ --connector redshift \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME
產生包含查詢記錄的 ZIP 檔案:
dwh-migration-dumper \ --connector redshift-raw-logs \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME
更改下列內容:
DATABASE:要連線的資料庫名稱PATH:要用於這個連線的驅動程式 JAR 檔案絕對或相對路徑VERSION:驅動程式版本USER:用於資料庫連線的使用者名稱- :Amazon Redshift IAM 設定檔名稱。這是 Amazon Redshift 驗證和 AWS API 存取權的必要條件。如要取得 Amazon Redshift 叢集的說明,請使用 AWS API。
IAM_PROFILE_NAME
根據預設,Amazon Redshift 會儲存三到五天的查詢記錄。
根據預設,dwh-migration-dumper工具會擷取過去 7 天的查詢記錄。
Google 建議您提供至少兩週的查詢記錄,以便查看更詳盡的洞察資料。您可能需要在兩週內執行幾次擷取工具,才能獲得最佳結果。您可以使用 --query-log-start 和 --query-log-end 旗標指定自訂範圍。例如:
dwh-migration-dumper \ --connector redshift-raw-logs \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME \ --query-log-start "2023-01-01 00:00:00" \ --query-log-end "2023-01-02 00:00:00"
您也可以產生多個 ZIP 檔案,內含不同時間範圍的查詢記錄,並全數提供給我們進行評估。
Redshift Serverless
需求條件
- 連線至來源 Amazon Redshift Serverless 資料倉儲的機器
- 具有 Cloud Storage bucket 的帳戶,可儲存資料 Cloud de Confiance by S3NS
- 用於儲存結果的空白 BigQuery 資料集
- 擁有資料集的讀取權限,即可查看結果
- 建議:使用擷取工具存取系統資料表時,應具備資料庫超級使用者存取權
執行 dwh-migration-dumper 工具
下載 dwh-migration-dumper 指令列擷取工具。
如要瞭解如何使用 dwh-migration-dumper 工具,請參閱「產生中繼資料」頁面。
使用 dwh-migration-dumper 工具,從 Amazon Redshift Serverless 命名空間擷取用量記錄和中繼資料,並以兩個 ZIP 檔案的形式儲存。在可存取來源資料倉儲的機器上執行下列指令,產生檔案。
產生中繼資料 ZIP 檔案:
dwh-migration-dumper \ --connector redshift \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift-serverless.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME
產生包含查詢記錄的 ZIP 檔案:
dwh-migration-dumper \ --connector redshift-serverless-logs \ --database DATABASE \ --driver PATH/redshift-jdbc42-VERSION.jar \ --host host.region.redshift-serverless.amazonaws.com \ --assessment \ --user USER \ --iam-profile IAM_PROFILE_NAME
更改下列內容:
DATABASE:要連線的資料庫名稱PATH:要用於這個連線的驅動程式 JAR 檔案絕對或相對路徑VERSION:驅動程式版本USER:用於資料庫連線的使用者名稱- :Amazon Redshift IAM 設定檔名稱。這是 Amazon Redshift 驗證和 AWS API 存取權的必要條件。如要取得 Amazon Redshift 叢集的說明,請使用 AWS API。
IAM_PROFILE_NAME
Amazon Redshift Serverless 會儲存七天的用量記錄。如需更廣泛的範圍,Google 建議在較長的時間內多次擷取資料。
Oracle / Oracle Exadata
如要尋求支援或針對這項功能提供意見回饋,請傳送電子郵件至 bq-edw-migration-support@google.com。
需求條件
如要從 Oracle 和 Oracle Exadata 擷取中繼資料和查詢記錄,必須符合下列條件:
- Oracle 資料庫必須為 11g R1 以上版本。
- 可連線至 Oracle 執行個體的機器。
- Java 8 以上版本。
- Cloud de Confiance by S3NS 帳戶,並具備 Cloud Storage bucket 來儲存資料。
- 用於儲存結果的空白 BigQuery 資料集。或者,您也可以使用 Cloud de Confiance 控制台 UI 建立評估工作時,一併建立 BigQuery 資料集。
- 具有 SYSDBA 權限的 Oracle 一般使用者。
執行 dwh-migration-dumper 工具
下載 dwh-migration-dumper 指令列擷取工具。
下載 SHA256SUMS.txt 檔案,然後執行下列指令,確認 zip 檔案是否正確:
sha256sum --check SHA256SUMS.txt
如要進一步瞭解如何使用 dwh-migration-dumper 工具,請參閱「產生中繼資料」頁面。
使用 dwh-migration-dumper 工具將中繼資料和效能統計資料擷取至 ZIP 檔案。根據預設,系統會從 Oracle AWR 擷取統計資料,這需要 Oracle Tuning and Diagnostics Pack。如果沒有這類資料,dwh-migration-dumper 會改用 STATSPACK。oracle-stats 連接器也支援 Oracle Exadata。
如果是多租戶資料庫,則必須在根容器中執行 dwh-migration-dumper 工具。在可插入式資料庫中執行工具,會導致其他可插入式資料庫的效能統計資料和中繼資料遺失。
產生中繼資料 ZIP 檔案:
dwh-migration-dumper \ --connector oracle-stats \ --host HOST_NAME \ --port PORT \ --oracle-service SERVICE_NAME \ --assessment \ --driver JDBC_DRIVER_PATH \ --user USER_NAME \ --password
更改下列內容:
HOST_NAME:Oracle 執行個體的主機名稱。PORT:連線通訊埠號碼。預設值為 1521。SERVICE_NAME:用於連線的 Oracle 服務名稱。- :驅動程式 JAR 檔案的絕對或相對路徑。您可以從「Oracle JDBC driver downloads」頁面下載這個檔案。請選取與資料庫版本相容的驅動程式版本。
JDBC_DRIVER_PATH USER_NAME:用於連線至 Oracle 執行個體的使用者名稱。使用者必須具備需求章節中詳述的存取權。
Apache Hive
需求條件
- 連線至來源 Apache Hive 資料倉儲的機器 (BigQuery 遷移評估支援 Hive on Tez 和 MapReduce,以及介於 2.2 和 3.1 之間的 Apache Hive 版本,包括 2.2 和 3.1)
- 具有 Cloud Storage bucket 的帳戶,可儲存資料 Cloud de Confiance by S3NS
- 用於儲存結果的空白 BigQuery 資料集
- 擁有資料集的讀取權限,即可查看結果
- 存取來源 Apache Hive 資料倉儲,設定查詢記錄擷取作業
- 最新的資料表、分區和資料欄統計資料
BigQuery 遷移評估會使用資料表、分區和資料欄統計資料,進一步瞭解 Apache Hive 資料倉儲,並提供深入洞察資訊。如果來源 Apache Hive 資料倉儲中的 hive.stats.autogather 設定設為 false,建議您啟用該設定或手動更新統計資料,再執行 dwh-migration-dumper 工具。
執行 dwh-migration-dumper 工具
下載 dwh-migration-dumper 指令列擷取工具。
下載 SHA256SUMS.txt 檔案,然後執行下列指令,確認 zip 檔案是否正確:
Bash
sha256sum --check SHA256SUMS.txt
Windows PowerShell
(Get-FileHash RELEASE_ZIP_FILENAME).Hash -eq ((Get-Content SHA256SUMS.txt) -Split " ")[0]
將 RELEASE_ZIP_FILENAME 替換為 dwh-migration-dumper 指令列擷取工具發布版本的下載 ZIP 檔案名稱,例如 dwh-migration-tools-v1.0.52.zip
True 結果會確認總和檢查碼驗證是否成功。
False 結果表示驗證錯誤。請確認總和檢查碼和 ZIP 檔案是從相同發布版本下載,並放在相同目錄中。
如要瞭解如何使用 dwh-migration-dumper 工具,請參閱「產生翻譯和評估的中繼資料」。
使用 dwh-migration-dumper 工具,從 Hive 資料倉儲產生中繼資料,並壓縮成 ZIP 檔案。
不需驗證
如要產生中繼資料 ZIP 檔案,請在可存取來源資料倉儲的機器上執行下列指令:
dwh-migration-dumper \ --connector hiveql \ --database DATABASES \ --host hive.cluster.host \ --port 9083 \ --assessment
使用 Kerberos 驗證
如要驗證中繼存放區,請以有權存取 Apache Hive 中繼存放區的使用者身分登入,並產生 Kerberos 票證。然後,使用下列指令產生中繼資料 ZIP 檔案:
JAVA_OPTS="-Djavax.security.auth.useSubjectCredsOnly=false" \ dwh-migration-dumper \ --connector hiveql \ --database DATABASES \ --host hive.cluster.host \ --port 9083 \ --hive-kerberos-url PRINCIPAL/HOST \ -Dhiveql.rpc.protection=hadoop.rpc.protection \ --assessment
更改下列內容:
DATABASES:以半形逗號分隔的資料庫名稱清單,列出要擷取的資料庫。如未提供,系統會擷取所有資料庫。PRINCIPAL:票證核發對象的 Kerberos 主體HOST:票證核發對象的 Kerberos 主機名稱hadoop.rpc.protection:簡單驗證與安全層 (SASL) 設定層級的保護品質 (QOP),等於/etc/hadoop/conf/core-site.xml檔案中hadoop.rpc.protection參數的值,且為下列其中一個值:authenticationintegrityprivacy
使用 hadoop-migration-assessment 記錄掛鉤擷取查詢記錄
如要擷取查詢記錄,請按照下列步驟操作:
上傳 hadoop-migration-assessment 記錄掛鉤
下載包含 Hive 記錄檔記錄掛鉤 JAR 檔案的
hadoop-migration-assessment查詢記錄擷取記錄掛鉤。解壓縮 JAR 檔案。
如要稽核這項工具,確保符合法規遵循規定,請查看
hadoop-migration-assessment記錄掛鉤 GitHub 存放區的原始碼,並編譯自己的二進位檔。將 JAR 檔案複製到所有叢集的輔助程式庫資料夾,您打算在這些叢集啟用查詢記錄功能。視供應商而定,您需要在叢集設定中找到輔助程式庫資料夾,並將 JAR 檔案轉移至 Hive 叢集上的輔助程式庫資料夾。
設定
hadoop-migration-assessment記錄掛鉤的設定屬性。視 Hadoop 供應商而定,您需要使用 UI 控制台編輯叢集設定。修改/etc/hive/conf/hive-site.xml檔案,或使用設定管理員套用設定。
設定屬性
如果下列設定鍵已有其他值,請使用半形逗號 (,) 附加設定。如要設定 hadoop-migration-assessment 記錄掛鉤,必須使用下列設定:
hive.exec.failure.hooks:com.google.cloud.bigquery.dwhassessment.hooks.MigrationAssessmentLoggingHookhive.exec.post.hooks:com.google.cloud.bigquery.dwhassessment.hooks.MigrationAssessmentLoggingHookhive.exec.pre.hooks:com.google.cloud.bigquery.dwhassessment.hooks.MigrationAssessmentLoggingHookhive.aux.jars.path:包含記錄掛鉤 JAR 檔案的路徑,例如file://。/HiveMigrationAssessmentQueryLogsHooks_deploy.jar dwhassessment.hook.base-directory:查詢記錄輸出資料夾的路徑。例如:hdfs://tmp/logs/。您也可以設定下列選用設定:
dwhassessment.hook.queue.capacity:查詢事件記錄執行緒的佇列容量。預設值為64。dwhassessment.hook.rollover-interval:執行檔案輪替的頻率。例如:600s。預設值為 3600 秒 (1 小時)。dwhassessment.hook.rollover-eligibility-check-interval:在背景觸發檔案輪替資格檢查的頻率。例如,600s。預設值為 600 秒 (10 分鐘)。
驗證記錄掛鉤
重新啟動 hive-server2 程序後,請執行測試查詢並分析偵錯記錄。您會看到以下訊息:
Logger successfully started, waiting for query events. Log directory is '[dwhassessment.hook.base-directory value]'; rollover interval is '60' minutes; rollover eligibility check is '10' minutes
記錄掛鉤會在設定的資料夾中建立以日期劃分的子資料夾。dwhassessment.hook.rollover-interval 間隔或 hive-server2 程序終止後,含有查詢事件的 Avro 檔案會出現在該資料夾中。您可以在偵錯記錄中尋找類似訊息,查看輪替作業的狀態:
Updated rollover time for logger ID 'my_logger_id' to '2023-12-25T10:15:30'
Performed rollover check for logger ID 'my_logger_id'. Expected rollover time is '2023-12-25T10:15:30'
系統會在指定間隔或日期變更時進行結轉。日期變更時,記錄掛鉤也會為該日期建立新的子資料夾。
Google 建議您提供至少兩週的查詢記錄,以便查看更詳盡的洞察資料。
您也可以從不同的 Hive 叢集產生含有查詢記錄的資料夾,並提供所有資料夾進行單一評估。
Informatica
如要尋求支援或針對這項功能提供意見回饋,請傳送電子郵件至 bq-edw-migration-support@google.com。
需求條件
- 存取 Informatica PowerCenter Repository Manager 用戶端
- Cloud de Confiance by S3NS 帳戶,並具備 Cloud Storage bucket 來儲存資料。
- 用於儲存結果的空白 BigQuery 資料集。或者,您也可以使用 Cloud de Confiance 控制台建立評估工作時,一併建立 BigQuery 資料集。
必要條件:匯出物件檔案
您可以使用 Informatica PowerCenter Repository Manager GUI 匯出物件檔案。詳情請參閱「匯出物件的步驟」。
或者,您也可以執行 pmrep 指令,按照下列步驟匯出物件檔案:
- 執行
pmrep connect指令,連線至存放區:
pmrep connect -r `REPOSITORY_NAME` -d `DOMAIN_NAME` -n `USERNAME` -x `PASSWORD`
更改下列內容:
REPOSITORY_NAME:要連線的存放區名稱DOMAIN_NAME:存放區的網域名稱USERNAME:用於連線至存放區的使用者名稱PASSWORD:使用者名稱的密碼
- 連線至存放區後,請使用
pmrep objectexport指令匯出所需物件:
pmrep objectexport -n `OBJECT_NAME` -o `OBJECT_TYPE` -f `FOLDER_NAME` -u `OUTPUT_FILE_NAME.xml`
更改下列內容:
OBJECT_NAME:要匯出之特定物件的名稱OBJECT_TYPE:指定物件的物件類型FOLDER_NAME:包含要匯出物件的資料夾名稱OUTPUT_FILE_NAME:包含物件資訊的 XML 檔案名稱
將中繼資料和查詢記錄上傳至 Cloud Storage
從資料倉儲擷取中繼資料和查詢記錄後,您可以將檔案上傳至 Cloud Storage bucket,繼續進行遷移評估。
Databricks
如要尋求支援或針對這項功能提供意見回饋,請傳送電子郵件至 bq-edw-migration-support@google.com。
將 ZIP 檔案上傳至 Cloud Storage bucket。如要進一步瞭解如何建立值區,以及將檔案上傳至 Cloud Storage,請參閱「建立值區」和「從檔案系統上傳物件」。
Snowflake
將中繼資料和含有查詢記錄與使用記錄的 ZIP 檔案上傳至 Cloud Storage bucket。將這些檔案上傳至 Cloud Storage 時,必須符合下列規定:
- 元資料 ZIP 檔案中所有檔案的未壓縮大小總和不得超過 50 GB。
- 中繼資料 ZIP 檔案和包含查詢記錄的 ZIP 檔案必須上傳至 Cloud Storage 資料夾。如果您有多個包含不重疊查詢記錄的 ZIP 檔案,可以全部上傳。
- 你必須將所有檔案上傳至同一個 Cloud Storage 資料夾。
- 請務必上傳
dwh-migration-dumper工具輸出的所有中繼資料和查詢記錄 ZIP 檔案。請勿擷取、合併或修改這些檔案。 - 所有查詢記錄檔案的未壓縮大小總和不得超過 5 TB。
Hadoop / Cloudera
如要尋求支援或針對這項功能提供意見回饋,請傳送電子郵件至 bq-edw-migration-support@google.com。
將包含中繼資料和效能統計資料的 ZIP 檔案上傳至 Cloud Storage 值區。根據預設,ZIP 檔案的名稱為 dwh-migration-cloudera-manager-RUN_DATE.zip (例如 dwh-migration-cloudera-manager-20250312T145808.zip),但你可以使用 --output 旗標自訂名稱。ZIP 檔案中所有檔案的未壓縮總大小上限為 50 GB。
如要進一步瞭解如何建立 bucket 並將檔案上傳至 Cloud Storage,請參閱「建立 bucket」和「從檔案系統上傳物件」。
Teradata
將中繼資料和一或多個含有查詢記錄的 ZIP 檔案上傳至 Cloud Storage bucket。如要進一步瞭解如何建立 bucket,以及將檔案上傳至 Cloud Storage,請參閱「建立 bucket」和「從檔案系統上傳物件」。元資料 ZIP 檔案中所有檔案的未壓縮總大小上限為 50 GB。
含有查詢記錄的所有 ZIP 檔案中的項目會分成以下幾類:
- 查詢前置字串為
query_history_的查詢記錄檔案。 - 前置字元為
utility_logs_、dbc.ResUsageScpu_和dbc.ResUsageSpma_的時間序列檔案。
所有查詢記錄檔案的未壓縮總大小上限為 5 TB。所有時間序列檔案的未壓縮總大小上限為 1 TB。
如果查詢記錄封存於其他資料庫,請參閱本節稍早的 -Dteradata-logs.query-logs-table 和 -Dteradata-logs.sql-logs-table 旗標說明,瞭解如何提供查詢記錄的替代位置。
Redshift
將中繼資料和一或多個含有查詢記錄的 ZIP 檔案上傳至 Cloud Storage bucket。如要進一步瞭解如何建立 bucket,以及將檔案上傳至 Cloud Storage,請參閱「建立 bucket」和「從檔案系統上傳物件」。元資料 ZIP 檔案中所有檔案的未壓縮總大小上限為 50 GB。
含有查詢記錄的所有 ZIP 檔案中的項目會分成以下幾類:
- 使用
querytext_和ddltext_前置字串查詢記錄檔。 - 前置字元為
query_queue_info_、wlm_query_和querymetrics_的時間序列檔案。
所有查詢記錄檔案的未壓縮總大小上限為 5 TB。所有時間序列檔案的未壓縮總大小上限為 1 TB。
Redshift Serverless
將中繼資料和一或多個含有查詢記錄的 ZIP 檔案上傳至 Cloud Storage bucket。如要進一步瞭解如何建立 bucket,以及將檔案上傳至 Cloud Storage,請參閱「建立 bucket」和「從檔案系統上傳物件」。
Oracle / Oracle Exadata
如要尋求支援或針對這項功能提供意見回饋,請傳送電子郵件至 bq-edw-migration-support@google.com。
將包含中繼資料和效能統計資料的 ZIP 檔案上傳至 Cloud Storage 值區。ZIP 檔案的預設名稱為 dwh-migration-oracle-stats.zip,但您可以在 --output 旗標中指定名稱,自訂這個檔案。ZIP 檔案內所有檔案的未壓縮總大小上限為 50 GB。
Apache Hive
將中繼資料和含有查詢記錄的資料夾,從一或多個 Hive 叢集上傳至 Cloud Storage 值區。如要進一步瞭解如何建立值區,以及將檔案上傳至 Cloud Storage,請參閱「建立值區」和「從檔案系統上傳物件」。
元資料 ZIP 檔案中所有檔案的未壓縮總大小上限為 50 GB。
您可以使用 Cloud Storage 連接器,將查詢記錄直接複製到 Cloud Storage 資料夾。含有查詢記錄子資料夾的資料夾,必須上傳至與中繼資料 ZIP 檔案相同的 Cloud Storage 資料夾。
查詢記錄資料夾含有以 dwhassessment_ 為前置字元的查詢記錄檔案。所有查詢記錄檔案的未壓縮總大小上限為 5 TB。
Informatica
如要尋求支援或針對這項功能提供意見回饋,請傳送電子郵件至 bq-edw-migration-support@google.com。
將含有 Informatica XML 存放區物件的 zip 檔案上傳至 Cloud Storage 值區。這個 zip 檔案也必須包含 compilerworks-metadata.yaml 檔案,內含下列項目:
product: arguments: "ConnectorArguments{connector=informatica, assessment=true}"
ZIP 檔案中所有檔案的未壓縮總大小上限為 50 GB。
執行 BigQuery 遷移評估
請按照下列步驟執行 BigQuery 遷移評估。這些步驟假設您已按照上一節所述,將中繼資料檔案上傳至 Cloud Storage 值區。
所需權限
如要啟用 BigQuery Migration Service,您需要下列身分與存取權管理 (IAM) 權限:
resourcemanager.projects.getresourcemanager.projects.updateserviceusage.services.enableserviceusage.services.get
如要存取及使用 BigQuery Migration Service,您必須具備專案的下列權限:
bigquerymigration.workflows.createbigquerymigration.workflows.getbigquerymigration.workflows.listbigquerymigration.workflows.deletebigquerymigration.subtasks.getbigquerymigration.subtasks.list
如要執行 BigQuery Migration Service,您需要下列額外權限。
存取 Cloud Storage bucket 的權限,可存取輸入和輸出檔案:
- 來源 Cloud Storage bucket 的
storage.objects.get - 來源 Cloud Storage bucket 的
storage.objects.list - 目標 Cloud Storage bucket 上的
storage.objects.create - 目標 Cloud Storage bucket 上的
storage.objects.delete - 目標 Cloud Storage bucket 上的
storage.objects.update storage.buckets.getstorage.buckets.list
- 來源 Cloud Storage bucket 的
具備讀取及更新 BigQuery 資料集的權限,BigQuery Migration Service 會將結果寫入該資料集:
bigquery.datasets.updatebigquery.datasets.getbigquery.datasets.createbigquery.datasets.deletebigquery.jobs.createbigquery.jobs.deletebigquery.jobs.listbigquery.jobs.updatebigquery.tables.createbigquery.tables.getbigquery.tables.getDatabigquery.tables.listbigquery.tables.updateData
如要與使用者共用數據分析報表,您必須授予下列角色:
roles/bigquery.dataViewerroles/bigquery.jobUser
以下範例說明如何將必要角色授予要與之共用報表的使用者:
gcloud projects add-iam-policy-binding \ PROJECT \ --member=user:REPORT_VIEWER_EMAIL \ --role=roles/bigquery.dataViewer gcloud projects add-iam-policy-binding \ PROJECT \ --member=user:REPORT_VIEWER_EMAIL \ --role=roles/bigquery.jobUser
更改下列內容:
PROJECT:使用者所在的專案REPORT_VIEWER_EMAIL:要與之共用報表的使用者電子郵件地址
為評估建立專案
建議您建立及設定新專案,以執行遷移評估。您可以使用下列指令碼建立新的 Cloud de Confiance by S3NS 專案,並指派所有必要權限和角色,以執行評估:
#!/bin/bash # --- Configuration --- # Replace with your desired project ID, the email of the user that runs # the assessment, and your organization ID. export PROJECT_ID="PROJECT_ID" export ASSESSMENT_RUNNER_EMAIL="RUNNER_EMAIL" export ORGANIZATION_ID="ORGANIZATION_ID" # --- Project Creation --- echo "Creating project: $PROJECT_ID" gcloud projects create $PROJECT_ID --organization=$ORGANIZATION_ID # Set the new project as the default for subsequent gcloud commands gcloud config set project $PROJECT_ID # --- IAM Role Creation --- echo "Creating custom role 'BQMSrole' in project $PROJECT_ID" gcloud iam roles create BQMSrole \ --project=$PROJECT_ID \ --title=BQMSrole \ --permissions=bigquerymigration.subtasks.get,bigquerymigration.subtasks.list,bigquerymigration.workflows.create,bigquerymigration.workflows.get,bigquerymigration.workflows.list,bigquerymigration.workflows.delete,resourcemanager.projects.update,resourcemanager.projects.get,serviceusage.services.enable,serviceusage.services.get,storage.objects.get,storage.objects.list,storage.objects.create,storage.objects.delete,storage.objects.update,bigquery.datasets.get,bigquery.datasets.update,bigquery.datasets.create,bigquery.datasets.delete,bigquery.tables.get,bigquery.tables.create,bigquery.tables.updateData,bigquery.tables.getData,bigquery.tables.list,bigquery.jobs.create,bigquery.jobs.update,bigquery.jobs.list,bigquery.jobs.delete,storage.buckets.list,storage.buckets.get # --- IAM Policy Binding for Assessment Runner --- echo "Granting IAM roles to the assessment runner: $ASSESSMENT_RUNNER_EMAIL" # Grant the custom BQMSrole to the assessment runner user gcloud projects add-iam-policy-binding \ $PROJECT_ID \ --member=user:$ASSESSMENT_RUNNER_EMAIL \ --role=projects/$PROJECT_ID/roles/BQMSrole # Grant the BigQuery Data Viewer role to the assessment runner user gcloud projects add-iam-policy-binding \ $PROJECT_ID \ --member=user:$ASSESSMENT_RUNNER_EMAIL \ --role=roles/bigquery.dataViewer # Grant the BigQuery Job User role to the assessment runner user gcloud projects add-iam-policy-binding \ $PROJECT_ID \ --member=user:$ASSESSMENT_RUNNER_EMAIL \ --role=roles/bigquery.jobUser echo "Project $PROJECT_ID created and configured for BigQuery Migration Assessment." echo "Assessment Runner: $ASSESSMENT_RUNNER_EMAIL"
更改下列內容:
PROJECT_ID:新專案 ID 的名稱RUNNER_EMAIL:執行遷移評估作業的使用者電子郵件地址ORGANIZATION_ID:組織 ID。例如:123456789012
支援的地區
所有 BigQuery 位置都支援 BigQuery 遷移評估功能。如需 BigQuery 位置清單,請參閱「支援的位置」。
事前準備
執行評估前,您必須啟用 BigQuery Migration API,並建立 BigQuery 資料集來儲存評估結果。
啟用 BigQuery Migration API
按照下列步驟啟用 BigQuery Migration API:
前往 Cloud de Confiance 控制台的「BigQuery Migration API」頁面。
按一下「啟用」。
建立評估結果資料集
BigQuery 遷移評估會將評估結果寫入 BigQuery 中的資料表。開始前,請建立資料集來存放這些資料表。分享數據分析報表時,您也必須授予使用者讀取這個資料集的權限。詳情請參閱「向使用者提供報表」。
執行遷移評估
控制台
前往 Cloud de Confiance 控制台的「BigQuery」頁面。
在
Migration下方的導覽選單中,按一下「服務」。按一下「開始評估」。
填寫評估設定對話方塊。
- 在「顯示名稱」部分,輸入可包含英文字母、數字或底線的名稱。這個名稱僅供顯示之用,不一定要是專屬名稱。
- 在「評估資料來源」中,選擇資料倉儲。
- 在「Path to input files」(輸入檔案路徑),輸入包含已解壓縮檔案的 Cloud Storage bucket 路徑。
如要選擇評估結果的儲存方式,請執行下列任一步驟:
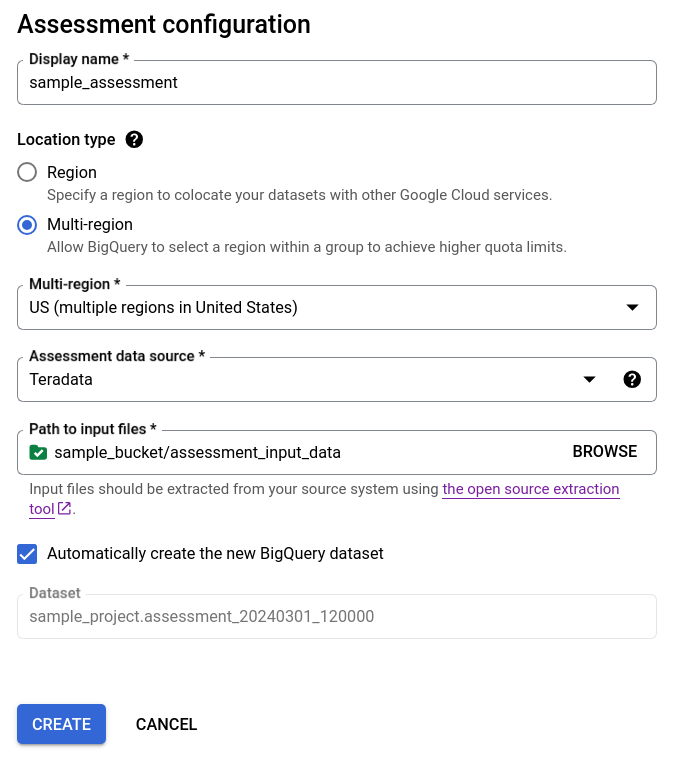
- 請勾選「自動建立新的 BigQuery 資料集」核取方塊,讓系統自動建立 BigQuery 資料集。資料集名稱會自動產生。
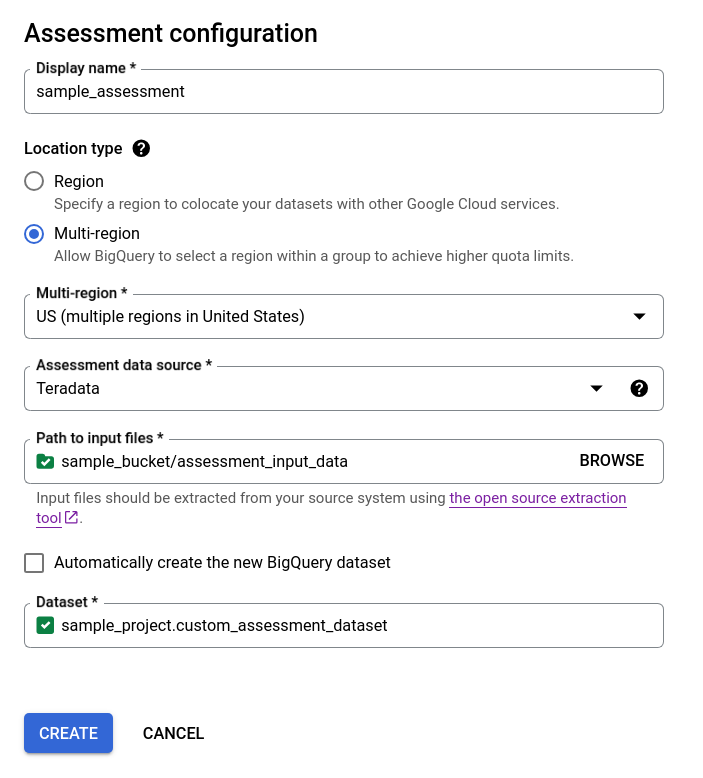
- 取消勾選「自動建立新的 BigQuery 資料集」核取方塊,然後使用
projectId.datasetId格式選擇現有的空白 BigQuery 資料集,或是建立新的資料集名稱。您可以選擇 BigQuery 資料集名稱。
選項 1 - 自動產生 BigQuery 資料集 (預設)
選項 2 - 手動建立 BigQuery 資料集:
點按「Create」(建立)。您可以在評估工作清單中查看工作狀態。
評估作業執行期間,您可以查看狀態圖示的工具提示,瞭解進度和預計完成時間。
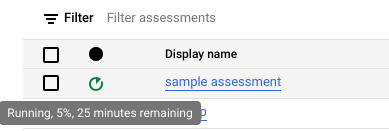
評估作業執行期間,您可以點選評估作業清單中的「查看報表」連結,在「數據分析」中查看含有部分資料的評估報表。評估作業執行期間,可能需要過一段時間才會顯示「查看報表」連結。報表會在新的分頁中開啟。
系統處理新資料時,報表也會隨之更新。重新整理含有報表的分頁,或再次按一下「查看報表」,即可查看更新後的報表。
評估完成後,按一下「查看報表」,即可在數據分析中查看完整評估報告。報告會在新的分頁中開啟。
API
然後呼叫 start 方法,啟動評估工作流程。
評估作業會在您先前建立的 BigQuery 資料集中建立資料表。您可以查詢這些資料,瞭解現有資料倉儲中使用的資料表和查詢。如要瞭解翻譯的輸出檔案,請參閱「批次 SQL 翻譯器」。
可分享的匯總評估結果
如果是 Amazon Redshift、Teradata 和 Snowflake 評估,除了先前建立的 BigQuery 資料集,工作流程還會建立另一個名稱相同但加上 _shareableRedactedAggregate 字尾的輕量資料集。這個資料集包含衍生自輸出資料集的高度匯總資料,且不含個人識別資訊 (PII)。
如要尋找、檢查資料集並安全地與其他使用者共用,請參閱「查詢遷移評估輸出資料表」。
這項功能預設為開啟,但您可以透過公用 API 選擇停用。
評估作業詳細資料
如要查看「評估詳細資料」頁面,請按一下評估作業清單中的顯示名稱。

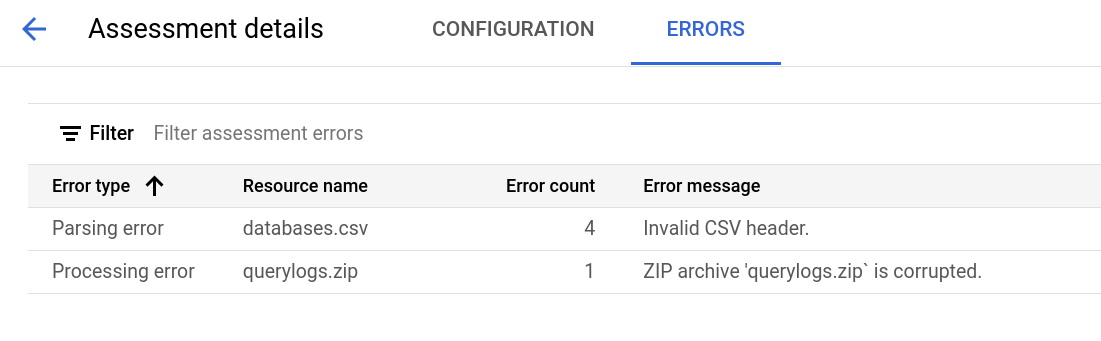
評估詳細資料頁面包含「設定」分頁,您可以在這裡查看評估工作的詳細資訊,以及「錯誤」分頁,您可以在這裡查看評估處理期間發生的任何錯誤。
查看「設定」分頁,瞭解評估作業的屬性。
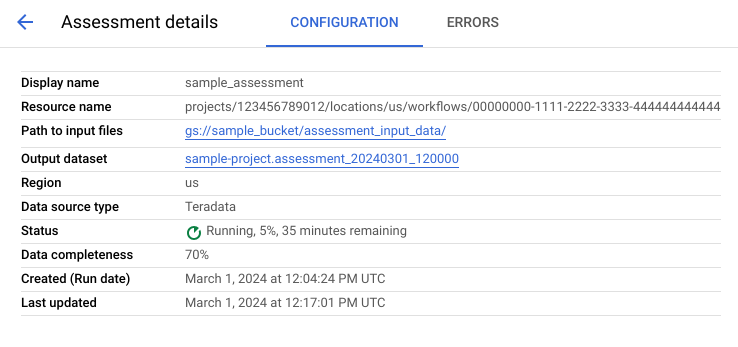
查看「錯誤」分頁,瞭解評估處理期間發生的錯誤。
查看及分享數據分析報表
評估工作完成後,您可以建立並分享結果的數據分析報表。
查看報表
按一下個別評估作業旁邊列出的「查看報告」連結。 系統會在新的分頁中開啟數據分析報表,並進入預覽模式。您可以使用預覽模式查看報表內容,再進一步分享。
報表看起來會像這樣:
如要查看報表包含哪些檢視區塊,請選取資料倉儲:
Snowflake
這份報表包含不同部分,可單獨或一併使用。下圖將這些部分歸類為三種常見的使用者目標,協助您評估遷移需求:
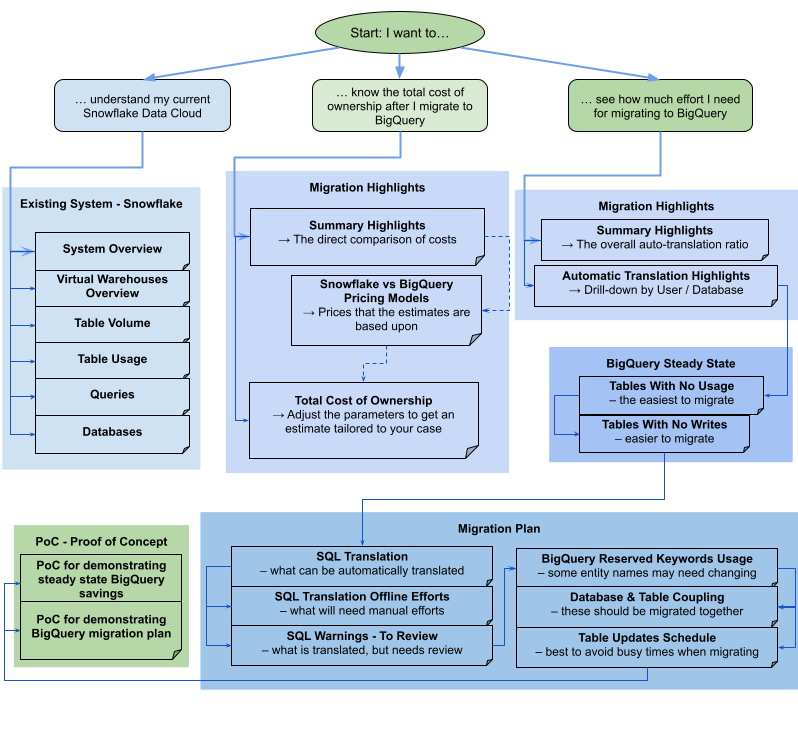
「遷移重點」檢視畫面
「遷移重點」部分包含下列檢視畫面:
- Snowflake 與 BigQuery 的計費模式
- 列出不同等級/版本的價格。此外,這份文件還附上插圖,說明與 Snowflake 相比,BigQuery 自動調度資源功能如何協助您節省更多費用。
- 總持有成本
- 互動式表格,可讓使用者定義:BigQuery 版本、約期、基準配額承諾、有效儲存空間百分比,以及載入或變更的資料百分比。有助於更準確地估算自訂案件的費用。
- 自動翻譯重點
- 匯總翻譯比例,依使用者或資料庫分組,並依升序或降序排序。也包括自動翻譯失敗時最常見的錯誤訊息。
現有系統檢視畫面
「現有系統」部分包含下列檢視畫面:
- 系統總覽
- 「系統總覽」檢視畫面會顯示指定時間範圍內,現有系統中主要元件的概略資料量指標。評估的時間軸取決於 BigQuery 遷移評估分析的記錄。這個檢視畫面可讓您快速瞭解來源資料倉儲的使用情況,有助於規劃遷移作業。
- 虛擬倉儲總覽
- 顯示各倉儲的 Snowflake 費用,以及這段期間內以節點為準的重新調整規模。
- 資料表容量
- 「資料表容量」檢視畫面會提供 BigQuery 遷移評估作業找到的最大資料表和資料庫的統計資料。由於從來源資料倉儲系統擷取大型資料表可能需要較長時間,因此這個檢視畫面有助於規劃及安排遷移順序。
- 資料表用量
- 「資料表用量」檢視畫面會提供統計資料,顯示來源資料倉儲系統中哪些資料表的使用量較高。使用頻率高的資料表可協助您瞭解哪些資料表可能有很多依附元件,且在遷移過程中需要額外規劃。
- 查詢
- 「查詢」檢視畫面會列出執行的 SQL 陳述式類型,以及使用統計資料。您可以根據查詢類型和時間的直方圖,找出系統使用率較低的時段,以及一天中資料移轉的最佳時間。您也可以使用這個檢視畫面,找出經常執行的查詢,以及叫用這些查詢的使用者。
- 資料庫
- 「資料庫」檢視畫面會提供來源資料倉儲系統中定義的大小、資料表、檢視區塊和程序相關指標。這個檢視畫面可深入瞭解需要遷移的物件數量。
BigQuery 穩定狀態檢視畫面
「BigQuery 穩定狀態」部分包含下列檢視畫面:
- 沒有使用情形的資料表
- 「沒有用量的資料表」檢視畫面會顯示 BigQuery 遷移評估在分析記錄期間,找不到任何用量的資料表。這項資訊可指出哪些資料表在遷移期間可能不需要轉移至 BigQuery,或指出在 BigQuery 中儲存資料的成本可能較低。您必須驗證未使用資料表清單,因為這些資料表可能在所分析記錄期間外有使用情形,例如每季或每半年只使用一次的資料表。
- 沒有寫入權的資料表
- 「沒有寫入的資料表」檢視畫面會顯示 BigQuery 遷移評估在分析記錄期間,找不到任何更新的資料表。這可能表示在 BigQuery 中儲存資料的成本較低。
遷移計畫檢視畫面
報表的「遷移計畫」部分包含下列檢視畫面:
- SQL 翻譯
- 「SQL 翻譯」檢視畫面會列出 BigQuery 遷移評估自動轉換的查詢數量和詳細資料,這些查詢不需要手動介入。如果提供中繼資料,自動 SQL 翻譯通常能達到高翻譯率。這個檢視畫面是互動式畫面,可分析常見查詢和這些查詢的翻譯方式。
- SQL 翻譯離線工作
- 「離線工作」檢視畫面會擷取需要手動介入的區域,包括特定 UDF,以及資料表或資料欄可能出現的詞彙結構和語法違規情形。
- SQL 警告 - 待審查
- 「待審查的警告」檢視畫面會顯示大部分已翻譯的區域,但需要專人檢查。
- BigQuery 保留關鍵字
- 「BigQuery 保留字」檢視畫面會顯示偵測到的關鍵字使用情形。這些關鍵字在 GoogleSQL 語言中具有特殊意義,除非以反引號 (
`) 字元括住,否則無法做為 ID。 - 資料庫和資料表耦合
- 「資料庫耦合」檢視畫面會概略顯示在單一查詢中一起存取的資料庫和資料表。這個檢視畫面可顯示經常參照的資料表和資料庫,以及可用於遷移規劃的項目。
- 表格更新時間表
- 「表格更新時間表」檢視畫面會顯示表格的更新時間和頻率,協助您規劃表格的移動時間和方式。
概念驗證檢視畫面
「概念驗證」PoC 區段包含下列檢視畫面:
- PoC,用於展示穩定的 BigQuery 節省金額
- 包括最常執行的查詢、讀取最多資料的查詢、最慢的查詢,以及受上述查詢影響的資料表。
- PoC,用於展示 BigQuery 遷移計畫
- 展示 BigQuery 如何轉譯最複雜的查詢,以及這些查詢影響的資料表。
Teradata
這份報告分為三部分,開頭是摘要重點頁面。該頁面包含下列章節:
- 現有系統。這個部分是現有 Teradata 系統和用量的快照,包括資料庫、結構定義、資料表的數量,以及總大小 (以 TB 為單位)。此外,這個部分也會列出各結構定義的大小,並指出可能未充分利用的資源 (沒有寫入或讀取次數很少的資料表)。
- BigQuery 穩定狀態轉換 (建議)。這個部分會顯示遷移至 BigQuery 後的系統樣貌,包括在 BigQuery 上最佳化工作負載 (並避免浪費) 的建議。
- 遷移計畫。本節提供遷移作業本身的相關資訊,例如從現有系統遷移至 BigQuery 穩定狀態。這個部分會顯示自動翻譯的查詢數量,以及將每個資料表移至 BigQuery 的預計時間。
各節的詳細資料包括:
現有系統
- 運算與查詢
- CPU 使用率:
- 每小時平均 CPU 使用率的熱視圖 (整體系統資源使用率檢視畫面)
- 依小時和日期顯示的查詢,以及 CPU 使用率
- 依類型 (讀取/寫入) 分組的查詢,以及 CPU 使用率
- CPU 使用率的應用程式
- 每小時 CPU 使用率的疊加圖,以及每小時查詢效能和每小時應用程式效能的平均值
- 依類型和查詢時間長度劃分的查詢直方圖
- 應用程式詳細資料檢視畫面 (應用程式、使用者、不重複查詢、報表與 ETL 細目)
- CPU 使用率:
- 儲存空間總覽
- 依資料量、檢視次數和存取率劃分的資料庫
- 資料表,其中包含使用者、查詢、寫入和暫時資料表建立作業的存取率
- 應用程式:存取率和 IP 位址
BigQuery 穩定狀態轉換 (建議)
- 轉換為具體化檢視表的聯結索引
- 根據中繼資料和使用情形將候選人分群和分區
- 識別出適合 BigQuery BI Engine 的低延遲查詢
- 使用資料欄說明功能儲存預設值的資料欄
- Teradata 中的不重複索引 (可防止資料表中的資料列含有不重複的鍵) 會使用暫存資料表和
MERGE陳述式,只將不重複的記錄插入目標資料表,然後捨棄重複項目 - 剩餘查詢和結構定義會照常翻譯
遷移計畫
- 詳細檢視畫面,並自動翻譯查詢
- 查詢總數,可依使用者、應用程式、受影響的資料表、查詢的資料表和查詢類型篩選
- 將具有類似模式的查詢分組並一起顯示,讓使用者能夠依查詢類型查看翻譯原則
- 需要人為介入的查詢
- 查詢違反 BigQuery 詞彙結構的項目
- 使用者定義函式和程序
- BigQuery 保留關鍵字
- 依寫入和讀取作業排定的表格 (可分組移動)
- 使用 BigQuery 資料移轉服務遷移資料: 依資料表估算遷移時間
「現有系統」部分包含下列檢視畫面:
- 系統總覽
- 「系統總覽」檢視畫面會顯示指定時間範圍內,現有系統中主要元件的資料量指標。評估的時間軸取決於 BigQuery 遷移評估分析的記錄檔。這個檢視畫面可讓您快速瞭解來源資料倉儲的使用情況,以利規劃遷移作業。
- 資料表容量
- 「資料表容量」檢視畫面會提供 BigQuery 遷移評估作業找到的最大資料表和資料庫的統計資料。由於從來源資料倉儲系統擷取大型資料表可能需要較長時間,因此這個檢視畫面有助於規劃及排序遷移作業。
- 資料表用量
- 「資料表用量」檢視畫面會提供統計資料,顯示來源資料倉儲系統中哪些資料表的使用量較高。使用頻率高的資料表可協助您瞭解哪些資料表可能有多項依附元件,因此在遷移過程中需要額外規劃。
- 應用程式
- 「應用程式使用情況」和「應用程式模式」檢視畫面會提供記錄處理期間發現的應用程式統計資料。使用者可以透過這些檢視畫面,瞭解特定應用程式在一段時間內的使用情況,以及對資源用量的影響。在遷移期間,請務必將資料的擷取和使用情形視覺化,進一步瞭解資料倉儲的依附元件,並分析一併遷移各種依附應用程式的影響。IP 位址表有助於透過 JDBC 連線,找出使用資料倉儲的確切應用程式。
- 查詢
- 「查詢」檢視畫面會顯示執行的 SQL 陳述式類型,以及使用統計資料。您可以利用查詢類型和時間的直方圖,找出系統使用率較低的時段,以及最適合傳輸資料的時段。您也可以使用這個檢視畫面,找出經常執行的查詢,以及叫用這些執行的使用者。
- 資料庫
- 「資料庫」檢視畫面會提供來源資料倉儲系統中定義的大小、資料表、檢視畫面和程序等指標。這個檢視畫面可讓您瞭解需要遷移的物件數量。
- 資料庫耦合
- 「資料庫耦合」檢視畫面會概略顯示在單一查詢中一起存取的資料庫和資料表。這個檢視畫面會顯示經常參照的資料表和資料庫,以及可用於遷移規劃的項目。
「BigQuery 穩定狀態」部分包含下列檢視畫面:
- 沒有使用情形的資料表
- 「沒有用量的資料表」檢視畫面會顯示 BigQuery 遷移評估在所分析的記錄期間,找不到任何用量的資料表。如果使用量不足,可能表示您不需要在遷移期間將該資料表移轉至 BigQuery,或是將資料儲存在 BigQuery 的費用可能較低。您應驗證未使用的資料表清單,因為這些資料表可能在記錄檔期間外有使用情形,例如每三或六個月只使用一次的資料表。
- 沒有寫入權的資料表
- 「沒有寫入的資料表」檢視畫面會顯示 BigQuery 遷移評估在分析記錄期間,找不到任何更新的資料表。如果寫入次數不足,可能表示您可以在 BigQuery 中降低儲存空間費用。
- 低延遲查詢
- 「低延遲查詢」檢視畫面會根據所分析的記錄資料,顯示查詢執行時間的分佈情況。如果查詢時間分配圖顯示大量查詢的執行時間不到 1 秒,建議啟用 BigQuery BI Engine,加快 BI 和其他低延遲工作負載的運作速度。
- 具體化檢視表
- 具體化檢視表會提供進一步的最佳化建議,提升 BigQuery 的效能。
- 分群和分區
「分區和叢集」檢視畫面會顯示可透過分區、叢集或兩者獲益的資料表。
系統會分析來源資料倉儲結構定義 (例如來源資料表中的分割和主鍵),找出最接近的 BigQuery 對應項目,以達到類似的最佳化特徵,藉此提供中繼資料建議。
系統會分析來源查詢記錄,提供工作負載建議。建議的內容是根據工作負載分析結果決定,尤其是分析查詢記錄中的
WHERE或JOIN子句。- 分群建議
「分區」檢視畫面會根據分區限制定義,顯示可能超過 10,000 個分區的資料表。這些資料表通常很適合進行 BigQuery 叢集處理,可實現精細的分區。
- 唯一性限制
「唯一限制」檢視畫面會顯示來源資料倉儲中定義的
SET資料表和唯一索引。在 BigQuery 中,建議使用暫存資料表和MERGE陳述式,只將不重複的記錄插入目標資料表。您可根據這個檢視畫面中的內容,判斷在遷移期間可能需要調整 ETL 的資料表。- 預設值 / 檢查限制
這個檢視畫面會顯示使用檢查限制條件設定預設資料欄值的資料表。在 BigQuery 中,請參閱「指定預設資料欄值」。
報表的「遷移路徑」部分包含下列檢視畫面:
- SQL 翻譯
- 「SQL 翻譯」檢視畫面會列出 BigQuery 遷移評估自動轉換的查詢數量和詳細資料,這些查詢不需要手動介入。如果提供中繼資料,自動 SQL 翻譯通常能達到高翻譯率。這個檢視畫面是互動式畫面,可分析常見查詢和這些查詢的翻譯方式。
- 離線工作
- 「離線工作」檢視畫面會擷取需要手動介入的區域,包括特定 UDF,以及資料表或資料欄可能出現的詞彙結構和語法違規情形。
- BigQuery 保留關鍵字
- 「BigQuery 保留字」檢視畫面會顯示偵測到的關鍵字使用情形。這些關鍵字在 GoogleSQL 語言中具有特殊意義,除非以反引號 (
`) 字元括住,否則無法做為 ID。 - 表格更新時間表
- 「表格更新時間表」檢視畫面會顯示表格的更新時間和頻率,協助您規劃表格的移動時間和方式。
- 將資料遷移至 BigQuery
- 「資料遷移至 BigQuery」檢視畫面會列出遷移路徑,以及使用 BigQuery 資料移轉服務遷移資料的預估時間。詳情請參閱 BigQuery 資料移轉服務 Teradata 指南。
附錄部分包含下列檢視畫面:
- 區分大小寫
- 「大小寫區分」檢視畫面會顯示來源資料倉儲中設定為執行不區分大小寫比較的資料表。根據預設,BigQuery 中的字串比較會區分大小寫。詳情請參閱「對照」。
Redshift
- 遷移重點
- 「遷移作業重點」檢視畫面提供報告中三個部分的摘要:
- 「現有系統」面板會提供現有 Redshift 系統的資料庫、結構定義、資料表數量,以及總大小等資訊。此外,這項工具也會依大小和潛在的次佳資源使用率列出結構定義。您可以根據這項資訊移除、分割或叢集處理資料表,進而最佳化資料。
- 「BigQuery 穩定狀態」面板會提供資訊,說明資料在遷移至 BigQuery 後的樣貌,包括可使用 BigQuery 遷移服務自動翻譯的查詢數量。這個部分也會根據您的年度資料擷取率,顯示在 BigQuery 中儲存資料的費用,以及資料表、佈建和空間的相關最佳化建議。
- 「遷移路徑」面板會提供遷移作業本身的相關資訊。針對每個資料表,面板會顯示預計遷移時間、資料表中的列數和大小。
「現有系統」部分包含下列檢視畫面:
- 依類型和排程查詢
- 「依類型和排程查詢」檢視畫面會將查詢分為 ETL/寫入和報表/彙整。查看一段時間內的查詢組合,有助於瞭解現有的使用模式,並找出可能影響成本和效能的突發狀況和潛在過度佈建。
- 查詢佇列
- 「查詢排隊」檢視畫面提供系統負載的額外詳細資料,包括查詢量、組合,以及因排隊而造成的任何效能影響,例如資源不足。
- 查詢和 WLM 資源調度
- 「查詢和 WLM 擴充」檢視畫面會將並行擴充視為額外成本和設定複雜度。顯示 Redshift 系統如何根據您指定的規則傳送查詢,以及佇列、並行擴展和遭逐出查詢造成的效能影響。
- 排入佇列並等待
- 「佇列和等待」檢視畫面會深入分析一段時間內查詢的佇列和等待時間。
- WLM 類別和效能
- 「WLM 類別和效能」檢視畫面提供選用方式,可將規則對應至 BigQuery。不過,建議您讓 BigQuery 自動將查詢路徑導向適當位置。
- 查詢和資料表音量洞察
- 「查詢和表格容量洞察」檢視畫面會依大小、頻率和熱門使用者列出查詢。這有助於分類系統負載來源,並規劃如何遷移工作負載。
- 資料庫和結構定義
- 「資料庫和結構定義」檢視畫面會提供來源資料倉儲系統中定義的大小、資料表、檢視畫面和程序相關指標。這有助於瞭解需要遷移的物件數量。
- 資料表容量
- 「資料表容量」檢視畫面會提供最大資料表和資料庫的統計資料,並顯示存取方式。由於從來源資料倉儲系統擷取大型資料表可能需要較長時間,因此這個檢視畫面可協助您規劃及排序遷移作業。
- 資料表用量
- 「資料表用量」檢視畫面會提供統計資料,顯示來源資料倉儲系統中哪些資料表的使用量較高。 您可以利用經常使用的資料表,瞭解可能有很多依附元件的資料表,並在遷移程序中進行額外規劃。
- 匯入工具和匯出工具
- 「匯入者和匯出者」檢視畫面會提供資料和使用者資訊,包括使用
COPY查詢匯入資料,以及使用UNLOAD查詢匯出資料。這個檢視畫面有助於找出與擷取和匯出相關的暫存層和程序。 - 叢集使用率
- 「叢集使用率」檢視畫面會提供所有可用叢集的一般資訊,並顯示每個叢集的 CPU 使用率。這個檢視畫面有助於瞭解系統容量預留量。
「BigQuery 穩定狀態」部分包含下列檢視畫面:
- 叢集與分區
「分區和叢集」檢視畫面會顯示可透過分區、叢集或兩者獲益的資料表。
系統會分析來源資料倉儲結構定義 (例如來源資料表中的排序鍵和分配鍵),找出最接近的 BigQuery 對應項目,以達到類似的最佳化特徵,藉此提供中繼資料建議。
系統會分析來源查詢記錄,系統會分析工作負載,尤其是所分析查詢記錄中的
WHERE或JOIN子句,藉此判斷建議。頁面底部會顯示翻譯後的 CREATE TABLE 陳述式,其中包含所有最佳化項目。您也可以從資料集中擷取所有已翻譯的 DDL 陳述式。翻譯後的 DDL 陳述式會儲存在
SchemaConversion資料表的CreateTableDDL欄中。報表中的建議僅適用於大於 1 GB 的資料表,因為叢集處理和分區處理對小型資料表沒有好處。不過,所有資料表 (包括小於 1 GB 的資料表) 的 DDL 都可在
SchemaConversion資料表中找到。- 沒有使用情形的資料表
「沒有用量的資料表」檢視畫面會顯示 BigQuery 遷移評估在分析記錄檔期間未偵測到任何用量的資料表。如果沒有用量,可能表示您不需要在遷移期間將該資料表移轉至 BigQuery,或是將資料儲存在 BigQuery 中的費用可能較低 (以長期儲存空間計費)。建議您驗證未使用的資料表清單,因為這些資料表可能在記錄檔期間外有用量,例如每三或六個月只使用一次的資料表。
- 沒有寫入權的資料表
「沒有寫入的資料表」檢視畫面會顯示 BigQuery 遷移評估在分析記錄期間,未偵測到任何更新的資料表。如果寫入次數不足,可能表示您可以在 BigQuery 中降低儲存空間費用 (計費方式為長期儲存空間)。
- BigQuery BI Engine 和具體化檢視表
BigQuery BI Engine 和具體化檢視表會提供進一步的最佳化建議,以提升 BigQuery 的效能。
「遷移路徑」部分包含下列檢視畫面:
- SQL 翻譯
- 「SQL 翻譯」檢視畫面會列出 BigQuery 遷移評估自動轉換的查詢數量和詳細資料,這些查詢不需要手動介入。如果提供中繼資料,自動 SQL 翻譯功能通常能達到高翻譯率。
- SQL 翻譯離線工作
- 「SQL 翻譯離線工作量」檢視畫面會擷取需要手動介入的區域,包括特定 UDF 和可能出現翻譯歧義的查詢。
- 變更資料表附加支援
- 「Alter Table Append Support」檢視畫面會顯示常見 Redshift SQL 建構的詳細資料,這些建構沒有直接對應的 BigQuery 項目。
- 複製指令支援
- 「複製指令支援」檢視畫面會顯示常見的 Redshift SQL 建構詳細資料,這些建構沒有直接對應的 BigQuery 項目。
- SQL 警告
- 「SQL 警告」檢視畫面會擷取已成功翻譯但需要審查的區域。
- 詞法結構和語法違規
- 「詞法結構和語法違規」檢視畫面會顯示違反 BigQuery 語法的資料欄、資料表、函式和程序名稱。
- BigQuery 保留關鍵字
- 「BigQuery 保留字」檢視畫面會顯示偵測到的關鍵字使用情形。這些關鍵字在 GoogleSQL 語言中具有特殊意義,除非以反引號 (
`) 字元括住,否則無法做為 ID。 - 結構定義耦合
- 「結構定義耦合」檢視畫面提供資料庫、結構定義和資料表的高階檢視畫面,這些項目會一起在單一查詢中存取。這個檢視畫面會顯示經常參照的資料表、結構定義和資料庫,以及可用於遷移規劃的項目。
- 表格更新時間表
- 「表格更新時間表」檢視畫面會顯示表格的更新時間和頻率,協助您規劃表格的遷移時間和方式。
- 資料表規模
- 「資料表規模」檢視畫面會列出欄數最多的資料表。
- 將資料遷移至 BigQuery
- 「資料遷移至 BigQuery」檢視畫面會列出遷移路徑,以及使用 BigQuery Migration Service 資料移轉服務遷移資料的預估時間。詳情請參閱 BigQuery 資料移轉服務 Redshift 指南。
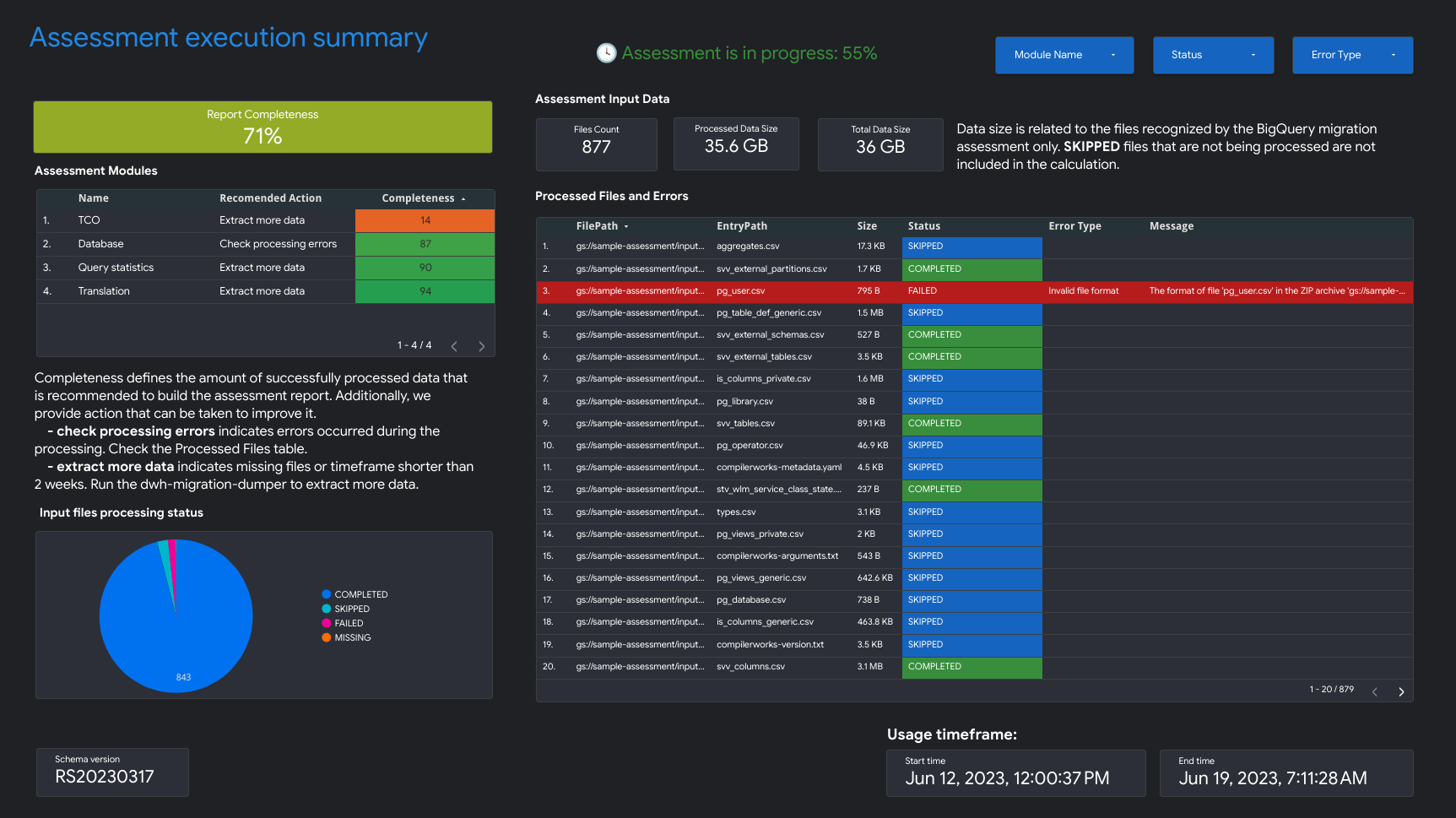
- 評估作業執行摘要
評估執行摘要包含報告完整度、進行中評估的進度,以及已處理檔案和錯誤的狀態。
報表完整度是指成功處理的資料百分比,建議您顯示這些資料,以便在評估報告中提供有意義的洞察資料。如果報表特定部分的資料遺失,這項資訊會列在「報表完整度」指標下方的「評估模組」表格中。
「進度」指標會顯示目前已處理的資料百分比,以及處理所有資料的預估剩餘時間。處理完成後,系統就不會顯示進度指標。
Redshift Serverless
- 遷移重點
- 這個報表頁面會顯示現有 Amazon Redshift 無伺服器資料庫的摘要,包括大小和資料表數量。此外,這項工具還會提供年度合約價值 (ACV) 的高階預估值,也就是 BigQuery 的運算和儲存空間費用。「遷移重點」檢視畫面會提供報告三節的綜合摘要。
「現有系統」部分包含下列檢視畫面:
- 資料庫和結構定義
- 提供每個資料庫、結構定義或資料表的總儲存空間大小 (以 GB 為單位)。
- 外部資料庫和結構定義
- 提供每個外部資料庫、結構定義或資料表的總儲存空間大小 (以 GB 為單位)。
- 系統使用率
- 提供系統使用率的歷史記錄一般資訊。這個檢視畫面會顯示 RPU (Amazon Redshift 處理單元) 的歷史用量,以及每日儲存空間用量。這個檢視畫面可協助您瞭解系統容量預留量。
「BigQuery 穩定狀態」部分提供遷移至 BigQuery 後的資料樣貌資訊,包括可使用 BigQuery 遷移服務自動翻譯的查詢數量。本節也會根據您的年度資料擷取率,顯示將資料儲存在 BigQuery 的費用,以及表格、佈建和空間的相關最佳化建議。「穩定狀態」部分包含下列檢視畫面:
- Amazon Redshift Serverless 與 BigQuery 定價比較
- 比較 Amazon Redshift Serverless 和 BigQuery 的計費模式,協助您瞭解遷移至 BigQuery 後的優點和潛在成本節省。
- BigQuery 運算費用 (總擁有成本)
- 可預估 BigQuery 的運算費用。計算機有四個手動輸入項目:BigQuery 版本、區域、承諾期和基準。根據預設,計算機提供最佳且符合成本效益的基準承諾,您可以手動覆寫。
- 總持有成本
- :可估算年度合約價值 (ACV),也就是 BigQuery 的運算和儲存費用。您也可以使用這項計算工具計算儲存費用,這項費用會因有效儲存空間和長期儲存空間而異,取決於分析期間的資料表修改次數。詳情請參閱「儲存空間定價」。
「附錄」部分包含這個檢視畫面:
- 評估執行摘要
- 提供評估執行詳細資料,包括已處理的檔案清單、錯誤和報告完整性。您可以在這個頁面中調查報表中的遺漏資料,並進一步瞭解報表的完整度。
Oracle / Oracle Exadata
如要尋求支援或針對這項功能提供意見回饋,請傳送電子郵件至 bq-edw-migration-support@google.com。
遷移重點
「遷移重點」部分包含下列檢視畫面:
- 現有系統:現有 Oracle 系統和用量的快照,包括資料庫、結構定義、資料表數量,以及總大小 (以 GB 為單位)。此外,這項工具也會提供每個資料庫的工作負載分類摘要,協助您判斷 BigQuery 是否為合適的遷移目標。
- 相容性:提供遷移作業本身的相關資訊。針對每個分析的資料庫,這項資訊會顯示預計遷移時間,以及可使用 Google 提供的工具自動遷移的資料庫物件數量。
- BigQuery 穩定狀態:包含資料在 BigQuery 遷移後的樣貌資訊,包括根據年度資料擷取率和運算費用估算值,在 BigQuery 中儲存資料的費用。此外,還會提供任何未充分利用的資料表洞察資料。
現有系統
「現有系統」部分包含下列檢視畫面:
- 工作負載特徵:根據分析的效能指標,說明每個資料庫的工作負載類型。每個資料庫都會分類為 OLAP、混合或 OLTP。這項資訊有助於決定要將哪些資料庫遷移至 BigQuery。
- 資料庫和結構定義:提供每個資料庫、結構定義或資料表的總儲存空間大小 (以 GB 為單位) 細目。此外,您也可以使用這個檢視畫面識別具體化檢視畫面和外部資料表。
- 資料庫功能和連結:顯示資料庫中使用的 Oracle 功能清單,以及遷移後可使用的 BigQuery 對等功能或服務。此外,您也可以探索資料庫連結,進一步瞭解資料庫之間的連線。
- 資料庫連線:深入瞭解使用者或應用程式啟動的資料庫工作階段。分析這項資料有助於找出可能需要額外費用的外部應用程式。
- 查詢類型:提供執行的 SQL 陳述式類型細目,以及使用統計資料。您可以利用「查詢執行次數」或「查詢 CPU 作業時間」的小時直方圖,找出系統使用率較低的時段,以及資料傳輸的最佳時間。
- PL/SQL 原始碼:深入瞭解 PL/SQL 物件 (例如函式或程序),以及每個資料庫和結構定義的大小。此外,您也可以使用每小時執行次數直方圖,找出 PL/SQL 執行次數最多的尖峰時段。
- 系統使用率:提供系統使用率的歷史記錄一般資訊。這個檢視畫面會顯示每小時的 CPU 使用量和每日儲存空間用量。這個檢視畫面有助於瞭解系統容量預留空間。
BigQuery 穩定狀態
「BigQuery Steady State」部分包含下列檢視畫面:
- Exadata 與 BigQuery 定價比較:一般而言,Exadata 和 BigQuery 的定價模式各有不同,這份比較表可協助您瞭解遷移至 BigQuery 後的優點和潛在成本節省。
- BigQuery 資料庫讀取/寫入:提供資料庫實體磁碟作業的深入分析資訊。分析這項資料有助於找出從 Oracle 遷移至 BigQuery 的最佳時間。
- BigQuery 運算費用:可預估 BigQuery 的運算費用。計算機中有四項手動輸入項目:BigQuery 版本、區域、承諾期和基準。根據預設,計算機提供最佳的經濟實惠基準承諾,您可以手動覆寫。「年度自動調度運算單元時數」值會顯示承諾使用量以外的運算單元時數用量。這個值是根據系統使用率計算得出。頁面結尾會以視覺化方式說明基準、自動調度資源和使用率之間的關係。每項預估值都會顯示可能的數量和預估範圍。
- 總持有成本 (TCO):可估算年度合約價值 (ACV),也就是 BigQuery 的運算和儲存空間費用。您也可以使用計算機計算儲存空間費用,這項費用會因有效儲存空間和長期儲存空間而異,取決於分析期間的資料表修改次數。如要進一步瞭解儲存空間定價,請參閱儲存空間定價。
- 使用率偏低的資料表:根據所分析時間範圍的用量指標,提供未使用的唯讀資料表相關資訊。如果使用量不足,可能表示您不需要在遷移期間將資料表移轉至 BigQuery,或是將資料儲存在 BigQuery 的費用可能較低 (以長期儲存空間計費)。建議您驗證未使用的資料表清單,確認這些資料表在分析時間範圍外是否曾使用。
遷移提示
「遷移提示」部分包含下列檢視畫面:
- 資料庫物件相容性:提供資料庫物件與 BigQuery 的相容性總覽,包括可透過 Google 提供的工具自動遷移的物件數量,以及需要手動執行的動作。這項資訊會針對每個資料庫、結構定義和資料庫物件類型顯示。
- 資料庫物件遷移工作量:顯示每個資料庫、結構定義或資料庫物件類型的預估遷移工作量 (以小時為單位)。此外,還會根據遷移工作量,顯示小型、中型和大型物件的百分比。
- 資料庫結構定義遷移作業量:提供所有偵測到的資料庫物件類型清單、數量、與 BigQuery 的相容性,以及預估的遷移作業量 (以小時為單位)。
- 資料庫結構定義遷移工作詳細資料:深入探索資料庫結構定義遷移工作,包括每個物件的資訊。
概念驗證檢視畫面
「概念驗證檢視畫面」部分包含下列檢視畫面:
- 概念驗證遷移作業:顯示建議的資料庫清單,這些資料庫的遷移工作量最少,適合初步遷移。此外,這項工具還會顯示最熱門的查詢,協助您透過概念驗證,證明 BigQuery 可節省時間和成本,並帶來價值。
附錄
「附錄」部分包含下列檢視畫面:
- 評估執行摘要:提供評估執行詳細資料,包括處理的檔案清單、錯誤和報告完整度。您可以透過這個頁面調查報表中遺漏的資料,並進一步瞭解整體報表完整度。
Apache Hive
這份報告由三部分組成,開頭是摘要重點頁面,包含下列部分:
現有系統 - Apache Hive。這個部分會提供現有 Apache Hive 系統和使用情況的快照,包括資料庫和資料表的數量、總大小 (以 GB 為單位),以及處理的查詢記錄數量。這個部分也會列出資料庫大小,並指出可能資源使用率偏低 (沒有寫入或讀取次數很少的資料表) 和佈建。這個部分的詳細資料包括:
- 運算和查詢
- CPU 使用率:
- 依小時和日期顯示的查詢,以及 CPU 使用率
- 按類型劃分的查詢 (讀取/寫入)
- 佇列和應用程式
- 每小時 CPU 使用率的疊加圖,以及每小時查詢效能和每小時應用程式效能的平均值
- 依類型和查詢時間長度劃分的查詢直方圖
- 排隊等候頁面
- 佇列詳細資料檢視畫面 (佇列、使用者、不重複查詢、報表與 ETL 細目 (依指標))
- CPU 使用率:
- 儲存空間總覽
- 依資料量、檢視次數和存取率劃分的資料庫
- 資料表,其中包含使用者、查詢、寫入和暫時資料表建立作業的存取率
- 佇列和應用程式:存取率和用戶端 IP 位址
- 運算和查詢
BigQuery 穩定狀態。 本節說明遷移至 BigQuery 後的系統樣貌,並提供建議,協助您在 BigQuery 上最佳化工作負載 (並避免浪費資源)。 本節詳細內容包括:
- 系統識別為具體化檢視表候選項的資料表。
- 根據中繼資料和使用情形,將候選項目分群和分區。
- 系統會將低延遲查詢識別為 BigQuery BI Engine 的候選項目。
- 沒有讀取或寫入用量的資料表。
- 資料偏斜的分區資料表。
遷移計畫:本節提供遷移作業本身的相關資訊,例如從現有系統遷移至 BigQuery 穩定狀態。本節包含每個資料表的已識別儲存目標、已識別為遷移作業重要項目的資料表,以及自動翻譯的查詢數量。本節詳細資料包括:
- 詳細檢視畫面,並自動翻譯查詢
- 查詢總數,可依使用者、應用程式、受影響的資料表、查詢的資料表和查詢類型進行篩選。
- 系統會將模式相似的查詢分組,方便使用者依查詢類型查看翻譯原則。
- 需要人為介入的查詢
- 查詢違反 BigQuery 詞彙結構的項目
- 使用者定義函式和程序
- BigQuery 保留關鍵字
- 需要審查的查詢
- 依寫入和讀取作業排定的表格 (可分組移動)
- 外部和代管資料表的已識別儲存空間目標
- 詳細檢視畫面,並自動翻譯查詢
「現有系統 - Hive」部分包含下列檢視畫面:
- 系統總覽
- 這個檢視畫面會顯示指定時間範圍內,現有系統中主要元件的概略音量指標。評估的時間軸取決於 BigQuery 遷移評估分析的記錄檔。這個檢視畫面可讓您快速瞭解來源資料倉儲的使用情況,以利規劃遷移作業。
- 資料表容量
- 這個檢視畫面會顯示 BigQuery 遷移評估作業找到的最大資料表和資料庫的統計資料。由於從來源資料倉儲系統擷取大型資料表可能需要較長時間,因此這個檢視畫面有助於規劃及排序遷移作業。
- 資料表用量
- 這個檢視畫面會提供統計資料,顯示來源資料倉儲系統中哪些資料表的使用率較高。使用頻率高的資料表可協助您瞭解哪些資料表可能有多項依附元件,因此在遷移過程中需要額外規劃。
- 佇列使用率
- 這個檢視畫面會顯示處理記錄時發現的 YARN 佇列使用情況統計資料。使用者可透過這些檢視畫面,瞭解特定佇列和應用程式的用量變化,以及對資源用量的影響。這些檢視畫面也有助於找出並優先處理要遷移的工作負載。在遷移期間,請務必將資料的擷取和使用情形視覺化,進一步瞭解資料倉儲的依附元件,並分析一併遷移各種依附應用程式的影響。透過 JDBC 連線使用資料倉儲時,IP 位址表有助於精確找出應用程式。
- 佇列指標
- 這個檢視畫面會細分記錄處理期間發現的 YARN 佇列,並顯示不同指標。使用者可透過這個檢視畫面瞭解特定佇列的使用模式,以及對遷移作業的影響。您也可以使用這個檢視畫面,找出查詢中存取的資料表與執行查詢的佇列之間的連線。
- 排入佇列並等待
- 這個檢視畫面可深入瞭解來源資料倉儲中的查詢排隊時間。佇列時間表示因資源配置不足而導致效能下降,而額外資源配置則會增加硬體和維護成本。
- 查詢
- 這個檢視畫面會顯示執行的 SQL 陳述式類型,以及使用統計資料。您可以利用查詢類型和時間的直方圖,找出系統使用率較低的時段,以及最適合傳輸資料的時段。您也可以使用這個檢視畫面,找出最常使用的 Hive 執行引擎、經常執行的查詢,以及使用者詳細資料。
- 資料庫
- 這個檢視畫面會提供來源資料倉儲系統中定義的大小、資料表、檢視表和程序指標。這個檢視畫面可讓您瞭解需要遷移的物件數量。
- 資料庫和資料表耦合
- 這個檢視畫面會顯示在單一查詢中一起存取的資料庫和資料表概況。這個檢視畫面會顯示經常參照的資料表和資料庫,以及可用於遷移規劃的項目。
「BigQuery 穩定狀態」部分包含下列檢視畫面:
- 沒有使用情形的資料表
- 「沒有用量的資料表」檢視畫面會顯示 BigQuery 遷移評估在所分析的記錄期間,找不到任何用量的資料表。如果使用量不足,可能表示您不需要在遷移期間將該資料表移轉至 BigQuery,或是將資料儲存在 BigQuery 的費用可能較低。您必須驗證未使用的資料表清單,因為這些資料表可能在記錄檔期間外有使用情形,例如每三或六個月只使用一次的資料表。
- 沒有寫入權的資料表
- 「沒有寫入的資料表」檢視畫面會顯示 BigQuery 遷移評估在分析記錄期間,找不到任何更新的資料表。如果寫入次數不足,可能表示您可以在 BigQuery 中降低儲存空間費用。
- 分群和分區建議
這個檢視畫面會顯示可透過分區、叢集或兩者兼具的方式提升效能的資料表。
系統會分析來源資料倉儲結構定義 (例如來源資料表中的分割和主鍵),找出最接近的 BigQuery 對應項目,以達到類似的最佳化特徵,藉此提供中繼資料建議。
系統會分析來源查詢記錄,提供工作負載建議。建議的內容是根據工作負載分析結果決定,尤其是分析查詢記錄中的
WHERE或JOIN子句。- 分區已轉換為叢集
這個檢視畫面會根據分區限制定義,顯示超過 10,000 個分區的資料表。這些資料表通常很適合進行 BigQuery 分群,可實現精細的資料表分區。
- 偏斜分區
「傾斜分區」檢視畫面會根據中繼資料分析結果,顯示一或多個分區有資料偏斜的資料表。這些資料表很適合進行結構定義變更,因為查詢傾斜分區時,效能可能不佳。
- BI Engine 和具體化檢視表
「低延遲查詢和具體化檢視表」檢視畫面會根據分析的記錄資料,顯示查詢執行時間的分布情形,並提供進一步的最佳化建議,協助您提升 BigQuery 的效能。如果查詢時間分布圖顯示大量查詢的執行時間不到 1 秒,請考慮啟用 BI Engine,加快 BI 和其他低延遲工作負載的執行速度。
報表的「遷移計畫」部分包含下列檢視畫面:
- SQL 翻譯
- 「SQL 翻譯」檢視畫面會列出 BigQuery 遷移評估自動轉換的查詢數量和詳細資料,這些查詢不需要手動介入。如果提供中繼資料,自動 SQL 翻譯通常能達到高翻譯率。這個檢視畫面是互動式畫面,可分析常見查詢和這些查詢的翻譯方式。
- SQL 翻譯離線工作
- 「離線工作」檢視畫面會擷取需要手動介入的區域,包括特定 UDF,以及資料表或資料欄可能出現的詞彙結構和語法違規情形。
- SQL 警告
- 「SQL 警告」檢視畫面會擷取已成功翻譯但需要審查的區域。
- BigQuery 保留關鍵字
- 「BigQuery 保留關鍵字」檢視畫面會顯示系統偵測到的關鍵字使用情形,這些關鍵字在 GoogleSQL 語言中具有特殊意義。這些關鍵字只有在以倒引號 (
`) 字元括住時才能當成 ID 使用。 - 表格更新時間表
- 「表格更新時間表」檢視畫面會顯示表格的更新時間和頻率,協助您規劃表格的移動時間和方式。
- BigLake 外部資料表
- 「BigLake 外部資料表」檢視畫面會列出已識別為遷移目標的資料表,這些資料表會遷移至 BigLake,而非 BigQuery。
報表的「附錄」部分包含下列檢視畫面:
- 詳細的 SQL 離線翻譯工作分析
- 「詳細離線工作量分析」檢視畫面會提供額外洞察資料,指出需要手動介入的 SQL 區域。
- 詳細分析 SQL 警告
- 「詳細警告分析」檢視畫面會提供額外深入分析,顯示已成功轉換但需要審查的 SQL 區域。
分享報告
數據分析報表是遷移評估的前端資訊主頁。這項功能取決於基礎資料集的存取權限。如要共用報表,收件者必須同時擁有 Google 數據分析報表本身,以及包含評估結果的 BigQuery 資料集存取權。
從 Cloud de Confiance 控制台開啟報表時,您會以預覽模式查看報表。如要建立報表並與其他使用者共用,請按照下列步驟操作:
- 點選「Edit and share」。數據分析會提示您將新建立的數據分析連結器附加至新報表。
- 按一下「加入報表」。每份報告都會收到專屬 ID,您可以使用該 ID 存取報告。
- 如要與其他使用者共用數據分析報表,請按照「與檢視者和編輯者共用報表」一文中的步驟操作。
- 授予使用者權限,讓他們查看用於執行評估工作的 BigQuery 資料集。詳情請參閱「授予資料集存取權」。
查詢遷移評估輸出資料表
雖然數據分析報表是查看評估結果最方便的方式,但您也可以在 BigQuery 資料集中查看及查詢基礎資料。
查詢範例
以下範例會取得不重複查詢總數、翻譯失敗的查詢數量,以及翻譯失敗的不重複查詢百分比。
SELECT QueryCount.v AS QueryCount, ErrorCount.v as ErrorCount, (ErrorCount.v * 100) / QueryCount.v AS FailurePercentage FROM ( SELECT COUNT(*) AS v FROM `your_project.your_dataset.TranslationErrors` WHERE Severity = "ERROR" ) AS ErrorCount, ( SELECT COUNT(DISTINCT(QueryHash)) AS v FROM `your_project.your_dataset.Queries` ) AS QueryCount;
與其他專案的使用者共用資料集
檢查資料集後,如要與專案外的使用者共用,可以利用 BigQuery sharing (舊稱 Analytics Hub) 的發布者工作流程。
前往 Cloud de Confiance 控制台的「BigQuery」頁面。
按一下資料集即可查看詳細資料。
依序點選「分享」>「發布為房源資訊」。
在開啟的對話方塊中,按照提示建立房源資訊。
如果您已有資料交換,請略過步驟 5。
建立資料交換庫並設定權限。如要允許使用者查看這個交換庫中的產品資訊,請將他們新增至「訂閱端」清單。
輸入商家資訊詳細資料。
顯示名稱是這項房源的名稱,為必填欄位;其他欄位為選填。
按一下「發布」。
建立私人房源。
在產品資訊中,選取「動作」下方的「更多動作」。
按一下「複製共用連結」。
您可以將連結提供給有權存取交易所或房源的使用者。
疑難排解
本節說明將資料倉儲遷移至 BigQuery 時的常見問題和疑難排解技巧。
dwh-migration-dumper 項工具錯誤
如要排解中繼資料或查詢記錄擷取期間,dwh-migration-dumper 工具終端機輸出內容中發生的錯誤和警告,請參閱產生中繼資料疑難排解。
Hive 遷移錯誤
本節說明您在規劃將資料倉儲從 Hive 遷移至 BigQuery 時,可能會遇到的常見問題。
記錄掛鉤會在 hive-server2 記錄檔中寫入偵錯記錄訊息。如果遇到任何問題,請查看記錄掛鉤偵錯記錄,其中包含 MigrationAssessmentLoggingHook 字串。
處理 ClassNotFoundException 錯誤
這個錯誤可能是因為記錄掛鉤 JAR 檔案放置位置有誤所致。請確認您已將 JAR 檔案新增至 Hive 叢集上的 auxlib 資料夾。或者,您也可以在 hive.aux.jars.path 屬性中指定 JAR 檔案的完整路徑,例如 file://。
設定的資料夾中不會顯示子資料夾
這個問題可能是因為設定錯誤,或記錄勾點初始化期間發生問題。
在 hive-server2 偵錯記錄中搜尋下列記錄掛鉤訊息:
Unable to initialize logger, logging disabled
Log dir configuration key 'dwhassessment.hook.base-directory' is not set, logging disabled.
Error while trying to set permission
查看問題詳細資料,確認是否需要修正任何內容來解決問題。
資料夾中未顯示檔案
這個問題可能是因為在處理事件或寫入檔案時發生問題所致。
在 hive-server2 偵錯記錄中搜尋下列記錄掛鉤訊息:
Failed to close writer for file
Got exception while processing event
Error writing record for query
查看問題詳細資料,確認是否需要修正任何內容來解決問題。
遺漏部分查詢事件
這個問題可能是因為記錄掛鉤執行緒佇列溢位所致。
在 hive-server2 偵錯記錄中搜尋下列記錄掛鉤訊息:
Writer queue is full. Ignoring event
如有這類訊息,請考慮增加 dwhassessment.hook.queue.capacity 參數。
後續步驟
如要進一步瞭解 dwh-migration-dumper 工具,請參閱
dwh-migration-tools。
您也可以進一步瞭解資料倉儲遷移作業的下列步驟: