
Introducción a las consultas continuas
En este documento, se describen las consultas continuas de BigQuery.
Las consultas continuas de BigQuery son instrucciones de SQL que se ejecutan de forma continua. Las consultas continuas te permiten analizar datos entrantes en BigQuery en tiempo real. Puedes insertar las filas de salida que genera una consulta continua en una tabla de BigQuery o exportarlas a Pub/Sub, Bigtable o Spanner. Las consultas continuas pueden procesar datos que se escribieron en tablas estándar de BigQuery a través de uno de los siguientes métodos:
- La API de BigQuery Storage Write
- El método
tabledata.insertAll - Carga por lotes
- La sentencia
INSERTDML - Sentencias de lenguaje de manipulación de datos (DML)
mutantes, como
DELETE,UPDATE, yMERGE, cuando se exportan datos a Pub/Sub - Escrituras de los resultados de una consulta por lotes en una tabla permanente
- Escrituras de los resultados de una consulta continua de BigQuery en una tabla permanente
- Una suscripción de Pub/Sub a BigQuery
- Escrituras de Dataflow a BigQuery
- Escrituras de Datastream a BigQuery con el modo de escritura de solo anexos
Puedes usar consultas continuas para realizar tareas urgentes, como crear estadísticas y actuar de inmediato en función de ellas, aplicar inferencias de aprendizaje automático (AA) en tiempo real y replicar datos en otras plataformas. Esto te permite usar BigQuery como un motor de procesamiento de datos controlado por eventos para la lógica de decisión de tu aplicación.
En el siguiente diagrama, se muestran flujos de trabajo comunes de consultas continuas:
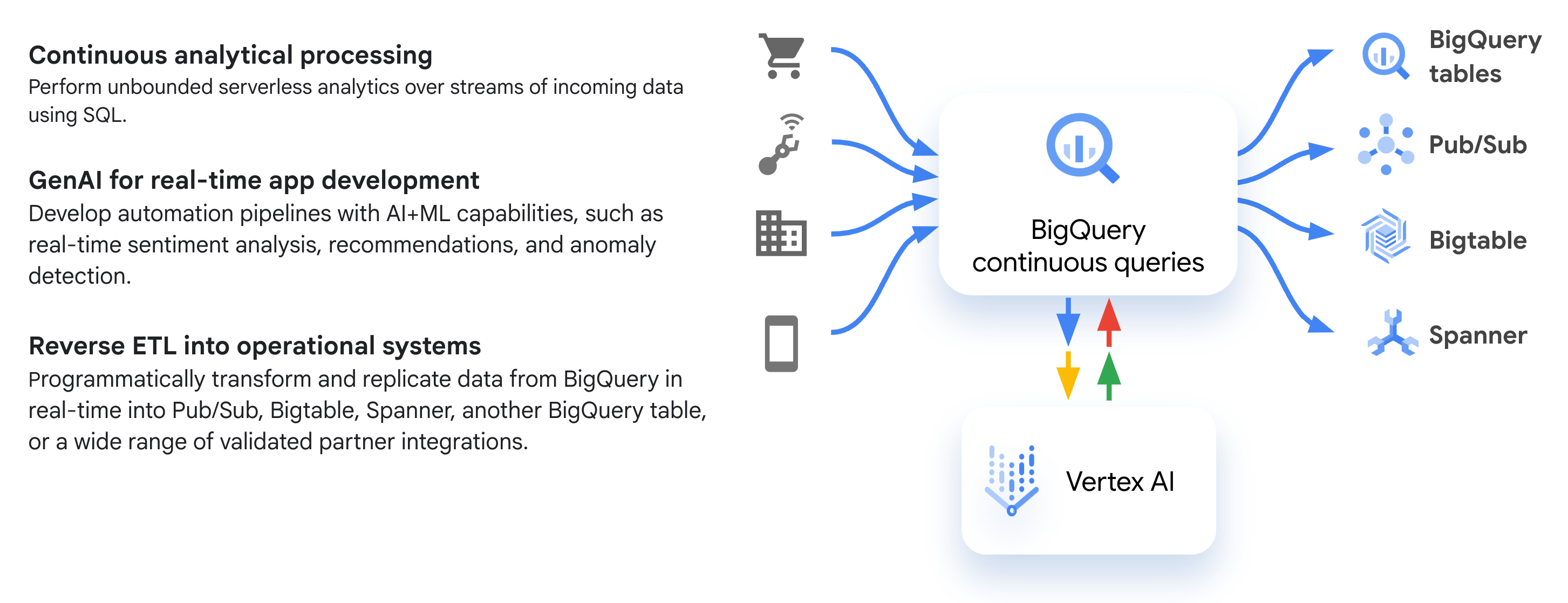
Casos de uso
Estos son algunos casos de uso comunes en los que tal vez quieras usar consultas continuas:
- Servicios de interacción personalizada con el cliente: Usa la IA generativa para crear mensajes personalizados para cada interacción con el cliente.
- Detección de anomalías: Compila soluciones que te permitan realizar la detección de anomalías y amenazas en datos complejos en tiempo real para que puedas reaccionar a los problemas con mayor rapidez.
- Canalizaciones basadas en eventos personalizables: Usa la integración de consultas continuas con Pub/Sub para activar aplicaciones descendentes según los datos entrantes.
- Enriquecimiento de datos y extracción de entidades: Usa consultas continuas para realizar el enriquecimiento y la transformación de datos en tiempo real con funciones de SQL y modelos de AA.
- Extracción, transformación y carga inversa (ETL): Realiza ETL inverso en tiempo real en otros sistemas de almacenamiento más adecuados para la entrega de aplicaciones de baja latencia. Por ejemplo, analizar o mejorar los datos de eventos que se escriben en BigQuery y, luego, transmitirlos a Bigtable o Spanner para la entrega de aplicaciones.
- Activación autónoma de agentes: Activa canalizaciones de datos de agentes en tiempo real en función de eventos complejos detectados en transmisiones de datos en vivo. Para obtener un ejemplo, consulta el codelab Crea un agente de datos basado en eventos con BigQuery y el Kit de desarrollo de agentes (ADK).
- Supervisión autónoma de agentes: desarrolla supervisión y alertas automatizadas en tiempo real para interacciones de agentes en tiempo real con el complemento de análisis de agentes de BigQuery, que transmite todos los datos de seguimiento de agentes, el uso de herramientas y los registros operativos directamente a BigQuery para una observabilidad profunda de tu fuerza laboral de IA.
Funcionalidad admitida
Las siguientes operaciones son compatibles con las consultas continuas:
- Ejecutar
declaraciones
INSERTpara escribir datos de una consulta continua en una tabla de BigQuery Ejecutar sentencias
EXPORT DATApara publicar resultados de consultas continuas en temas de Pub/Sub Para obtener más información, consulta Exporta datos a Pub/Sub.Desde un tema de Pub/Sub, puedes usar los datos con otros servicios, como realizar análisis de transmisiones a través de Dataflow o de los datos en un flujo de trabajo de Application Integration.
Ejecutar declaraciones
EXPORT DATApara exportar datos de BigQuery a tablas de Bigtable Para obtener más información, consulta Exporta datos a Bigtable.Ejecutar declaraciones
EXPORT DATApara exportar datos de BigQuery a tablas de Spanner Para obtener más información, consulta Exporta datos a Spanner (ETL inverso).Llama a las siguientes funciones de IA generativa:
AI.GENERATE-
- Esta función requiere que tengas un modelo remoto de BigQuery ML en un modelo de Agent Platform de Gemini Enterprise.
Llama a las siguientes funciones de IA:
Estas funciones requieren que tengas un modelo remoto de BigQuery ML en una API de Cloud AI.
Normalizar datos numéricos a través de la
ML.NORMALIZERfunción.Analizar y procesar
JSONdatos, incluida la compatibilidad con funciones JSON y la anulación de anidación de JSON.Usar funciones de GoogleSQL sin estado, por ejemplo, funciones de conversión. En las funciones sin estado, cada fila se procesa de forma independiente de las otras filas de la tabla.
Usar operaciones con estado, por ejemplo,
JOINs, agregaciones y agregaciones de ventanas. En las operaciones con estado, el estado de los datos transferidos se retiene en varias filas o intervalos de tiempo para calcular un resultado preciso.Usar la
APPENDSfunción del historial de cambios para procesar datos anexados desde un momento específico.Usar la
CHANGESfunción del historial de cambios para procesar datos modificados, incluidas las anexiones y las mutaciones, desde un momento específico cuando se exportan datos a Pub/Sub. Sin embargo,CHANGESno es compatible cuando se usa una operación con estado.
Operaciones con estado admitidas
Para solicitar asistencia o enviar comentarios sobre esta función, envía un correo electrónico a bq-continuous-queries-feedback@google.com.
Las operaciones con estado permiten que las consultas continuas realicen análisis complejos que requieren retener información en varias filas o intervalos de tiempo. Si bien
las funciones sin estado procesan cada fila de forma independiente, las operaciones con estado mantienen
el estado de los datos transferidos para admitir funciones como JOINs, agregaciones y
agregaciones de ventanas. Esta capacidad te permite correlacionar eventos de diferentes transmisiones o calcular métricas a lo largo del tiempo, como un promedio de 30 minutos, mediante el almacenamiento de los datos necesarios en la memoria mientras se ejecuta la consulta.
Las consultas continuas admiten las siguientes operaciones con estado:
Autorización
Los Cloud de Confiance tokens de acceso que se usan cuando se ejecutan trabajos de consulta continua tienen un tiempo de actividad (TTL) de dos días cuando los genera una cuenta de usuario. Por lo tanto, estos trabajos se dejan de ejecutar después de dos días. Los tokens de acceso que generan las cuentas de servicio pueden ejecutarse por más tiempo, pero deben cumplir con el tiempo de ejecución máximo de la consulta. Para obtener más información, consulta Ejecuta una consulta continua con una cuenta de servicio.
Ubicaciones
Para obtener una lista de las regiones admitidas, consulta Ubicaciones de consultas continuas de BigQuery.
Limitaciones
Las consultas continuas de Spanner están sujetas a las siguientes limitaciones:
- El estado de los datos transferidos solo se mantiene para las operaciones con estado específicas
en la versión preliminar.
Si bien las consultas continuas ahora admiten algunos tipos de
JOINs, agregaciones y agregaciones de ventanas, estos se restringen a operaciones con estado específicas. No se admiten todos los tipos de operaciones con estado. No puedes usar las siguientes capacidades de SQL en una consulta continua, a menos que aparezcan como una operación con estado admitida:
Los siguientes operadores de consulta:
Consulta operadores de conjuntos
Funciones de BigQuery ML distintas de las enumeradas en Funcionalidad admitida
Sentencias del lenguaje de manipulación de datos (DML), excepto
INSERTSentencias
EXPORT DATAque no segmentan Bigtable, Pub/Sub ni Spanner
Las consultas continuas no admiten las siguientes fuentes de datos:
- Tablas externas.
- Vistas de esquema de información.
- Tablas administradas de Apache Iceberg.
- Tablas comodín.
- Datos de inserción o actualización de captura de datos modificados (CDC)
- Vistas materializadas.
- Vistas definidas por otras limitaciones de consultas continuas, como operaciones
JOIN, funciones agregadas, funciones definidas por el usuario o tablas habilitadas para la captura de datos modificados
Las consultas continuas no admiten las funciones de seguridad a nivel de las column- y las filas.
El resultado de una consulta continua está sujeto a las cuotas y los límites inherentes del servicio de destino al que se exporta el resultado.
Cuando exportas datos a extremos de ubicación de Bigtable, Spanner o Pub/Sub solo puedes segmentar recursos de Bigtable, Spanner o Pub/Sub que se encuentren dentro del mismo Cloud de Confiance límite regional que el conjunto de datos de BigQuery que contiene la tabla que estás consultando. Esta restricción no se aplica cuando se exportan datos a extremos globales de Pub/Sub. Para obtener más información sobre la exportación a una política de enrutamiento de perfiles de app de Bigtable, consulta Consideraciones sobre la ubicación.
No puedes ejecutar una consulta continua desde un lienzo de datos.
No puedes modificar el SQL que se usa en una consulta continua mientras se ejecuta el trabajo de consulta continua. Para obtener más información, consulta Modifica el SQL de una consulta continua.
Si un trabajo de consulta continua se retrasa en el procesamiento de los datos entrantes y tiene un retraso de marca de agua de salida de más de 48 horas, falla. Puedes volver a ejecutar la consulta de nuevo y usar la
APPENDSoCHANGESfunción de historial de cambios para reanudar el procesamiento desde el momento en el que detuviste el trabajo de la consulta continua anterior. Para obtener más información, consulta Inicia una consulta continua desde un momento en particular.Una consulta continua configurada con una cuenta de usuario puede ejecutarse hasta por dos días. Una consulta continua configurada con una cuenta de servicio puede ejecutarse hasta por 150 días. Cuando se alcanza el tiempo de ejecución máximo de la consulta, esta falla y deja de procesar los datos entrantes.
Aunque las consultas continuas se compilan con las funciones de confiabilidad de BigQuery, pueden ocurrir problemas temporales ocasionales . Los problemas pueden generar una cierta cantidad de reprocesamiento automático de tu consulta continua, lo que podría generar datos duplicados en el resultado de la consulta continua. Diseña tus sistemas descendentes para controlar esas situaciones.
Limitaciones de las reservas
- Debes crear reservas de la edición Enterprise o Enterprise Plus para ejecutar consultas continuas. Las consultas continuas no son compatibles con el modelo de facturación de procesamiento a pedido.
- Cuando creas una
CONTINUOUSasignación de reserva, la reserva asociada se limita a un máximo de 500 ranuras. Para solicitar un aumento de este límite, comunícate con bq-continuous-queries-feedback@google.com. - No puedes crear una asignación de reserva que use un tipo de trabajo diferente en la misma reserva que una asignación de reserva de consulta continua.
- No puedes configurar la simultaneidad de consultas continua. BigQuery
determina de forma automática la cantidad de consultas continuas que se pueden ejecutar
de forma simultánea, según las asignaciones de reserva disponibles que usan el tipo de
trabajo
CONTINUOUS. - Cuando se ejecutan varias consultas continuas con la misma reserva, es posible que los trabajos individuales no dividan los recursos disponibles de manera equitativa, como se define en la equidad de BigQuery.
Ajuste de escala automático de ranuras
Las consultas continuas pueden usar el ajuste de escala automático de ranuras para ajustar de forma dinámica la capacidad asignada para satisfacer tu carga de trabajo. A medida que aumenta o disminuye la carga de trabajo de las consultas continuas, BigQuery ajusta de forma dinámica tus ranuras.
Después de que se inicia una consulta continua, escucha de forma activa los datos entrantes, lo que consume recursos de ranuras. Si bien una reserva con una consulta continua en ejecución no reduce la escala verticalmente a cero ranuras, se espera que una consulta continua inactiva que principalmente escucha datos entrantes consuma una cantidad mínima de ranuras, por lo general, alrededor de 1 ranura.
Uso compartido de ranuras inactivas
Las consultas continuas pueden usar el uso compartido de ranuras inactivas para compartir recursos de ranuras sin usar con otras reservas y tipos de trabajos.
- A
CONTINUOUSasignación de reserva aún se requiere para ejecutar una consulta continua y no puede depender únicamente de las ranuras inactivas de otras reservas. Por lo tanto, una asignación de reservaCONTINUOUSrequiere un modelo de referencia de ranuras distinto de cero o una configuración de ajuste de escala automático de ranuras distinta de cero. - Solo se pueden compartir las ranuras del modelo de referencia inactivas o las ranuras confirmadas de una asignación de reserva
CONTINUOUS. Las ranuras con ajuste de escala automático no se pueden compartir como ranuras inactivas para otras reservas.
Precios
Las consultas continuas pueden usar el ajuste de escala fluido de BigQuery.
Las consultas continuas usan
los precios de procesamiento de la capacidad de BigQuery,
que se miden en ranuras.
Para ejecutar consultas continuas, debes tener una
reserva que use la
Edición Enterprise o Enterprise Plus,
y una asignación de reserva
que usa el tipo de trabajo CONTINUOUS.
El uso de otros recursos de BigQuery, como la transferencia y el almacenamiento de datos, se cobra según las tarifas que se muestran en los precios de BigQuery.
El uso de otros servicios que reciben resultados de consultas continuas o a los que se llama durante el procesamiento continuo de consultas se cobra según las tarifas publicadas para esos servicios. Para obtener información sobre los precios de otros Cloud de Confiance by S3NS servicios que se usan en las consultas continuas, consulta los siguientes temas:
¿Qué sigue?
Intenta crear una consulta continua.