
Utiliser des fonctions définies par l'utilisateur dans Python
Une fonction définie par l'utilisateur (UDF) Python vous permet d'implémenter une fonction scalaire en Python et de l'utiliser dans une requête SQL. Les UDF Python sont semblables aux UDF SQL et JavaScript, mais avec des fonctionnalités supplémentaires. Les UDF Python vous permettent d'installer des bibliothèques tierces à partir de l'index de packages Python (PyPI) et d'accéder à des services externes à l'aide d'une connexion à une ressource Cloud.
Les UDF Python sont créées et exécutées sur des ressources gérées par BigQuery.
Limites
python-3.11est le seul environnement d'exécution compatible.- Vous ne pouvez pas créer d'UDF Python temporaire.
- Vous ne pouvez pas utiliser de UDF Python avec une vue matérialisée.
- Les résultats d'une requête qui appelle une UDF Python ne sont pas mis en cache, car la valeur renvoyée par une UDF Python est toujours considérée comme non déterministe.
- Les charges de travail assurées ne sont pas acceptées.
- Les types de données suivants ne sont pas acceptés :
JSON,RANGE,INTERVALetGEOGRAPHY. - Les conteneurs qui exécutent des UDF Python ne peuvent être configurés qu'avec 4 processeurs virtuels et 16 Gio.
- Le chiffrement du code UDF Python avec des clés de chiffrement gérées par le client (CMEK) n'est pas pris en charge.
- Les UDF Python sont compatibles avec VPC Service Controls, mais pas avec les réseaux VPC.
Rôles requis
Les rôles IAM requis dépendent de votre statut (propriétaire ou utilisateur d'une UDF Python).
Propriétaires des UDF
Le propriétaire d'une UDF Python crée ou met à jour une UDF. Des rôles supplémentaires sont également requis si vous créez une UDF Python qui fait référence à une connexion à une ressource cloud.
Cette connexion n'est requise que si votre UDF utilise la clause WITH CONNECTION pour accéder à un service externe.
Pour obtenir les autorisations nécessaires pour créer ou mettre à jour une UDF Python, demandez à votre administrateur de vous accorder les rôles IAM suivants :
- Éditeur de données BigQuery (
roles/bigquery.dataEditor) sur l'ensemble de données - Utilisateur de job BigQuery (
roles/bigquery.jobUser) sur le projet - Administrateur de connexion BigQuery (
roles/bigquery.connectionAdmin) sur le projet
Pour en savoir plus sur l'attribution de rôles, consultez Gérer l'accès aux projets, aux dossiers et aux organisations.
Ces rôles prédéfinis contiennent les autorisations requises pour créer ou mettre à jour une UDF Python. Pour connaître les autorisations exactes requises, développez la section Autorisations requises :
Autorisations requises
Les autorisations suivantes sont requises pour créer ou mettre à jour une UDF Python :
-
Créez une UDF Python à l'aide de l'instruction
CREATE FUNCTION:bigquery.routines.createsur l'ensemble de données. -
Mettez à jour une UDF Python à l'aide de l'instruction
CREATE FUNCTION:bigquery.routines.updatesur l'ensemble de données. -
Exécutez une tâche de requête d'instruction
CREATE FUNCTION:bigquery.jobs.createsur le projet -
Créez une connexion à une ressource Cloud :
bigquery.connections.createsur le projet -
Utilisez une connexion dans l'instruction
CREATE FUNCTION:bigquery.connections.delegatesur la connexion
Vous pouvez également obtenir ces autorisations avec des rôles personnalisés ou d'autres rôles prédéfinis.
Pour en savoir plus sur les rôles dans BigQuery, consultez Rôles IAM prédéfinis.
Utilisateurs UDF
Un utilisateur d'UDF Python appelle une UDF créée par un autre utilisateur. Des rôles supplémentaires sont également requis si vous appelez une UDF Python qui fait référence à une connexion à une ressource Cloud.
Pour obtenir les autorisations nécessaires pour appeler une UDF Python créée par un autre utilisateur, demandez à votre administrateur de vous accorder les rôles IAM suivants :
- Utilisateur BigQuery (
roles/bigquery.user) sur le projet - Lecteur de données BigQuery (
roles/bigquery.dataViewer) sur l'ensemble de données - Utilisateur de connexion BigQuery (
roles/bigquery.connectionUser) sur la connexion
Pour en savoir plus sur l'attribution de rôles, consultez Gérer l'accès aux projets, aux dossiers et aux organisations.
Ces rôles prédéfinis contiennent les autorisations requises pour appeler une UDF Python créée par un autre utilisateur. Pour connaître les autorisations exactes requises, développez la section Autorisations requises :
Autorisations requises
Les autorisations suivantes sont requises pour appeler une UDF Python créée par un autre utilisateur :
-
Pour exécuter un job de requête qui fait référence à une FDU Python :
bigquery.jobs.createsur le projet -
Pour appeler une UDF Python créée par un autre utilisateur :
bigquery.routines.getsur l'ensemble de données -
Pour exécuter une UDF Python qui fait référence à une connexion de ressource Cloud :
bigquery.connections.usesur la connexion
Vous pouvez également obtenir ces autorisations avec des rôles personnalisés ou d'autres rôles prédéfinis.
Pour en savoir plus sur les rôles dans BigQuery, consultez Rôles IAM prédéfinis.
Créer une UDF Python persistante
Lorsque vous créez une UDF Python, respectez les règles suivantes :
Le corps de l'UDF Python doit être une chaîne littérale entre guillemets représentant le code Python. Pour en savoir plus sur les littéraux de chaîne entre guillemets, consultez Formats pour les littéraux entre guillemets.
Le corps de la fonction Python définie par l'utilisateur doit inclure une fonction Python utilisée dans l'argument
entry_pointde la liste des options de la fonction Python définie par l'utilisateur.Une version d'environnement d'exécution Python doit être spécifiée dans l'option
runtime_version. La seule version d'exécution Python compatible estpython-3.11. Pour obtenir la liste complète des options disponibles, consultez la liste des options de fonction pour l'instructionCREATE FUNCTION.
Pour créer une UDF Python persistante, utilisez l'instruction CREATE FUNCTION sans le mot clé TEMP ou TEMPORARY. Pour supprimer une UDF Python persistante, utilisez l'instruction DROP FUNCTION.
Exemple
Pour voir un exemple de création d'une UDF Python persistante, choisissez l'une des options suivantes :
Console
L'exemple suivant crée une fonction Python persistante définie par l'utilisateur nommée multiplyInputs et appelle cette UDF à partir d'une instruction SELECT :
Accédez à la page BigQuery.
Dans l'éditeur de requête, saisissez l'instruction
CREATE FUNCTIONsuivante :CREATE FUNCTION `PROJECT_ID.DATASET_ID`.multiplyInputs(x FLOAT64, y FLOAT64) RETURNS FLOAT64 LANGUAGE python OPTIONS(runtime_version="python-3.11", entry_point="multiply") AS r''' def multiply(x, y): return x * y '''; -- Call the Python UDF. WITH numbers AS (SELECT 1 AS x, 5 as y UNION ALL SELECT 2 AS x, 10 as y UNION ALL SELECT 3 as x, 15 as y) SELECT x, y, `PROJECT_ID.DATASET_ID`.multiplyInputs(x, y) AS product FROM numbers;
Remplacez PROJECT_ID.DATASET_ID avec l'ID de votre projet et l'ID de l'ensemble de données.
Cliquez sur Exécuter.
Cet exemple génère la sortie suivante :
+-----+-----+--------------+ | x | y | product | +-----+-----+--------------+ | 1 | 5 | 5.0 | | 2 | 10 | 20.0 | | 3 | 15 | 45.0 | +-----+-----+--------------+
BigQuery DataFrames
L'exemple suivant utilise BigQuery DataFrames pour transformer une fonction personnalisée en UDF Python :
État de la création du conteneur
Lorsque vous créez une UDF Python à l'aide de l'instruction CREATE FUNCTION, BigQuery crée ou met à jour une image de conteneur basée sur une image de base. Le conteneur est créé sur l'image de base à l'aide de votre code et de toutes les dépendances de package spécifiées.
La création du conteneur est un processus de longue durée. La première requête après l'exécution de l'instruction CREATE FUNCTION attend la fin de la compilation de l'image. S'il n'y a pas de dépendances externes, l'image de conteneur est généralement créée en moins d'une minute.
La taille de tous les conteneurs de fonctions définies par l'utilisateur Python par projet et par région est limitée à un total de 10 Gio. Pour en savoir plus, consultez Limites relatives aux fonctions définies par l'utilisateur persistantes. La compilation de votre conteneur échoue si votre projet a atteint le quota.
Pour afficher l'état de la compilation de votre conteneur, choisissez l'une des options suivantes :
Console
Accédez à la page Studio de BigQuery.
Dans le volet de gauche, développez votre projet, puis cliquez sur Ensembles de données.
Cliquez sur le lien pour ouvrir l'ensemble de données contenant votre UDF Python.
Sur la page de l'ensemble de données, cliquez sur l'onglet Routines.
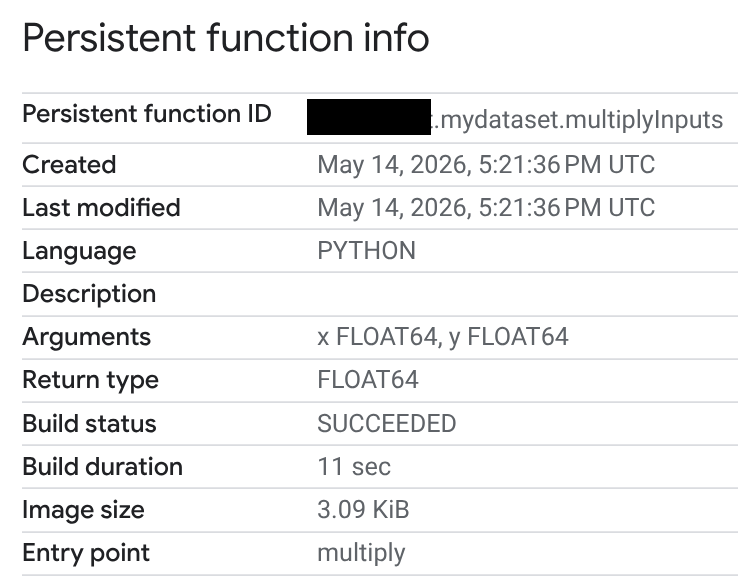
Dans la colonne ID de routine, cliquez sur votre UDF Python.
Sur la page Informations sur les fonctions persistantes, vous pouvez consulter l'état de compilation, la durée de compilation et la taille d'image. L'état de compilation est l'un des suivants :
- En cours
- Réussite
- Échec
Si une compilation échoue, la page d'informations sur la fonction fournit des messages d'erreur détaillés pour vous aider à résoudre les problèmes tels que les erreurs de syntaxe ou les problèmes d'installation de packages externes.
SQL
Pour interroger les champs d'état de compilation dans la vue INFORMATION_SCHEMA.ROUTINES, procédez comme suit :
Accédez à la page Studio de BigQuery.
Passez à l'éditeur de requête ou cliquez sur Requête SQL.
Saisissez la requête suivante pour récupérer les champs
BUILD_STATUSde la vueINFORMATION_SCHEMA.ROUTINES. La colonneBUILD_STATUSest de typeSTRUCTdans GoogleSQL :SELECT build_status.* FROM `PROJECT_ID.DATASET_ID`.INFORMATION_SCHEMA.ROUTINES;Remplacez PROJECT_ID.DATASET_ID avec l'ID de votre projet et l'ID de l'ensemble de données.
Le résultat doit se présenter sous la forme suivante. Les champs d'erreur sont omis :
+---------------+--------------------------------+------------------------+------------------+ | build_state | build_state_update_time | build_duration_seconds | image_size_bytes | +---------------+--------------------------------+------------------------+------------------+ | SUCCEEDED | 2026-05-14 17:21:49.736000 UTC | 11 | 3167 | +---------------+--------------------------------+------------------------+------------------+
API
Affichez l'état de la compilation du conteneur à l'aide de RoutineBuildStatus dans l'API.
Créer une UDF Python vectorisée
Vous pouvez implémenter votre UDF Python pour traiter un lot de lignes au lieu d'une seule ligne en utilisant la vectorisation. La vectorisation peut améliorer les performances des requêtes. Vous pouvez créer une UDF vectorisée à l'aide de Pandas ou d'Apache Arrow.
Pour contrôler le comportement de la mise en lot, spécifiez le nombre maximal de lignes dans chaque lot à l'aide de l'option max_batching_rows dans la liste d'options CREATE OR REPLACE FUNCTION. Si vous spécifiez max_batching_rows, BigQuery détermine le nombre de lignes d'un lot, dans la limite de max_batching_rows.
Si max_batching_rows n'est pas spécifié, le nombre de lignes à regrouper est déterminé automatiquement.
Utiliser Pandas
Une UDF Python vectorisée comporte un seul argument pandas.DataFrame qui doit être annoté. L'argument pandas.DataFrame comporte le même nombre de colonnes que les paramètres UDF Python définis dans l'instruction CREATE FUNCTION. Les noms de colonnes de l'argument pandas.DataFrame sont identiques à ceux des paramètres de la UDF'utilisateur.
Votre fonction doit renvoyer un pandas.Series ou un pandas.DataFrame à une seule colonne avec le même nombre de lignes que l'entrée.
L'exemple suivant crée une UDF Python vectorisée nommée multiplyInputs avec deux paramètres : x et y :
Accédez à la page BigQuery.
Dans l'éditeur de requête, saisissez l'instruction
CREATE FUNCTIONsuivante :CREATE FUNCTION `PROJECT_ID.DATASET_ID`.multiplyVectorized(x FLOAT64, y FLOAT64) RETURNS FLOAT64 LANGUAGE python OPTIONS(runtime_version="python-3.11", entry_point="vectorized_multiply") AS r''' import pandas as pd def vectorized_multiply(df: pd.DataFrame): return df['x'] * df['y'] ''';
Remplacez PROJECT_ID.DATASET_ID avec l'ID de votre projet et l'ID de l'ensemble de données.
L'appel de l'UDF est identique à celui de l'exemple précédent.
Cliquez sur Exécuter.
Utiliser Apache Arrow
L'exemple suivant utilise l'interface RecordBatch Apache Arrow. Lorsque vous utilisez l'interface RecordBatch, la fonction transmet un lot de lignes de colonnes de même longueur au point d'entrée.
L'exemple suivant utilise Apache Arrow pour créer une UDF Python vectorisée nommée multiplyVectorizedArrow.
Accédez à la page BigQuery.
Dans l'éditeur de requête, saisissez l'instruction
CREATE FUNCTIONsuivante :CREATE FUNCTION `PROJECT_ID.DATASET_ID`.multiplyVectorizedArrow(x FLOAT64, y FLOAT64) RETURNS FLOAT64 LANGUAGE python OPTIONS( runtime_version="python-3.11", entry_point="vectorized_multiply_arrow" ) AS r''' import pyarrow as pa import pyarrow.compute as pc def vectorized_multiply_arrow(batch: pa.RecordBatch): # Access columns directly from the Arrow RecordBatch x = batch.column('x') y = batch.column('y') # Use pyarrow.compute for vectorized operations return pc.multiply(x, y) ''';
Remplacez PROJECT_ID.DATASET_ID avec l'ID de votre projet et l'ID de l'ensemble de données.
L'appel de l'UDF est identique à celui des exemples précédents.
Cliquez sur Exécuter.
Appeler une UDF Python
Si vous êtes autorisé à appeler une UDF Python, vous pouvez l'appeler comme n'importe quelle autre fonction. Pour utiliser une fonction définie dans un autre projet, utilisez le nom complet de la fonction. Par exemple, pour appeler une fonction d'extraction XML nommée cw_xml_extract dans un autre projet, procédez comme suit.
Console
Accédez à la page BigQuery.
Dans l'éditeur de requête, saisissez l'exemple suivant :
SELECT `PROJECT_ID.DATASET_ID`.`cw_xml_extract`(xml, '//title/text()') AS `title` FROM UNNEST([ STRUCT('''<book id="1"> <title>The Great Gatsby</title> <author>F. Scott Fitzgerald</author> </book>''' AS xml), STRUCT('''<book id="2"> <title>1984</title> <author>George Orwell</author> </book>''' AS xml), STRUCT('''<book id="3"> <title>Brave New World</title> <author>Aldous Huxley</author> </book>''' AS xml) ])Cliquez sur Exécuter.
Cet exemple génère la sortie suivante :
+--------------------------+ | title | +--------------------------+ | The Great Gatsby | | 1984 | | Brave New World | +--------------------------+
BigQuery DataFrames
L'exemple suivant utilise les méthodes BigQuery DataFrames
sql_scalar, read_gbq_function et apply pour appeler une UDF Python :
Types de données compatibles avec les fonctions Python définies par l'utilisateur
Le tableau suivant définit la correspondance entre les types de données BigQuery, Python et Pandas :
| Type de données BigQuery | Type de données Python intégré utilisé par les UDF standards | Type de données Pandas utilisé par l'UDF vectorisée | Type de données PyArrow utilisé pour ARRAY et STRUCT dans les UDF vectorisées |
|---|---|---|---|
BOOL |
bool |
BooleanDtype |
DataType(bool) |
INT64 |
int |
Int64Dtype |
DataType(int64) |
FLOAT64 |
float |
FloatDtype |
DataType(double) |
STRING |
str |
StringDtype |
DataType(string) |
BYTES |
bytes |
binary[pyarrow] |
DataType(binary) |
TIMESTAMP |
Paramètre de fonction : Valeur renvoyée par la fonction : |
Paramètre de la fonction : Valeur renvoyée par la fonction : |
TimestampType(timestamp[us]), avec fuseau horaire |
DATE |
datetime.date |
date32[pyarrow] |
DataType(date32[day]) |
TIME |
datetime.time |
time64[pyarrow] |
Time64Type(time64[us]) |
DATETIME |
datetime.datetime (sans fuseau horaire) |
timestamp[us][pyarrow] |
TimestampType(timestamp[us]), sans fuseau horaire |
ARRAY |
list |
list<...>[pyarrow], où le type de données de l'élément est pandas.ArrowDtype |
ListType |
STRUCT |
dict |
struct<...>[pyarrow], où le type de données du champ est pandas.ArrowDtype |
StructType |
Versions d'exécution compatibles
Les UDF Python BigQuery sont compatibles avec l'environnement d'exécution python-3.11. Cette version de Python inclut des packages préinstallés supplémentaires. Pour les bibliothèques système, vérifiez l'image de base de l'environnement d'exécution.
| Version d'exécution | Version Python | Inclut |
|---|---|---|
| python-3.11 | Python 3.11 | numpy 1.26.3 pyarrow 14.0.2 pandas 2.1.4 python-dateutil 2.8.2 absl-py 2.0.0 pytz 2023.3.post1 tzdata 2023.4 six 1.16.0 |
Utiliser des packages tiers
Vous pouvez utiliser la liste d'options CREATE FUNCTION pour utiliser des modules autres que ceux fournis par la bibliothèque standard Python et les packages préinstallés.
Vous pouvez installer des packages à partir de l'index de packages Python (PyPI) ou importer des fichiers Python depuis Cloud Storage.
Installer un package à partir de l'index de packages Python
Lorsque vous installez un package, vous devez fournir son nom et vous pouvez éventuellement fournir sa version à l'aide des spécificateurs de version de package Python.
Si le package se trouve dans l'environnement d'exécution, il est utilisé, sauf si une version spécifique est spécifiée dans la liste d'options CREATE FUNCTION. Si aucune version de package n'est spécifiée et que le package n'est pas dans l'environnement d'exécution, la dernière version disponible est utilisée. Seuls les packages au format binaire Wheel sont acceptés.
L'exemple suivant montre comment créer une UDF Python qui installe le package scipy à l'aide de la liste d'options CREATE OR REPLACE FUNCTION :
Accédez à la page BigQuery.
Dans l'éditeur de requête, saisissez l'instruction
CREATE FUNCTIONsuivante :CREATE FUNCTION `PROJECT_ID.DATASET_ID`.area(radius FLOAT64) RETURNS FLOAT64 LANGUAGE python OPTIONS (entry_point='area_handler', runtime_version='python-3.11', packages=['scipy==1.15.3']) AS r""" import scipy def area_handler(radius): return scipy.constants.pi*radius*radius """; SELECT `PROJECT_ID.DATASET_ID`.area(4.5);
Remplacez PROJECT_ID.DATASET_ID avec l'ID de votre projet et l'ID de l'ensemble de données.
Cliquez sur Exécuter.
Importer des fichiers Python supplémentaires en tant que bibliothèques
Vous pouvez étendre vos UDF Python à l'aide de la liste d'options de fonction en important des fichiers Python depuis Cloud Storage.
Dans le code Python de votre UDF, vous pouvez importer les fichiers Python depuis Cloud Storage en tant que modules à l'aide de l'instruction import suivie du chemin d'accès à l'objet Cloud Storage. Par exemple, si vous importez gs://BUCKET_NAME/path/to/lib1.py, votre instruction d'importation sera import
path.to.lib1.
Le nom de fichier Python doit être un identifiant Python. Chaque nom folder dans le nom de l'objet (après /) doit être un identifiant Python valide. Dans la plage ASCII (U+0001..U+007F), les caractères suivants peuvent être utilisés dans les identifiants :
- Lettres majuscules et minuscules de A à Z.
- Tirets du 8.
- Les chiffres de zéro à neuf, mais un chiffre ne peut pas apparaître comme premier caractère de l'identifiant.
L'exemple suivant vous montre comment créer une UDF Python qui importe le package de bibliothèque cliente lib1.py à partir d'un bucket Cloud Storage nommé my_bucket :
Accédez à la page BigQuery.
Dans l'éditeur de requête, saisissez l'instruction
CREATE FUNCTIONsuivante :CREATE FUNCTION `PROJECT_ID.DATASET_ID`.myFunc(a FLOAT64, b STRING) RETURNS STRING LANGUAGE python OPTIONS ( entry_point='compute', runtime_version='python-3.11', library=['gs://BUCKET_NAME/PATH/lib1.py']) AS r""" import path.to.lib1 as lib1 def compute(a, b): # doInterestingStuff is a function defined in # gs://BUCKET_NAME/PATH/lib1.py return lib1.doInterestingStuff(a, b); """;
Remplacez les éléments suivants :
- PROJECT_ID : ID de votre projet.
- DATASET_ID : ID de votre ensemble de données.
- BUCKET_NAME : nom du bucket Cloud Storage contenant
lib1.py. - PATH : chemin d'accès au bucket Cloud Storage.
Cliquez sur Exécuter.
Configurer les limites de conteneur pour les UDF Python
Vous pouvez utiliser la liste d'options CREATE FUNCTION pour spécifier les limites de simultanéité des requêtes de processeur, de mémoire et de conteneur pour les conteneurs qui exécutent des UDF Python.
Par défaut, les conteneurs se voient attribuer les ressources suivantes :
- La mémoire allouée est de
512Mi. - Le nombre de processeurs virtuels alloués est de
1.0. - La limite de simultanéité des requêtes de conteneur est de
80.
L'exemple suivant crée une fonction Python définie par l'utilisateur à l'aide de la liste d'options CREATE FUNCTION pour spécifier les limites du conteneur :
Accédez à la page BigQuery.
Dans l'éditeur de requête, saisissez l'instruction
CREATE FUNCTIONsuivante :CREATE FUNCTION `PROJECT_ID.DATASET_ID`.square_area(length FLOAT64) RETURNS FLOAT64 LANGUAGE python OPTIONS (entry_point='square_area', runtime_version='python-3.11', container_memory='CONTAINER_MEMORY', container_cpu=CONTAINER_CPU, container_request_concurrency=CONTAINER_REQUEST_CONCURRENCY) AS r""" def square_area(length): return length*length """; SELECT `PROJECT_ID.DATASET_ID`.square_area(4.5);
Remplacez les éléments suivants :
- PROJECT_ID.DATASET_ID : ID de votre projet et ID de votre ensemble de données.
- CONTAINER_MEMORY : valeur de la mémoire au format suivant :
<integer_number><unit>. L'unité doit être l'une des valeurs suivantes :Mi(Mio),M(Mo),Gi(Gio) ouG(Go). Par exemple,2Gi. - CONTAINER_CPU : valeur du processeur. Les UDF Python acceptent les valeurs de processeur fractionnaires comprises entre
0.33et1.0, ainsi que les valeurs de processeur non fractionnaires de1,2et4. - CONTAINER_REQUEST_CONCURRENCY : nombre maximal de requêtes simultanées par instance de conteneur UDF Python. La valeur doit être un entier compris entre
1et1000.
Cliquez sur Exécuter.
Valeurs de processeur acceptées
Les UDF Python sont compatibles avec les valeurs de CPU fractionnaires comprises entre 0.33 et 1.0, ainsi qu'avec les valeurs de CPU non fractionnaires de 1, 2 et 4. Les conteneurs qui exécutent des UDF Python peuvent être configurés avec un maximum de 4 vCPU. La valeur par défaut est 1.0. Les valeurs d'entrée fractionnaires sont arrondies à deux décimales avant d'être appliquées au conteneur.
Valeurs de mémoire acceptées
Les conteneurs de fonctions Python définies par l'utilisateur acceptent les valeurs de mémoire au format suivant : <integer_number><unit>. L'unité doit être l'une des valeurs suivantes : Mi, M, Gi ou G. La quantité de mémoire minimale que vous pouvez configurer est de 256Mi. La quantité maximale de mémoire que vous pouvez configurer est de 16Gi.
En fonction de la valeur de mémoire que vous choisissez, vous devez également spécifier une quantité de processeur appropriée. Le tableau suivant indique les valeurs minimales et maximales du processeur pour chaque valeur de mémoire :
| Mémoire | Processeur minimum | Processeur maximal |
|---|---|---|
De 256Mi à 512Mi |
0.33 |
2 |
Supérieur à 512Mi et inférieur ou égal à 1Gi |
0.5 |
2 |
Supérieur à 1Gi et inférieur à 2Gi |
1 |
2 |
De 2Gi à 4Gi |
1 |
4 |
Supérieur à 4Gi et inférieur ou égal à 8Gi |
2 |
4 |
Supérieur à 8Gi et inférieur ou égal à 16Gi |
4 |
4 |
Si vous avez déterminé la quantité de processeur que vous allouez, vous pouvez utiliser le tableau suivant pour déterminer la plage de mémoire appropriée :
| Processeur | Mémoire minimale | Taille maximale de la mémoire |
|---|---|---|
Moins de 0.5 |
256Mi |
512Mi |
0.5 à moins de 1 |
256Mi |
1Gi |
1 |
256Mi |
4Gi |
2 |
256Mi |
8Gi |
4 |
2Gi |
16Gi |
Appeler Cloud de Confiance by S3NS ou des services en ligne dans le code Python
Une UDF Python accède à un service Cloud de Confiance by S3NS ou à un service externe à l'aide du compte de service Connexion aux ressources cloud. Le compte de service de la connexion doit disposer des autorisations nécessaires pour accéder au service. Les autorisations requises varient en fonction du service auquel vous accédez et des API appelées à partir de votre code Python.
Si vous créez une UDF Python sans utiliser de connexion à une ressource Cloud, la fonction est exécutée dans un environnement qui bloque l'accès au réseau. Si votre UDF accède à des services en ligne, vous devez la créer avec une connexion à une ressource Cloud. Sinon, la fonction définie par l'utilisateur ne pourra pas accéder au réseau tant qu'un délai de connexion interne ne sera pas atteint. Lorsque vous utilisez une connexion à une ressource cloud, implémentez les éléments suivants :
Délais d'inactivité. Lorsque vous effectuez des appels réseau dans votre UDF Python, incluez toujours un délai avant expiration raisonnable. Cela empêche la UDF de se bloquer indéfiniment si le service externe met du temps à répondre ou est inaccessible.
Utilisez la gestion des erreurs. Encapsulez le code d'appel réseau dans un bloc
try...exceptpour gérer correctement les erreurs potentielles, telles que les erreurs de connexion, les délais avant expiration ou les codes d'état d'échec HTTP. Cela permet à votre UDF de renvoyer une erreur significative ou une valeur de remplacement au lieu de provoquer l'échec de la requête ou de cesser de répondre.
L'exemple suivant montre comment accéder au service Cloud Translation à partir d'une UDF Python. Cet exemple comporte deux projets : un projet nommé my_query_project dans lequel vous créez la fonction définie par l&#UDF et la connexion à la ressource Cloud, et un projet dans lequel vous exécutez Cloud Translation nommé my_translate_project.
Créer une connexion de ressource Cloud
Commencez par créer une connexion de ressource Cloud dans my_query_project. Pour créer la connexion à la ressource cloud, procédez comme suit.
Console
Accédez à la page BigQuery.
Dans le volet de gauche, cliquez sur Explorateur :

Si le volet de gauche ne s'affiche pas, cliquez sur Développer le volet de gauche pour l'ouvrir.
Dans le volet Explorateur, développez le nom de votre projet, puis cliquez sur Connexions.
Sur la page Connexions, cliquez sur Créer une connexion.
Pour le champ Type de connexion, choisissez Modèles distants Vertex AI, fonctions à distance, BigLake et Spanner (Ressource cloud).
Dans le champ ID de connexion, saisissez un nom pour votre connexion.
Pour Type d'emplacement, sélectionnez un emplacement pour votre connexion. La connexion doit être colocalisée avec vos autres ressources, telles que les ensembles de données.
Cliquez sur Créer une connexion.
Cliquez sur Accéder à la connexion.
Dans le volet Informations de connexion, copiez l'ID du compte de service à utiliser à l'étape suivante.
SQL
Utilisez l'instruction CREATE CONNECTION :
Dans la console Cloud de Confiance , accédez à la page BigQuery.
Dans l'éditeur de requête, saisissez l'instruction suivante :
CREATE CONNECTION [IF NOT EXISTS] `CONNECTION_NAME` OPTIONS ( connection_type = "CLOUD_RESOURCE", friendly_name = "FRIENDLY_NAME", description = "DESCRIPTION" );
Remplacez les éléments suivants :
-
CONNECTION_NAME: nom de la connexion au formatPROJECT_ID.LOCATION.CONNECTION_ID,LOCATION.CONNECTION_IDouCONNECTION_ID. Si le projet ou l'emplacement sont omis, ils sont déduits du projet et de l'emplacement où l'instruction est exécutée. -
FRIENDLY_NAME(facultatif) : nom descriptif de la connexion. -
DESCRIPTION(facultatif) : description de la connexion.
-
Cliquez sur Exécuter.
Pour en savoir plus sur l'exécution des requêtes, consultez Exécuter une requête interactive.
bq
Dans un environnement de ligne de commande, créez une connexion :
bq mk --connection --location=REGION --project_id=PROJECT_ID \ --connection_type=CLOUD_RESOURCE CONNECTION_ID
Le paramètre
--project_idremplace le projet par défaut.Remplacez les éléments suivants :
REGION: votre région de connexionPROJECT_ID: ID de votre projet Cloud de ConfianceCONNECTION_ID: ID de votre connexion
Lorsque vous créez une ressource de connexion, BigQuery crée un compte de service système unique et l'associe à la connexion.
Dépannage : Si vous obtenez l'erreur de connexion suivante, mettez à jour le Google Cloud SDK :
Flags parsing error: flag --connection_type=CLOUD_RESOURCE: value should be one of...
Récupérez et copiez l'ID du compte de service pour l'utiliser lors d'une prochaine étape :
bq show --connection PROJECT_ID.REGION.CONNECTION_ID
Le résultat ressemble à ce qui suit :
name properties 1234.REGION.CONNECTION_ID {"serviceAccountId": "connection-1234-9u56h9@gcp-sa-bigquery-condel.s3ns-system.iam.gserviceaccount.com"}
Python
Avant d'essayer cet exemple, suivez les instructions de configuration pour Python du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Python.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Avant d'exécuter des exemples de code, définissez la variable d'environnement GOOGLE_CLOUD_UNIVERSE_DOMAIN sur s3nsapis.fr.
Node.js
Avant d'essayer cet exemple, suivez les instructions de configuration pour Node.js du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Node.js.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Avant d'exécuter des exemples de code, définissez la variable d'environnement GOOGLE_CLOUD_UNIVERSE_DOMAIN sur s3nsapis.fr.
Terraform
Utilisez la ressource google_bigquery_connection.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
L'exemple suivant crée une connexion de ressources Cloud nommée my_cloud_resource_connection dans la région US :
Pour appliquer votre configuration Terraform dans un projet Cloud de Confiance , suivez les procédures des sections suivantes.
Préparer Cloud Shell
- Lancez Cloud Shell.
-
Définissez le projet Cloud de Confiance par défaut dans lequel vous souhaitez appliquer vos configurations Terraform.
Vous n'avez besoin d'exécuter cette commande qu'une seule fois par projet et vous pouvez l'exécuter dans n'importe quel répertoire.
export GOOGLE_CLOUD_PROJECT=PROJECT_ID
Les variables d'environnement sont remplacées si vous définissez des valeurs explicites dans le fichier de configuration Terraform.
Préparer le répertoire
Chaque fichier de configuration Terraform doit avoir son propre répertoire (également appelé module racine).
-
Dans Cloud Shell, créez un répertoire et un nouveau fichier dans ce répertoire. Le nom du fichier doit comporter l'extension
.tf, par exemplemain.tf. Dans ce tutoriel, le fichier est appelémain.tf.mkdir DIRECTORY && cd DIRECTORY && touch main.tf
-
Si vous suivez un tutoriel, vous pouvez copier l'exemple de code dans chaque section ou étape.
Copiez l'exemple de code dans le fichier
main.tfque vous venez de créer.Vous pouvez également copier le code depuis GitHub. Cela est recommandé lorsque l'extrait Terraform fait partie d'une solution de bout en bout.
- Examinez et modifiez les exemples de paramètres à appliquer à votre environnement.
- Enregistrez les modifications.
-
Initialisez Terraform. Cette opération n'est à effectuer qu'une seule fois par répertoire.
terraform init
Vous pouvez également utiliser la dernière version du fournisseur Google en incluant l'option
-upgrade:terraform init -upgrade
Appliquer les modifications
-
Examinez la configuration et vérifiez que les ressources que Terraform va créer ou mettre à jour correspondent à vos attentes :
terraform plan
Corrigez les modifications de la configuration si nécessaire.
-
Appliquez la configuration Terraform en exécutant la commande suivante et en saisissant
yeslorsque vous y êtes invité :terraform apply
Attendez que Terraform affiche le message "Apply completed!" (Application terminée).
- Ouvrez votre projet Cloud de Confiance pour afficher les résultats. Dans la console Cloud de Confiance , accédez à vos ressources dans l'interface utilisateur pour vous assurer que Terraform les a créées ou mises à jour.
Accorder l'accès au compte de service de la connexion
Vous aurez besoin de l'ID du compte de service que vous avez copié précédemment lorsque vous configurerez les autorisations pour la connexion. Lorsque vous créez une ressource de connexion, BigQuery crée un compte de service système unique et l'associe à la connexion.
Pour accorder au compte de service de connexion aux ressources Cloud l'accès à vos projets, attribuez-lui le rôle d'utilisateur du service d'utilisation des services (roles/serviceusage.serviceUsageConsumer) dans my_query_project et le rôle d'utilisateur de l'API Cloud Translation (roles/cloudtranslate.user) dans my_translate_project.
Console
Accédez à la page IAM.
Vérifiez que
my_query_projectest sélectionné.Cliquez sur Accorder l'accès.
Dans le champ Nouveaux comptes principaux, saisissez l'ID du compte de service de la connexion à la ressource cloud que vous avez copié précédemment.
Dans le champ Sélectionner un rôle, choisissez Utilisation du service, puis sélectionnez Consommateur d'utilisation du service.
Cliquez sur Enregistrer.
Dans le sélecteur de projets, choisissez
my_translate_project.Accédez à la page IAM.
Cliquez sur Accorder l'accès.
Dans le champ Nouveaux comptes principaux, saisissez l'ID du compte de service de la connexion à la ressource cloud que vous avez copié précédemment.
Dans le champ Sélectionner un rôle, sélectionnez Cloud Translation, puis Utilisateur de l'API Cloud Translation.
Cliquez sur Enregistrer.
SQL
Utilisez l'instruction GRANT pour attribuer le rôle Client de Service Usage (roles/serviceusage.serviceUsageConsumer) au compte de service dans my_query_project :
Dans la console Cloud de Confiance , accédez à la page BigQuery.
Dans l'éditeur de requête, saisissez l'instruction suivante :
GRANT `roles/serviceusage.serviceUsageConsumer` ON PROJECT `my_query_project` TO "connection:SERVICE_ACCOUNT_ID";
Remplacez
SERVICE_ACCOUNT_IDpar l'ID du compte de service que vous avez copié précédemment.Cliquez sur Exécuter.
Pour en savoir plus sur l'exécution des requêtes, consultez Exécuter une requête interactive.
Utilisez l'instruction GRANT pour attribuer le rôle d'utilisateur de l'API Cloud Translation (roles/cloudtranslate.user) dans my_translate_project :
Dans la console Cloud de Confiance , accédez à la page BigQuery.
Dans l'éditeur de requête, saisissez l'instruction suivante :
GRANT `roles/cloudtranslate.user` ON PROJECT `my_translate_project` TO "connection:SERVICE_ACCOUNT_ID";
Remplacez
SERVICE_ACCOUNT_IDpar l'ID du compte de service que vous avez copié précédemment.Cliquez sur Exécuter.
Pour en savoir plus sur l'exécution des requêtes, consultez Exécuter une requête interactive.
Créer une UDF Python qui appelle le service Cloud Translation
Dans my_query_project, créez une UDF Python qui appelle le service Cloud Translation à l'aide de votre connexion de ressource cloud.
Dans la console Cloud de Confiance , accédez à la page BigQuery.
Saisissez l'instruction
CREATE FUNCTIONsuivante dans l'éditeur de requête :CREATE FUNCTION `PROJECT_ID.DATASET_ID`.translate_to_es(x STRING) RETURNS STRING LANGUAGE python WITH CONNECTION `PROJECT_ID.REGION.CONNECTION_ID` OPTIONS (entry_point='do_translate', runtime_version='python-3.11', packages=['google-cloud-translate>=3.11', 'google-api-core']) AS r""" from google.api_core.retry import Retry from google.cloud import translate project = "my_translate_project" translate_client = translate.TranslationServiceClient() def do_translate(x : str) -> str: response = translate_client.translate_text( request={ "parent": f"projects/PROJECT_ID/locations/us-central1", "contents": [x], "target_language_code": "es", "mime_type": "text/plain", }, retry=Retry(), ) return response.translations[0].translated_text """; -- Call the UDF. WITH text_table AS (SELECT "Hello" AS text UNION ALL SELECT "Good morning" AS text UNION ALL SELECT "Goodbye" AS text) SELECT text, `PROJECT_ID.DATASET_ID`.translate_to_es(text) AS translated_text FROM text_table;
Remplacez les éléments suivants :
PROJECT_ID: ID du projet.DATASET_ID: ID de l'ensemble de donnéesREGION: région de votre connexion.CONNECTION_ID: ID de la connexion.
Cliquez sur Exécuter.
Le résultat doit se présenter sous la forme suivante :
+--------------------------+-------------------------------+ | text | translated_text | +--------------------------+-------------------------------+ | Hello | Hola | | Good morning | Buen dia | | Goodbye | Adios | +--------------------------+-------------------------------+
Utiliser VPC Service Controls
Les UDF Python héritent du périmètre VPC Service Controls du projet qui exécute le job de requête. Ce périmètre protège vos jobs contre l'exfiltration de données et garantit la sécurité des interactions de service.
Lorsque vous appelez une UDF Python dans le périmètre VPC Service Controls, elle dispose de la connectivité réseau suivante :
- Les UDF Python qui n'utilisent pas de connexion à une ressource cloud sont entièrement isolées. Tout le trafic sortant est bloqué.
- L'accès à Internet public est bloqué pour les UDF Python qui utilisent une connexion à une ressource cloud. Les UDF Python ne peuvent accéder qu'aux services Cloud de Confiance by S3NS compatibles avec VPC Service Controls. Le trafic sortant vers toute destination autre que
restricted.googleapis.comest bloqué.
Configurer des UDF Python pour accéder aux services Cloud de Confiance by S3NS de manière sécurisée dans VPC Service Controls
Pour accéder aux services Cloud de Confiance by S3NS à partir des UDF Python tout en appliquant les VPC Service Controls, procédez comme suit :
- Créez l'UDF Python à l'aide de la clause
WITH CONNECTIONde l'instruction CREATE FUNCTION. - Incluez le projet BigQuery dans lequel la tâche de requête s'exécute et le projet de service cible dans le périmètre de service. Vous pouvez également configurer une liaison de périmètre.
- Ajoutez l'API du service cible à la configuration du périmètre. Par exemple,
translate.googleapis.comsi vous vous connectez à l'API Cloud Translation.
Pour en savoir plus sur la configuration d'un périmètre VPC Service Controls, consultez les ressources suivantes :
Bonnes pratiques
Lorsque vous créez des UDF Python, suivez ces bonnes pratiques :
- Optimisez la logique de vos requêtes pour le traitement par lot. Les structures de requêtes complexes peuvent désactiver le traitement par lot. Cela force un traitement lent, ligne par ligne, ce qui augmente considérablement la latence sur les grands ensembles de données.
- Optimisez la charge utile des données. La taille des lignes individuelles peut avoir un impact sur l'efficacité de la fonctionnalité de traitement par lot. Réduisez la taille de chaque ligne au maximum pour maximiser le nombre de lignes pouvant être traitées dans un même lot.
- Configurez efficacement les limites de conteneur. La scalabilité dépend du processeur, de la mémoire et de la simultanéité des requêtes. Vérifiez les métriques de surveillance pour ajuster la configuration du conteneur.
Si l'utilisation du processeur est élevée, augmentez l'allocation de processeur à l'aide de la limite
container_cpuou réduisez la simultanéité des requêtes de conteneur à l'aide de la limitecontainer_request_concurrency. - Lorsque vous utilisez le réglage itératif, commencez par les valeurs par défaut. Si les performances ne sont pas optimales, analysez les métriques de surveillance pour identifier les goulots d'étranglement spécifiques.
- Implémentez des délais d'attente pour les API. Lorsque votre UDF Python accède à Internet, définissez un délai avant expiration pour l'appel d'API afin d'éviter tout comportement inattendu. La lecture à partir d'un bucket Cloud Storage est un exemple d'accès à Internet.
Afficher les métriques des UDF Python
Les UDF Python exportent des métriques vers Cloud Monitoring. Ces métriques vous aident à surveiller différents aspects de l'état opérationnel et de la consommation de ressources de vos UDF. Elles fournissent des informations sur les performances et le comportement de vos instances UDF.
Type de ressource de surveillance
Les métriques pour les UDF Python sont signalées sous le type de ressource Cloud Monitoring suivant :
- Type :
bigquery.googleapis.com/ManagedRoutineInvocation - Nom à afficher : Appel de routine gérée BigQuery
- Libellés :
resource_container: ID du projet dans lequel le job de requête a été exécuté.location: emplacement où le job de requête a été exécuté.query_job_id: ID du job de requête qui a appelé l'UDF Python.routine_project_id: ID du projet dans lequel la routine appelée est stockée.routine_dataset_id: ID de l'ensemble de données dans lequel la routine appelée est stockée.routine_id: ID de la routine appelée.
Métriques
Les métriques suivantes sont disponibles pour le type de ressource bigquery.googleapis.com/ManagedRoutineInvocation :
| Métrique | Description | Unité | Type de valeur |
|---|---|---|---|
bigquery.googleapis.com/managed_routine/python/cpu_utilizations |
Lorsqu'une UDF Python est appelée, cette métrique affiche la distribution de l'utilisation du processeur sur toutes les instances d'UDF Python pour le job de requête. | Valeur en pourcentage | DISTRIBUTION |
bigquery.googleapis.com/managed_routine/python/memory_utilizations |
Lorsqu'une UDF Python est appelée, cette métrique affiche la distribution de l'utilisation de la mémoire sur toutes les instances d'UDF Python pour le job de requête. | Valeur en pourcentage | DISTRIBUTION |
bigquery.googleapis.com/managed_routine/python/max_request_concurrencies |
Cette métrique indique la répartition du nombre maximal de requêtes simultanées traitées par chaque instance de fonction définie par l'utilisateur Python. | Nombre | DISTRIBUTION |
Afficher les métriques
Pour afficher les métriques de vos UDF Python, choisissez l'une des options des sections suivantes.
Informations sur le job
Pour afficher les métriques des UDF Python pour un job de requête spécifique, procédez comme suit :
Accédez à la page BigQuery.
Cliquez sur Historique des tâches.
Dans la colonne ID du job, cliquez sur l'ID du job de requête.
Sur la page Détails du job de requête, cliquez sur Tableau de bord Cloud Monitoring. Ce lien affiche un tableau de bord filtré pour afficher les métriques des UDF Python pour le job.
Explorateur de métriques
Pour afficher les métriques des UDF Python dans l'explorateur de métriques, procédez comme suit :
Accédez à la page Explorateur de métriques de Cloud Monitoring.
Cliquez sur Sélectionner une métrique, puis saisissez
BigQuery Managed Routine Invocationoubigquery.googleapis.com/ManagedRoutineInvocationdans le champ Filtre.Choisissez Routine gérée BigQuery > managed_routine.
Cliquez sur l'une des métriques disponibles, par exemple :
- Utilisation du processeur de l'instance
- Utilisation de la mémoire de l'instance
- Nombre maximal de requêtes simultanées
Cliquez sur Appliquer.
Par défaut, les métriques sont affichées dans un graphique.
Vous pouvez filtrer et regrouper les métriques à l'aide des libellés définis dans les types de ressources Monitoring. Pour filtrer les métriques, procédez comme suit :
Dans le champ Filtre, sélectionnez un type de ressource tel que
query_job_idouroutine_id.Dans le champ Valeur, saisissez l'ID de la tâche ou de la routine, ou sélectionnez-en un dans la liste.
Tableaux de bord Cloud Monitoring
Pour afficher les métriques des UDF Python à l'aide des tableaux de bord de surveillance, procédez comme suit :
Accédez à la page Tableaux de bord de Cloud Monitoring.
Cliquez sur le tableau de bord Surveillance des requêtes de routine gérée BigQuery.
Ce tableau de bord fournit un aperçu des métriques clés de vos fonctions définies par l'utilisateur.
Pour filtrer ce tableau de bord, procédez comme suit :
Cliquez sur Filtrer.
Dans la liste Filtrer par ressource, sélectionnez une option telle que l'ID du projet, l'emplacement, l'ID de routine ou l'ID du job.
Pays acceptés
Les UDF Python sont compatibles avec tous les emplacements multirégionaux et régionaux BigQuery.
Tarifs
Les frais liés aux UDF Python sont facturés à l'aide du SKU BigQuery Services.
Les frais comprennent les éléments suivants :
Créer ou recréer l'image de conteneur de la UDF;utilisateur Ce coût est proportionnel à la durée nécessaire pour créer l'image correspondante avec le code et les dépendances du client.
- Si vous utilisez l'API Routines, la durée de compilation la plus récente se trouve dans le champ
BuildStatus. Vous pouvez également afficher la durée de compilation dans la colonneBuildStatusde la vueINFORMATION_SCHEMA.ROUTINES. - Pour afficher le coût total des compilations par projet, vous pouvez filtrer votre rapport sur la facturation à l'aide des éléments suivants :
- Key (Clé) :
goog-bq-feature-type - Valeur :
MANAGED_ROUTINE_BUILD
- Key (Clé) :
- Si vous utilisez l'API Routines, la durée de compilation la plus récente se trouve dans le champ
Les clients qui utilisent des UDF Python sont également facturés pour le coût d'appel d'une UDF Python. Ces frais sont proportionnels à la quantité de calcul et de mémoire consommée lorsque l'UDF Python est appelée.
- Pour afficher les coûts des UDF Python par requête, vous pouvez interroger le champ
ExternalServiceCostsà l'aide de l'API Job. Vous pouvez également afficher les coûts par requête en consultant la colonneexternal_service_costsdans la vueINFORMATION_SCHEMA.JOBSet en appliquant le filtre suivant :'external_service_costs.external_service="MANAGED_ROUTINE_EXECUTION"'. - Pour afficher le coût total d'exécution des fonctions définies par l'utilisateur Python par projet, vous pouvez filtrer le rapport sur la facturation à l'aide des éléments suivants :
- Key (Clé) :
goog-bq-feature-type - Valeur :
MANAGED_ROUTINE_EXECUTION
- Key (Clé) :
- Pour afficher les coûts des UDF Python par requête, vous pouvez interroger le champ
Si les UDF Python entraînent une sortie réseau externe ou Internet, vous verrez également des frais de sortie Internet au niveau Premium en fonction des SKU de sortie BigQuery.
Quotas
Consultez la section Quotas et limites des UDF.