
dbt에서 BigQuery DataFrames 사용
dbt(데이터 빌드 도구)는 최신 데이터 웨어하우스 내에서 데이터 변환을 위해 설계된 오픈소스 명령줄 프레임워크입니다. dbt는 재사용 가능한 SQL 및 Python 기반 모델을 만들어 모듈식 데이터 변환을 지원합니다. 이 도구는 대상 데이터 웨어하우스 내에서 이러한 변환의 실행을 조정하여 ELT 파이프라인의 변환 단계에 집중합니다. 자세한 내용은 dbt 문서를 참조하세요.
dbt에서 Python 모델은 dbt 프로젝트 내에서 Python 코드를 사용하여 정의되고 실행되는 데이터 변환입니다. 변환 로직을 위한 SQL을 작성하는 대신 dbt가 데이터 웨어하우스 환경 내에서 실행되도록 조정하는 Python 스크립트를 작성합니다. Python 모델을 사용하면 SQL로 표현하기에 복잡하거나 비효율적인 데이터 변환을 수행할 수 있습니다. 이를 통해 Python의 기능을 활용하면서도 dbt의 프로젝트 구조, 조정, 종속 항목 관리, 테스트, 문서화 기능을 활용할 수 있습니다. 자세한 내용은 Python 모델을 참조하세요.
dbt-bigquery 어댑터는 BigQuery DataFrames에 정의된 Python 코드 실행을 지원합니다. 이 기능은 dbt Cloud 및 dbt Core에서 사용할 수 있습니다.
최신 버전의 dbt-bigquery 어댑터를 클론하여 이 기능을 사용할 수도 있습니다.
시작하기 전에
dbt-bigquery 어댑터를 사용하려면 프로젝트에서 다음 API를 사용 설정하세요.
- BigQuery API(
bigquery.googleapis.com) - Cloud Storage API(
storage.googleapis.com) - Compute Engine API(
compute.googleapis.com) - Dataform API (
dataform.googleapis.com) - Identity and Access Management API (
iam.googleapis.com) - Vertex AI API(
aiplatform.googleapis.com)
API 사용 설정에 필요한 역할
API를 사용 설정하려면 serviceusage.services.enable 권한이 포함된 서비스 사용량 관리자 IAM 역할(roles/serviceusage.serviceUsageAdmin)이 필요합니다. 역할 부여 방법 알아보기
필요한 역할
dbt-bigquery 어댑터는 OAuth 기반 및 서비스 계정 기반 인증을 지원합니다. 다음 섹션에서는 인증 방법에 따라 필요한 역할을 설명합니다.
OAuth
OAuth를 사용하여 dbt-bigquery 어댑터에 인증하려면 관리자에게 다음 역할을 부여해 달라고 요청하세요.
- 프로젝트에 대한 BigQuery 사용자 역할(
roles/bigquery.user) - 테이블이 저장된 프로젝트 또는 데이터 세트에 대한 BigQuery 데이터 편집자 역할(
roles/bigquery.dataEditor) - 프로젝트에 대한 Colab Enterprise 사용자 역할(
roles/colabEnterprise.user) - 코드 및 로그 스테이징을 위한 스테이징 Cloud Storage 버킷에 대한 스토리지 관리자 역할(
roles/storage.admin)
서비스 계정
프로젝트의 서비스 계정을 사용하여 dbt-bigquery 어댑터에 인증하려는 경우 관리자에게 사용할 서비스 계정에 다음 역할을 부여해 달라고 요청하세요.
- BigQuery 사용자 역할(
roles/bigquery.user) - BigQuery 데이터 편집자 역할(
roles/bigquery.dataEditor) - Colab Enterprise 사용자 역할(
roles/colabEnterprise.user) - 스토리지 관리자 역할(
roles/storage.admin)
서비스 계정을 사용하여 인증하는 경우 사용할 서비스 계정에 서비스 계정 사용자 역할(roles/iam.serviceAccountUser)이 부여되어 있는지 확인하세요.
서비스 계정 가장
OAuth를 사용하여 dbt-bigquery 어댑터에 인증하지만 데이터 처리 및 노트북 실행이 작업을 실행하는 동일한 프로젝트의 서비스 계정 ID로 발생하도록 하려면 관리자에게 다음 역할을 부여해 달라고 요청하세요.
- 서비스 계정 토큰 생성자 역할
(
roles/iam.serviceAccountTokenCreator) - 서비스 계정 사용자(
roles/iam.serviceAccountUser)
가장된 서비스 계정에도 인증에 필요한 모든 역할이 있어야 합니다.
프로젝트 간 서비스 계정
다른 프로젝트의 서비스 계정을 사용하여 dbt-bigquery 어댑터에 인증하려는 경우 작업이 실행되는 인증 정보 프로젝트, 실행 프로젝트에서 관리자에게 다음을 요청하세요.
- 인증 정보 프로젝트에서
constraints/iam.disableCrossProjectServiceAccountUsage제약 조건을 사용 중지합니다. 서비스 계정 인증에 필요한 역할 외에도 사용자 인증 정보 프로젝트의 서비스 계정에 다음 역할을 부여합니다.
service-PROJECT_NUMBER@gcp-sa-aiplatform.s3ns-system.iam.gserviceaccount.com에 Vertex AI 서비스 에이전트 역할(roles/aiplatform.serviceAgent)- Vertex AI Colab 서비스 에이전트 역할(roles/aiplatform.colabServiceAgent)을
service-PROJECT_NUMBER@gcp-sa-vertex-nb.s3ns-system.iam.gserviceaccount.com에 부여 - Compute Engine 서비스 에이전트 역할(roles/compute.serviceAgent)을
service-PROJECT_NUMBER@compute-system.s3ns-system.iam.gserviceaccount.com에 할당합니다.
OAuth를 사용하여 dbt-bigquery 어댑터에 인증할 계획이지만 데이터 처리 및 노트북 실행이 작업을 실행하는 프로젝트와 다른 프로젝트의 서비스 계정 ID로 발생하도록 하려면 관리자에게 다음을 요청하세요.
- 다른 프로젝트의 서비스 계정에 대해 이전에 설명한 크로스 프로젝트 서비스 계정 단계를 따릅니다.
- 사용자와 서비스 계정에 서비스 계정 가장에 필요한 역할 부여
공유 VPC
공유 VPC 환경에서 Colab Enterprise를 사용하는 경우 관리자에게 다음 역할과 권한을 부여해 달라고 요청하세요.
compute.subnetworks.use권한: 호스트 프로젝트 또는 특정 서브넷에서 Colab Enterprise 런타임이 사용하는 서비스 계정에 이 권한을 부여합니다. 이 권한은 Compute 네트워크 사용자 역할(roles/compute.networkUser)에 포함되어 있습니다.compute.subnetworks.get권한: 호스트 프로젝트 또는 특정 서브넷에서 Colab Enterprise 런타임이 사용하는 서비스 계정에 이 권한을 부여합니다. 이 권한은 Compute 네트워크 뷰어 역할(roles/compute.networkViewer)에 포함되어 있습니다.Compute 네트워크 사용자 역할(
roles/compute.networkUser): 공유 VPC 호스트 프로젝트에서 Gemini Enterprise 에이전트 플랫폼 서비스 에이전트(service-PROJECT_NUMBER@gcp-sa-aiplatform.s3ns-system.iam.gserviceaccount.com)에 이 역할을 부여합니다.Compute 네트워크 사용자 역할(
roles/compute.networkUser): 노트북 실행 작업 기능을 사용하는 경우 공유 VPC 호스트 프로젝트에서 Colab Enterprise 서비스 에이전트(service-PROJECT_NUMBER@gcp-sa-vertex-nb.s3ns-system.iam.gserviceaccount.com)에 이 역할을 부여합니다.
역할 부여에 대한 상세 설명은 프로젝트, 폴더, 조직에 대한 액세스 관리를 참조하세요.
커스텀 역할이나 다른 사전 정의된 역할을 통해 필요한 권한을 얻을 수도 있습니다.
Python 실행 환경
dbt-bigquery 어댑터는 Colab Enterprise 노트북 실행기 서비스를 사용하여 BigQuery DataFrames Python 코드를 실행합니다. Colab Enterprise 노트북은 모든 Python 모델에서 dbt-bigquery 어댑터에 의해 자동으로 생성되고 실행됩니다. 노트북을 실행할Cloud de Confiance 프로젝트를 선택할 수 있습니다. 노트북은 모델의 Python 코드를 실행하며, 이 코드는 BigQuery DataFrames 라이브러리에 의해 BigQuery SQL로 변환됩니다. 그런 다음 BigQuery SQL이 구성된 프로젝트에서 실행됩니다. 다음 다이어그램은 제어 흐름을 보여줍니다.
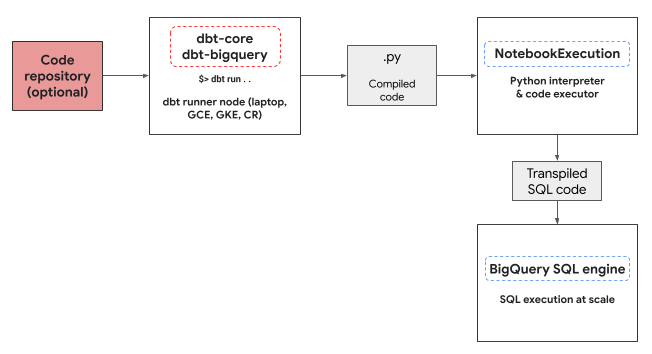
프로젝트에 아직 사용 가능한 노트북 템플릿이 없고 코드를 실행하는 사용자에게 템플릿을 만들 권한이 있는 경우 dbt-bigquery 어댑터는 기본 노트북 템플릿을 자동으로 만들고 사용합니다. dbt 구성을 사용하여 다른 노트북 템플릿을 지정할 수도 있습니다.
노트북 실행에는 코드와 로그를 저장할 스테이징 Cloud Storage 버킷이 필요합니다. 하지만 dbt-bigquery 어댑터 로그를 dbt 로그에 복사하므로 버킷을 살펴볼 필요가 없습니다.
지원되는 기능
dbt-bigquery 어댑터는 BigQuery DataFrames를 실행하는 dbt Python 모델에 대해 다음 기능을 지원합니다.
dbt.source()매크로를 사용하여 기존 BigQuery 테이블에서 데이터를 로드합니다.dbt.ref()매크로를 사용하여 다른 dbt 모델에서 데이터를 로드하여 종속 항목을 빌드하고 Python 모델로 방향성 비순환 그래프(DAG)를 만듭니다.- Python 코드 실행에 사용할 수 있는 PyPi의 Python 패키지를 지정하고 사용합니다. 자세한 내용은 구성을 참조하세요.
- BigQuery DataFrames 모델의 커스텀 노트북 런타임 템플릿을 지정합니다.
dbt-bigquery 어댑터는 다음 구체화 전략을 지원합니다.
- 테이블 구체화: 각 실행에서 데이터가 테이블로 재구성됩니다.
- 병합 전략을 사용한 증분 구체화. 변경사항을 처리하기 위해 병합 전략을 사용하여 새 데이터 또는 업데이트된 데이터를 기존 테이블에 추가합니다.
BigQuery DataFrames를 사용하도록 dbt 설정
dbt Core를 사용하는 경우 BigQuery DataFrames와 함께 사용하려면 profiles.yml 파일을 사용해야 합니다.
다음 예시에서는 oauth 메서드를 사용합니다.
your_project_name:
outputs:
dev:
compute_region: us-central1
dataset: your_bq_dateset
gcs_bucket: your_gcs_bucket
job_execution_timeout_seconds: 300
job_retries: 1
location: US
method: oauth
priority: interactive
project: your_gcp_project
threads: 1
type: bigquery
target: dev
dbt Cloud를 사용하는 경우 dbt Cloud 인터페이스에서 직접 데이터 플랫폼에 연결할 수 있습니다. 이 시나리오에서는 profiles.yml 파일이 필요하지 않습니다. 자세한 내용은 profiles.yml 정보를 참조하세요.
다음은 dbt_project.yml 파일의 프로젝트 수준 구성의 예시입니다.
# Name your project! Project names should contain only lowercase characters
# and underscores. A good package name should reflect your organization's
# name or the intended use of these models.
name: 'your_project_name'
version: '1.0.0'
# Configuring models
# Full documentation: https://docs.getdbt.com/docs/configuring-models
# In this example config, we tell dbt to build all models in the example/
# directory as views. These settings can be overridden in the individual model
# files using the config(...) macro.
models:
your_project_name:
submission_method: bigframes
notebook_template_id: 7018811640745295872
packages: ["scikit-learn", "mlflow"]
timeout: 3000
# Config indicated by + and applies to all files under models/example/
example:
+materialized: view
Python 코드 내에서 dbt.config 메서드를 사용하여 일부 파라미터를 구성할 수도 있습니다. 이러한 설정이 dbt_project.yml 파일과 충돌하는 경우 dbt.config가 있는 구성이 우선 적용됩니다.
자세한 내용은 모델 구성 및 dbt_project.yml을 참조하세요.
구성
Python 모델에서 dbt.config 메서드를 사용하여 다음 구성을 설정할 수 있습니다. 이러한 구성은 프로젝트 수준 구성을 재정의합니다.
| 구성 | 필수 | 사용 |
|---|---|---|
submission_method |
예 | submission_method=bigframes |
notebook_template_id |
아니요 | 지정하지 않으면 기본 템플릿이 생성되어 사용됩니다. |
packages |
아니요 | 필요한 경우 Python 패키지의 추가 목록을 지정합니다. |
timeout |
아니요 | 선택사항: 작업 실행 제한 시간을 연장합니다. |
Python 모델 예시
다음 섹션에서는 예시 시나리오와 Python 모델을 보여줍니다.
BigQuery 테이블에서 데이터 로드
기존 BigQuery 테이블의 데이터를 Python 모델에서 소스로 사용하려면 먼저 YAML 파일에서 이 소스를 정의합니다. 다음 예시는 source.yml 파일에 정의되어 있습니다.
version: 2
sources:
- name: my_project_source # A custom name for this source group
database: bigframes-dev # Your Google Cloud project ID
schema: yyy_test_us # The BigQuery dataset containing the table
tables:
- name: dev_sql1 # The name of your BigQuery table
그런 다음 이 YAML 파일에 구성된 데이터 소스를 사용할 수 있는 Python 모델을 빌드합니다.
def model(dbt, session):
# Configure the model to use BigFrames for submission
dbt.config(submission_method="bigframes")
# Load data from the 'dev_sql1' table within 'my_project_source'
source_data = dbt.source('my_project_source', 'dev_sql1')
# Example transformation: Create a new column 'id_new'
source_data['id_new'] = source_data['id'] * 10
return source_data
다른 모델 참조
다음 예시와 같이 다른 dbt 모델의 출력에 종속된 모델을 빌드할 수 있습니다. 이는 모듈식 데이터 파이프라인을 만드는 데 유용합니다.
def model(dbt, session):
# Configure the model to use BigFrames
dbt.config(submission_method="bigframes")
# Reference another dbt model named 'dev_sql1'.
# It assumes you have a model defined in 'dev_sql1.sql' or 'dev_sql1.py'.
df_from_sql = dbt.ref("dev_sql1")
# Example transformation on the data from the referenced model
df_from_sql['id'] = df_from_sql['id'] * 100
return df_from_sql
패키지 종속 항목 지정
Python 모델에 MLflow 또는 Boto3와 같은 특정 서드 파티 라이브러리가 필요한 경우 다음 예시와 같이 모델의 구성에서 패키지를 선언할 수 있습니다. 이러한 패키지는 실행 환경에 설치됩니다.
def model(dbt, session):
# Configure the model for BigFrames and specify required packages
dbt.config(
submission_method="bigframes",
packages=["mlflow", "boto3"] # List the packages your model needs
)
# Import the specified packages for use in your model
import mlflow
import boto3
# Example: Create a DataFrame showing the versions of the imported packages
data = {
"mlflow_version": [mlflow.__version__],
"boto3_version": [boto3.__version__],
"note": ["This demonstrates accessing package versions after import."]
}
bdf = bpd.DataFrame(data)
return bdf
기본값이 아닌 템플릿 지정
실행 환경을 더 세밀하게 제어하거나 사전 구성된 설정을 사용하려면 다음 예시와 같이 BigQuery DataFrames 모델에 기본값이 아닌 노트북 템플릿을 지정하면 됩니다.
def model(dbt, session):
dbt.config(
submission_method="bigframes",
# ID of your pre-created notebook template
notebook_template_id="857350349023451yyyy",
)
data = {"int": [1, 2, 3], "str": ['a', 'b', 'c']}
return bpd.DataFrame(data=data)
테이블 구체화
dbt가 Python 모델을 실행할 때는 결과를 데이터 웨어하우스에 저장하는 방법을 알아야 합니다. 이를 구체화라고 합니다.
표준 테이블 구체화의 경우 dbt는 실행될 때마다 모델의 출력으로 웨어하우스의 테이블을 생성하거나 완전히 대체합니다. 이는 기본적으로 또는 다음 예시와 같이 materialized='table' 속성을 명시적으로 설정하여 실행됩니다.
def model(dbt, session):
dbt.config(
submission_method="bigframes",
# Instructs dbt to create/replace this model as a table
materialized='table',
)
data = {"int_column": [1, 2], "str_column": ['a', 'b']}
return bpd.DataFrame(data=data)
병합 전략을 사용한 증분 구체화는 dbt가 신규 또는 수정된 행만 사용하여 테이블을 업데이트하도록 지원합니다. 이는 테이블을 매번 완전히 다시 빌드하는 것이 비효율적일 수 있으므로 대규모 데이터 세트에 유용합니다. 병합 전략은 이러한 업데이트를 처리하는 일반적인 방법입니다.
이 접근 방식은 다음을 수행하여 변경사항을 지능적으로 통합합니다.
- 변경된 기존 행을 업데이트합니다.
- 새 행 추가
- 구성에 따라 선택사항: 더 이상 소스에 없는 행을 삭제합니다.
병합 전략을 사용하려면 다음 예시와 같이 dbt가 모델의 출력과 기존 테이블 간에 일치하는 행을 식별하는 데 사용할 수 있는 unique_key 속성을 지정해야 합니다.
def model(dbt, session):
dbt.config(
submission_method="bigframes",
materialized='incremental',
incremental_strategy='merge',
unique_key='int', # Specifies the column to identify unique rows
)
# In this example:
# - Row with 'int' value 1 remains unchanged.
# - Row with 'int' value 2 has been updated.
# - Row with 'int' value 4 is a new addition.
# The 'merge' strategy will ensure that only the updated row ('int 2')
# and the new row ('int 4') are processed and integrated into the table.
data = {"int": [1, 2, 4], "str": ['a', 'bbbb', 'd']}
return bpd.DataFrame(data=data)
문제 해결
dbt 로그에서 Python 실행을 확인할 수 있습니다.
또한 Colab Enterprise 실행 페이지에서 코드와 로그(이전 실행 포함)를 볼 수 있습니다.
결제
BigQuery DataFrames와 함께 dbt-bigquery 어댑터를 사용하는 경우 다음 항목에서 Cloud de Confiance by S3NS 요금이 청구됩니다.
노트북 실행: 노트북 런타임 실행에 대한 요금이 청구됩니다. 자세한 내용은 노트북 런타임 가격 책정을 참조하세요.
BigQuery 쿼리 실행: 노트북에서 BigQuery DataFrames는 Python을 SQL로 변환하고 BigQuery에서 코드를 실행합니다. BigQuery DataFrames 가격 책정에 설명된 대로 프로젝트 구성 및 쿼리에 따라 요금이 청구됩니다.
BigQuery 결제 콘솔에서 다음 결제 라벨을 사용하여 노트북 실행 및 dbt-bigquery 어댑터에 의해 트리거된 BigQuery 실행의 결제 보고서를 필터링할 수 있습니다.
- BigQuery 실행 라벨:
bigframes-dbt-api
다음 단계
- dbt 및 BigQuery DataFrames에 대해 자세히 알아보려면 dbt Python 모델과 함께 BigQuery DataFrames 사용을 참조하세요.
- dbt Python 모델에 대해 자세히 알아보려면 Python 모델 및 Python 모델 구성을 참조하세요.
- Colab Enterprise 노트북에 대해 자세히 알아보려면 Cloud de Confiance 콘솔을 사용하여 Colab Enterprise 노트북 만들기를 참조하세요.
- Cloud de Confiance by S3NS 파트너에 대해 자세히 알아보려면 Cloud de Confiance by S3NS Ready - BigQuery 파트너를 참조하세요.