
管理叢集資料表
本文說明如何取得 BigQuery 中叢集資料表的相關資訊,以及如何控管叢集資料表的存取權。
如要瞭解詳情,請參考下列資源:
事前準備
如要取得資料表相關資訊,您必須具備 bigquery.tables.get 權限。以下是具有 bigquery.tables.get 權限的預先定義 IAM 角色:
roles/bigquery.metadataViewerroles/bigquery.dataViewerroles/bigquery.dataOwnerroles/bigquery.dataEditorroles/bigquery.admin
此外,當具備 bigquery.datasets.create 權限的使用者建立資料集時,該使用者會獲得該資料集的 bigquery.dataOwner 存取權。bigquery.dataOwner 存取權可讓使用者取得資料集裡的資料表相關資訊。
如要進一步瞭解 BigQuery 中的 IAM 角色和權限,請參閱預先定義的角色和權限一文。
控管叢集資料表的存取權
如要設定資料表和檢視表的存取權,請在下列層級為實體授予 IAM 角色。這些層級會依允許的資源範圍列出 (從最大到最小):
- Cloud de Confiance by S3NS 資源階層中的較高層級,例如專案、資料夾或機構層級
- 資料集層級
- 資料表或檢視畫面層級
您也可以使用下列方法,限制資料表中的資料存取權:
存取受 IAM 保護的資源時,存取權是累加的。舉例來說,如果實體沒有專案等高層級的存取權,您可以在資料集層級授予實體存取權,這樣實體就能存取資料集中的資料表和檢視區塊。同樣地,如果實體沒有高層級或資料集層級的存取權,您可以在資料表或檢視區塊層級授予實體存取權。
在Cloud de Confiance by S3NS資源階層中的較高層級 (例如專案、資料夾或機構層級) 授予 IAM 角色,可讓實體存取更多資源。舉例來說,在專案層級將特定角色授予實體,可讓該實體擁有適用於專案中所有資料集的權限。
在資料集層級授予角色,即可讓實體對特定資料集裡的資料表和檢視表執行指定作業,即使實體不具備更高層級的存取權也是如此。如要瞭解如何設定資料集層級的存取權控管設定,請參閱控管資料集存取權一文。
在資料表或檢視表層級授予角色,即可讓實體對特定資料表和檢視表執行指定作業,即使實體沒有較高層級的存取權也一樣。如要瞭解如何設定資料表層級的存取權控管設定,請參閱控管資料表和檢視區塊的存取權一文。
您也可以建立 IAM 自訂角色。建立自訂角色之後,您就能依據要讓實體執行的特定作業授予權限。
您無法對受 IAM 保護的任何資源設定「拒絕」權限。
如要進一步瞭解角色和權限,請參閱 IAM 說明文件中的「瞭解角色」和 BigQuery 的「IAM 角色和權限」。
取得叢集資料表的相關資訊
選取下列選項之一:
控制台
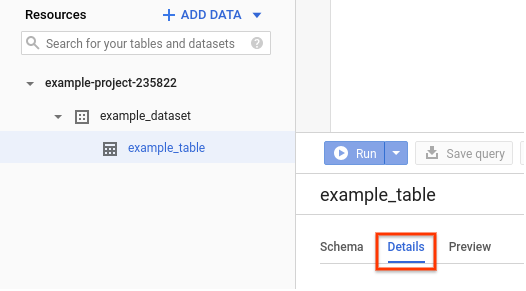
前往 Cloud de Confiance 控制台的「Resources」(資源) 窗格。
按一下資料集名稱,即可展開該資料集,然後點選您想要查看的資料表名稱。
按一下「詳細資料」。
畫面會顯示資料表的詳細資料,包括叢集資料欄。
SQL
對於叢集資料表,您可以在 INFORMATION_SCHEMA.COLUMNS 檢視表中查詢 CLUSTERING_ORDINAL_POSITION 資料欄,找出資料表叢集資料欄中資料欄的 1 索引偏移:
前往 Cloud de Confiance 控制台的「BigQuery」頁面。
在查詢編輯器中輸入下列陳述式:
CREATE TABLE mydataset.data (column1 INT64, column2 INT64) CLUSTER BY column1, column2; SELECT column_name, clustering_ordinal_position FROM mydataset.INFORMATION_SCHEMA.COLUMNS;
按一下「執行」。
如要進一步瞭解如何執行查詢,請參閱「執行互動式查詢」。
column1 的叢集序數位置為 1,column2 則為 2。
您可以透過 INFORMATION_SCHEMA 中的 TABLES、TABLE_OPTIONS、COLUMNS 和 COLUMN_FIELD_PATH 檢視表,查看更多資料表中繼資料。
bq
發出 bq show 指令以顯示所有資料表資訊。使用 --schema 旗標可以只顯示資料表結構定義資訊。--format 旗標可用來控制輸出內容。
如果您要取得非預設專案中資料表的相關資訊,請使用下列格式將專案 ID 新增至資料集:project_id:dataset。
bq show \ --schema \ --format=prettyjson \ PROJECT_ID:DATASET.TABLE
更改下列內容:
PROJECT_ID:專案 IDDATASET:資料集名稱TABLE:資料表名稱。
範例:
輸入下列指令,顯示 mydataset 中 myclusteredtable 的所有相關資訊。mydataset 在您的預設專案中。
bq show --format=prettyjson mydataset.myclusteredtable
輸出應如下所示:
{
"clustering": {
"fields": [
"customer_id"
]
},
...
}
API
呼叫 bigquery.tables.get 方法,並提供所有相關參數。
列出資料集中的叢集資料表
列出叢集資料表所需具備的權限及步驟,與標準資料表相同。詳情請參閱「列出資料集中的資料表」。
修改叢集規格
您可以變更或移除資料表的叢集規格,也可以變更叢集資料表中的叢集資料欄集。如果資料表使用連續串流插入,就無法輕易透過其他方法交換,因此這種更新叢集欄集的方法非常實用。
請按照下列步驟,將新的叢集規格套用至未分區或分區資料表。
在 bq 工具中,更新資料表的叢集規格,以符合新的叢集:
bq update --clustering_fields=CLUSTER_COLUMN DATASET.ORIGINAL_TABLE
更改下列內容:
CLUSTER_COLUMN:您要叢集化的資料欄,例如mycolumnDATASET:包含資料表的資料集名稱,例如mydatasetORIGINAL_TABLE:原始資料表的名稱,例如mytable
您也可以呼叫
tables.update或tables.patchAPI 方法來修改叢集規格。如要根據新的叢集規格將所有資料列叢集化,請執行下列
UPDATE陳述式:UPDATE DATASET.ORIGINAL_TABLE SET CLUSTER_COLUMN=CLUSTER_COLUMN WHERE true