
Gerenciar tabelas em cluster
Este documento descreve como receber informações e controlar o acesso a tabelas em cluster no BigQuery.
Para ver mais informações, consulte os seguintes tópicos:
- Para saber mais sobre o suporte a tabelas em cluster no BigQuery, consulte Introdução às tabelas em cluster.
- Para saber como criar tabelas em cluster, consulte Criar tabelas em cluster.
Antes de começar
Para receber informações sobre tabelas, é necessário ter a permissão bigquery.tables.get. Os seguintes papéis predefinidos do IAM incluem as permissões bigquery.tables.get:
roles/bigquery.metadataViewerroles/bigquery.dataViewerroles/bigquery.dataOwnerroles/bigquery.dataEditorroles/bigquery.admin
Além disso, se um usuário tiver a permissão bigquery.datasets.create ao criar um conjunto de dados, será concedido o acesso bigquery.dataOwner.
O acesso bigquery.dataOwner permite que o usuário receba informações sobre tabelas em um conjunto de dados.
Para mais informações sobre os papéis e as permissões do IAM no BigQuery, consulte Papéis e permissões predefinidos.
Controlar o acesso a tabelas em cluster
Para configurar o acesso a tabelas e visualizações, conceda um papel do IAM a uma entidade nos seguintes níveis, listados em ordem de intervalo de recursos permitidos (do maior para o menor):
- Um nível alto na Cloud de Confiance by S3NS hierarquia de recursos como o nível do projeto, da pasta ou da organização
- O nível do conjunto de dados
- O nível da tabela ou da visualização
Também é possível restringir o acesso a dados nas tabelas usando os métodos a seguir:
O acesso a qualquer recurso protegido pelo IAM é aditivo. Por exemplo, se uma entidade não tiver acesso em um nível alto, como o projeto, uma opção será conceder à entidade o acesso no nível do conjunto de dados, e ela terá acesso às tabelas e visualizações no conjunto de dados. Da mesma forma, se a entidade não tiver nível acesso alto ou ao conjunto de dados, você tem a opção de conceder acesso à tabela/visualização.
A concessão de papéis do IAM em um nível mais alto na Cloud de Confiance by S3NS hierarquia de recursos do Google Cloud, como projeto, pasta ou organização, concede à entidade acesso a um amplo conjunto de recursos. Por exemplo, conceder um papel a uma entidade no nível do projeto fornece a ela permissões referentes aos conjuntos de dados em todo o projeto.
Conceder um papel no nível do conjunto de dados especifica as operações que uma entidade tem permissão de realizar em tabelas e define as visualizações nesse conjunto de dados específico, mesmo que a entidade não tenha acesso em um nível superior. Para informações sobre como configurar controles de acesso no nível do conjunto de dados, consulte este link.
A concessão de um papel no nível da tabela ou da visualização especifica as operações que uma entidade pode realizar em tabelas e visualizações específicas, mesmo que a entidade não tenha acesso em um nível superior. Para informações sobre como configurar controles de acesso no nível da tabela e da visualização, consulte este link.
Você também pode criar papéis personalizados do IAM. Se você criar um papel personalizado, as permissões concedidas dependerão das operações específicas que a entidade poderá executar.
Não é possível definir uma permissão "deny" em nenhum recurso protegido pelo IAM.
Para mais informações sobre papéis e permissões, consulte Noções básicas sobre papéis na documentação do IAM e os papéis e permissões do IAM do BigQuery .
Receber informações sobre tabelas em cluster
Selecione uma das seguintes opções:
Console
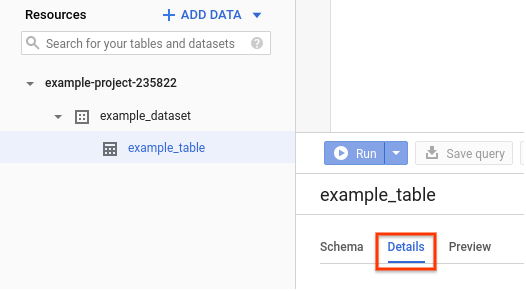
No Cloud de Confiance console, acesse o painel Recursos.
Clique no nome do conjunto de dados para expandi-lo e, em seguida, selecione o nome da tabela que você quer visualizar.
Clique em Detalhes.
Os detalhes da tabela são exibidos, incluindo as colunas de clustering.
SQL
Para tabelas em cluster, consulte a CLUSTERING_ORDINAL_POSITION coluna
na INFORMATION_SCHEMA.COLUMNS visualização
para encontrar o deslocamento de índice 1 da coluna nas colunas de clustering
da tabela:
No Cloud de Confiance console, acesse a página BigQuery.
No editor de consultas, digite a seguinte instrução:
CREATE TABLE mydataset.data (column1 INT64, column2 INT64) CLUSTER BY column1, column2; SELECT column_name, clustering_ordinal_position FROM mydataset.INFORMATION_SCHEMA.COLUMNS;
Clique em Executar.
Para mais informações sobre como executar consultas, acesse Executar uma consulta interativa.
A posição ordinal do clustering é 1 para column1 e 2 para column2.
Mais metadados da tabela estão disponíveis nas visualizações TABLES, TABLE_OPTIONS, COLUMNS e COLUMN_FIELD_PATH em INFORMATION_SCHEMA.
bq
Emita o comando bq show para exibir todas as informações da tabela. Use a sinalização --schema para exibir somente informações de esquema da tabela. A sinalização --format pode ser usada para controlar a saída.
Se você estiver recebendo informações sobre uma tabela em um projeto diferente do projeto padrão, adicione o ID do projeto ao conjunto de dados no seguinte formato: project_id:dataset.
bq show \ --schema \ --format=prettyjson \ PROJECT_ID:DATASET.TABLE
Substitua:
PROJECT_ID: o ID do projetoDATASET: o nome do conjunto de dadosTABLE: o nome da tabela
Exemplos:
Digite o comando a seguir para exibir todas as informações sobre myclusteredtable em mydataset. mydataset está no seu projeto padrão.
bq show --format=prettyjson mydataset.myclusteredtable
A saída será semelhante a esta:
{
"clustering": {
"fields": [
"customer_id"
]
},
...
}
API
Chame o método bigquery.tables.get e forneça os parâmetros relevantes.
Listar tabelas em cluster em um conjunto de dados
As permissões e as etapas necessárias para listar tabelas em cluster são as mesmas das tabelas padrão. Para mais informações, consulte Como listar tabelas em um conjunto de dados.
Modificar a especificação de clustering
É possível alterar ou remover as especificações de clustering de uma tabela ou alterar o conjunto de colunas em cluster em uma tabela em cluster. Esse método de atualização do conjunto de colunas em cluster é útil para tabelas que usam inserções de streaming contínuas, porque essas tabelas não podem ser facilmente alternadas por outros métodos.
Siga estas etapas para aplicar uma nova especificação de clustering a tabelas não particionadas ou particionadas.
Na ferramenta bq, atualize a especificação de clustering da tabela para corresponder ao novo clustering:
bq update --clustering_fields=CLUSTER_COLUMN DATASET.ORIGINAL_TABLE
Substitua:
CLUSTER_COLUMN: a coluna que você está agrupando, por exemplo,mycolumn.DATASET: o nome do conjunto de dados que contém a tabela. Por exemplo,mydatasetORIGINAL_TABLE: o nome da tabela original, por exemplo,mytable
Também é possível chamar o método de API
tables.updateoutables.patchpara modificar a especificação de clustering.Para agrupar todas as linhas de acordo com a nova especificação de clustering, execute a seguinte instrução
UPDATE:UPDATE DATASET.ORIGINAL_TABLE SET CLUSTER_COLUMN=CLUSTER_COLUMN WHERE true
A seguir
- Para mais informações sobre como consultar tabelas em cluster, consulte Consultar tabelas em cluster.
- Para uma visão geral do suporte a tabela particionada no BigQuery, consulte esta página.
- Para saber como criar tabelas particionadas, consulte Criar tabelas particcionadas.