
Migração do Amazon Redshift para o BigQuery: vista geral
Este documento fornece orientações sobre a migração do Amazon Redshift para o BigQuery, com foco nos seguintes tópicos:
- Estratégias de migração
- Práticas recomendadas para a otimização de consultas e a modelagem de dados
- Sugestões de resolução de problemas
- Orientações para a adoção por parte dos utilizadores
Os objetivos deste documento são os seguintes:
- Fornecer orientações de alto nível para organizações que migram do Amazon Redshift para o BigQuery, incluindo ajuda para repensar os pipelines de dados existentes para tirar o máximo partido do BigQuery.
- Ajudar a comparar as arquiteturas do BigQuery e do Amazon Redshift para que possa determinar como implementar as funcionalidades e as capacidades existentes durante a migração. O objetivo é mostrar-lhe as novas capacidades disponíveis para a sua organização através do BigQuery e não mapear as funcionalidades individualmente com o Amazon Redshift.
Este documento destina-se a arquitetos empresariais, administradores de bases de dados, programadores de aplicações e especialistas em segurança de TI. Parte do princípio de que conhece o Amazon Redshift.
Também pode usar a tradução SQL em lote para migrar os seus scripts SQL em massa ou a tradução SQL interativa para traduzir consultas ad hoc. O SQL do Amazon Redshift é totalmente suportado pelos serviços de tradução de SQL.
Tarefas de pré-migração
Para ajudar a garantir uma migração bem-sucedida do data warehouse, comece a planear a sua estratégia de migração no início do cronograma do projeto. Esta abordagem permite-lhe avaliar as Cloud de Confiance by S3NS funcionalidades que se adequam às suas necessidades.
Planeamento de capacidade
O BigQuery usa slots para medir o débito da análise. Um slot do BigQuery é a unidade proprietária da Google de capacidade computacional necessária para executar consultas SQL. O BigQuery calcula continuamente quantos slots são necessários para as consultas à medida que são executadas, mas atribui slots às consultas com base num programador justo.
Pode escolher entre os seguintes modelos de preços quando planear a capacidade dos slots do BigQuery:
- Preços a pedido: com os preços a pedido, o BigQuery cobra pelo número de bytes processados (tamanho dos dados), pelo que paga apenas pelas consultas que executa. Para mais informações sobre como o BigQuery determina o tamanho dos dados, consulte o artigo Cálculo do tamanho dos dados. Uma vez que os slots determinam a capacidade computacional subjacente, pode pagar pela utilização do BigQuery consoante o número de slots de que precisa (em vez de bytes processados). Por predefinição, todos os Cloud de Confiance projetos estão limitados a um máximo de 2000 espaços. O BigQuery pode exceder este limite para acelerar as suas consultas, mas o aumento rápido não é garantido.
- Preços baseados na capacidade: Com os preços baseados na capacidade, compra reservas de slots do BigQuery (um mínimo de 100) em vez de pagar pelos bytes processados pelas consultas que executa. Recomendamos os preços baseados na capacidade para cargas de trabalho de armazéns de dados empresariais, que normalmente têm muitas consultas de relatórios e de extração, carregamento e transformação (ELT) simultâneas com um consumo previsível.
Para ajudar na estimativa de slots, recomendamos que configure a monitorização do BigQuery através do Cloud Monitoring e analise os seus registos de auditoria através do BigQuery. Pode usar o Looker Studio (aqui tem um exemplo de código aberto de um painel de controlo do Looker Studio) ou o Looker para visualizar os dados do registo de auditoria do BigQuery, especificamente para a utilização de ranhuras em consultas e projetos. Também pode usar os dados das tabelas do sistema do BigQuery para monitorizar a utilização de slots em tarefas e reservas (aqui tem um exemplo de código aberto de um painel de controlo do Looker Studio). A monitorização e a análise regulares da utilização de slots ajudam a estimar o número total de slots de que a sua organização precisa à medida que cresce no Cloud de Confiance.
Por exemplo, suponha que reserva inicialmente 4000 slots do BigQuery para executar 100 consultas de complexidade média em simultâneo. Se notar tempos de espera elevados nos planos de execução das suas consultas e os painéis de controlo mostrarem uma utilização elevada de slots, isto pode indicar que precisa de slots do BigQuery adicionais para ajudar a suportar as suas cargas de trabalho. Se quiser comprar slots através de compromissos anuais ou de 3 anos, pode começar a usar as reservas do BigQuery através da Cloud de Confiance consola ou da ferramenta de linha de comandos bq. Para mais detalhes sobre a gestão de cargas de trabalho, a execução de consultas e a arquitetura do BigQuery, consulte o artigo Migração para Cloud de Confiance: uma vista detalhada.
Segurança em Cloud de Confiance
As secções seguintes descrevem os controlos de segurança comuns do Amazon Redshift e como pode ajudar a garantir que o seu data warehouse permanece protegido numCloud de Confiance ambiente.
Gestão de identidade e de acesso
A configuração dos controlos de acesso no Amazon Redshift envolve a escrita de políticas de autorizações da API Amazon Redshift e a respetiva associação a identidades de gestão de identidade e de acesso (IAM). As autorizações da API Amazon Redshift fornecem acesso ao nível do cluster, mas não fornecem níveis de acesso mais detalhados do que o cluster. Se quiser um acesso mais detalhado a recursos como tabelas ou vistas, pode usar contas de utilizador na base de dados do Amazon Redshift.
O BigQuery usa o IAM para gerir o acesso aos recursos a um nível mais detalhado. Os tipos de recursos disponíveis no BigQuery são organizações, projetos, conjuntos de dados, tabelas, colunas e vistas. Na hierarquia de políticas IAM, os conjuntos de dados são recursos subordinados dos projetos. Uma tabela herda autorizações do conjunto de dados que a contém.
Para conceder acesso a um recurso, atribua uma ou mais funções de IAM a um utilizador, um grupo ou uma conta de serviço. As funções de organização e projeto afetam a capacidade de executar tarefas ou gerir o projeto, enquanto as funções de conjunto de dados afetam a capacidade de aceder ou modificar os dados num projeto.
O IAM fornece os seguintes tipos de funções:
- Funções predefinidas, destinadas a suportar exemplos de utilização comuns e padrões de controlo de acesso.
- Funções personalizadas, que oferecem acesso detalhado de acordo com uma lista de autorizações especificada pelo utilizador.
No IAM, o BigQuery oferece controlo de acesso ao nível da tabela. As autorizações ao nível da tabela determinam os utilizadores, os grupos e as contas de serviço que podem aceder a uma tabela ou a uma vista. Pode conceder a um utilizador acesso a tabelas ou vistas específicas sem lhe conceder acesso ao conjunto de dados completo. Para um acesso mais detalhado, também pode considerar implementar um ou mais dos seguintes mecanismos de segurança:
- Controlo de acesso ao nível da coluna, que fornece acesso detalhado a colunas confidenciais com recurso a etiquetas de políticas, ou à classificação de dados baseada em tipos.
- Máscara de dados dinâmica ao nível da coluna, que lhe permite ocultar seletivamente os dados das colunas para grupos de utilizadores, ao mesmo tempo que permite o acesso à coluna.
- Segurança ao nível da linha, que lhe permite filtrar dados e ativar o acesso a linhas específicas numa tabela com base nas condições de utilizador qualificadas.
Encriptação full disk
Além da gestão de identidades e acessos, a encriptação de dados adiciona uma camada adicional de defesa para proteger os dados. No caso de exposição de dados, os dados encriptados não são legíveis.
No Amazon Redshift, a encriptação de dados inativos e em movimento não está ativada por predefinição. A encriptação de dados em repouso tem de ser ativada explicitamente quando um cluster é iniciado ou modificando um cluster existente para usar a encriptação do serviço de gestão de chaves da AWS. A encriptação de dados em trânsito também tem de estar explicitamente ativada.
O BigQuery encripta todos os dados em repouso e em trânsito por predefinição, independentemente da origem ou de qualquer outra condição, e esta opção não pode ser desativada. O BigQuery também suporta chaves de encriptação geridas pelo cliente (CMEK) se quiser controlar e gerir chaves de encriptação de chaves no Cloud Key Management Service.
Para mais informações sobre a encriptação, Cloud de Confiance, consulte os documentos técnicos sobre a encriptação de dados em repouso e a encriptação de dados em trânsito.
Para os dados em trânsito Cloud de Confiance, os dados são encriptados e autenticados quando se movem para fora dos limites físicos controlados pela Google ou em nome da Google. Dentro destes limites, os dados em trânsito são geralmente autenticados, mas não necessariamente encriptados.
Prevenção contra a perda de dados
Os requisitos de conformidade podem limitar os dados que podem ser armazenados no Cloud de Confiance. Pode usar a proteção de dados confidenciais para analisar as suas tabelas do BigQuery para detetar e classificar dados confidenciais. Se forem detetados dados confidenciais, as transformações de desidentificação da Proteção de dados confidenciais podem ocultar, eliminar ou obscurecer de outra forma esses dados.
Migração para o Cloud de Confiance: os conceitos básicos
Use esta secção para saber mais sobre a utilização de ferramentas e pipelines para ajudar na migração.
Ferramentas de migração
O Serviço de transferência de dados do BigQuery oferece uma ferramenta automatizada para migrar o esquema e os dados do Amazon Redshift diretamente para o BigQuery. A tabela seguinte apresenta ferramentas adicionais para ajudar na migração do Amazon Redshift para o BigQuery:
| Ferramenta | Purpose |
|---|---|
| Serviço de transferência de dados do BigQuery | Faça uma transferência em lote automática dos seus dados do Amazon Redshift para o BigQuery através deste serviço totalmente gerido. |
| Serviço de transferência de armazenamento | Importe rapidamente dados do Amazon S3 para o Cloud Storage e configure um agendamento repetitivo para transferir dados através deste serviço totalmente gerido. |
gcloud |
Copie ficheiros do Amazon S3 para o Cloud Storage através desta ferramenta de linha de comandos. |
| Ferramenta de linhas de comando bq | Interaja com o BigQuery através desta ferramenta de linha de comandos. As interações comuns incluem a criação de esquemas de tabelas do BigQuery, o carregamento de dados do Cloud Storage em tabelas e a execução de consultas. |
| Bibliotecas de cliente do Cloud Storage | Copiar ficheiros do Amazon S3 para o Cloud Storage através da sua ferramenta personalizada, criada com base na biblioteca de cliente do Cloud Storage. |
| Bibliotecas de cliente do BigQuery | Interagir com o BigQuery através da sua ferramenta personalizada, criada com base na biblioteca cliente do BigQuery. |
| Programador de consultas do BigQuery | Agende consultas SQL recorrentes através desta funcionalidade integrada do BigQuery. |
| Cloud Composer | Orquestre transformações e tarefas de carregamento do BigQuery através deste ambiente do Apache Airflow totalmente gerido. |
| Apache Sqoop | Envie tarefas do Hadoop através do Sqoop e do controlador JDBC do Amazon Redshift para extrair dados do Amazon Redshift para o HDFS ou o Cloud Storage. O Sqoop é executado num ambiente do Dataproc. |
Para mais informações sobre a utilização do Serviço de transferência de dados do BigQuery, consulte o artigo Migre o esquema e os dados do Amazon Redshift.
Migração através de pipelines
A migração de dados do Amazon Redshift para o BigQuery pode seguir diferentes caminhos com base nas ferramentas de migração disponíveis. Embora a lista nesta secção não seja exaustiva, dá uma ideia dos diferentes padrões de pipeline de dados disponíveis quando move os seus dados.
Para mais informações de nível elevado sobre a migração de dados para o BigQuery através de pipelines, consulte o artigo Migre pipelines de dados.
Extrair e carregar (EL)
Pode automatizar totalmente um pipeline de EL através do Serviço de transferência de dados do BigQuery, que pode copiar automaticamente os esquemas e os dados das suas tabelas do cluster do Amazon Redshift para o BigQuery. Se quiser ter mais controlo sobre os passos do pipeline de dados, pode criar um pipeline através das opções descritas nas secções seguintes.
Use extratos de ficheiros do Amazon Redshift
- Exporte dados do Amazon Redshift para o Amazon S3.
Copie dados do Amazon S3 para o Cloud Storage através de qualquer uma das seguintes opções:
Carregue dados do Cloud Storage para o BigQuery através de qualquer uma das seguintes opções:
Use uma ligação JDBC do Amazon Redshift
Use qualquer um dos seguintes Cloud de Confiance produtos para exportar dados do Amazon Redshift através do controlador JDBC do Amazon Redshift:
-
- Modelo fornecido pela Google: JDBC para o BigQuery
-
Estabeleça a associação ao Amazon Redshift através de JDBC com o Apache Spark
Use o Sqoop e o controlador JDBC do Amazon Redshift para extrair dados do Amazon Redshift para o Cloud Storage
Extrair, transformar e carregar (ETL)
Se quiser transformar alguns dados antes de os carregar para o BigQuery, siga as mesmas recomendações de pipeline descritas na secção Extrair e carregar (EL), adicionando um passo adicional para transformar os dados antes de os carregar para o BigQuery.
Use extratos de ficheiros do Amazon Redshift
Copie dados do Amazon S3 para o Cloud Storage através de qualquer uma das seguintes opções:
Transforme e, em seguida, carregue os seus dados para o BigQuery através de qualquer uma das seguintes opções:
-
- Ler a partir do Cloud Storage
- Escreva no BigQuery
- Modelo fornecido pela Google: Texto do Cloud Storage para o BigQuery
Use uma ligação JDBC do Amazon Redshift
Use qualquer um dos produtos descritos na secção Extrair e carregar (EL), adicionando um passo adicional para transformar os seus dados antes de os carregar para o BigQuery. Modifique o pipeline para introduzir um ou mais passos para transformar os dados antes de os escrever no BigQuery.
-
- Clone o código do modelo JDBC para o BigQuery e modifique o modelo para adicionar transformações do Apache Beam.
-
- Transforme os seus dados através de qualquer um dos plug-ins do CDAP.
Extrair, carregar e transformar (ELT)
Pode transformar os seus dados através do próprio BigQuery, usando qualquer uma das opções de extração e carregamento (EL) para carregar os dados para uma tabela de preparação. Em seguida, transforma os dados nesta tabela de preparação usando consultas SQL que escrevem o respetivo resultado na tabela de produção final.
Captura de dados de alterações (CDC)
A captura de dados de alterações é um dos vários padrões de design de software usados para acompanhar as alterações de dados. É frequentemente usado no armazenamento de dados porque o armazém de dados é usado para reunir e monitorizar dados e as respetivas alterações de vários sistemas de origem ao longo do tempo.
Ferramentas de parceiros para a migração de dados
Existem vários fornecedores no espaço de extração, transformação e carregamento (ETL). Consulte o Website de parceiros do BigQuery para ver uma lista de parceiros importantes e as respetivas soluções.
Migração para o Cloud de Confiance: uma vista detalhada
Use esta secção para saber mais sobre como a arquitetura, o esquema e o dialeto SQL do seu armazém de dados afetam a migração.
Comparação de arquiteturas
O BigQuery e o Amazon Redshift baseiam-se numa arquitetura de processamento paralelo (MPP) em grande escala. As consultas são distribuídas por vários servidores para acelerar a respetiva execução. No que diz respeito à arquitetura do sistema, o Amazon Redshift e o BigQuery diferem principalmente na forma como os dados são armazenados e como as consultas são executadas. No BigQuery, o hardware e as configurações subjacentes são abstraídos. O respetivo armazenamento e computação permitem que o seu armazém de dados cresça sem qualquer intervenção da sua parte.
Computação, memória e armazenamento
No Amazon Redshift, a CPU, a memória e o armazenamento em disco estão interligados através de nós de computação, conforme ilustrado neste diagrama da documentação do Amazon Redshift. O desempenho do cluster e a capacidade de armazenamento são determinados pelo tipo e pela quantidade de nós de computação, que têm de ser configurados. Para alterar a computação ou o armazenamento, tem de redimensionar o cluster através de um processo (durante algumas horas ou até dois dias ou mais) que cria um cluster totalmente novo e copia os dados. O Amazon Redshift também oferece nós RA3 com armazenamento gerido que ajudam a separar a computação e o armazenamento. O nó maior na categoria RA3 tem um limite de 64 TB de armazenamento gerido para cada nó.
Desde o início, o BigQuery não associa a computação, a memória e o armazenamento, mas trata cada um separadamente.
A computação do BigQuery é definida por slots, uma unidade de capacidade computacional necessária para executar consultas. A Google gere toda a infraestrutura que um espaço encapsula, eliminando todas as tarefas, exceto a de escolher a quantidade adequada de espaços para as suas cargas de trabalho do BigQuery. Consulte o planeamento da capacidade para ajudar a decidir quantos espaços vai comprar para o seu data warehouse. A memória do BigQuery é fornecida por um serviço distribuído remoto, ligado a slots de computação pela rede petabit da Google, tudo gerido pela Google.
O BigQuery e o Amazon Redshift usam o armazenamento em colunas, mas o BigQuery usa variações e avanços no armazenamento em colunas. Enquanto as colunas estão a ser codificadas, são mantidas várias estatísticas sobre os dados e, posteriormente, são usadas durante a execução da consulta para compilar planos ideais e escolher o algoritmo de tempo de execução mais eficiente. O BigQuery armazena os seus dados no sistema de ficheiros distribuído da Google, onde são automaticamente comprimidos, encriptados, replicados e distribuídos. Tudo isto é feito sem afetar a capacidade de processamento disponível para as suas consultas. A separação do armazenamento do processamento permite-lhe aumentar até dezenas de petabytes no armazenamento de forma integrada, sem precisar de recursos de processamento adicionais dispendiosos. Também existem várias outras vantagens da separação da computação e do armazenamento.
Aumentar ou reduzir a escala
Quando o armazenamento ou o cálculo ficam restritos, os clusters do Amazon Redshift têm de ser redimensionados modificando a quantidade ou os tipos de nós no cluster.
Quando redimensiona um cluster do Amazon Redshift, existem duas abordagens:
- Redimensionamento clássico: o Amazon Redshift cria um cluster para o qual os dados são copiados, um processo que pode demorar algumas horas ou até dois dias ou mais para grandes quantidades de dados.
- Redimensionamento elástico: se alterar apenas o número de nós, as consultas são pausadas temporariamente e as ligações são mantidas abertas, se possível. Durante a operação de redimensionamento, o cluster é só de leitura. Normalmente, a redimensionamento elástico demora 10 a 15 minutos, mas pode não estar disponível para todas as configurações.
Como o BigQuery é uma plataforma como serviço (PaaS), só tem de se preocupar com o número de slots do BigQuery que quer reservar para a sua organização. Reserva slots do BigQuery em reservas e, em seguida, atribui projetos a estas reservas. Para saber como configurar estas reservas, consulte o artigo Planeamento da capacidade.
Execução de consultas
O motor de execução do BigQuery é semelhante ao do Amazon Redshift, uma vez que ambos orquestram a sua consulta dividindo-a em passos (um plano de consulta), executando os passos (em simultâneo, sempre que possível) e, em seguida, remontando os resultados. O Amazon Redshift gera um plano de consulta estático, mas o BigQuery não, porque otimiza dinamicamente os planos de consulta à medida que a consulta é executada. O BigQuery baralha os dados usando o respetivo serviço de memória remota, enquanto o Amazon Redshift baralha os dados usando a memória do nó de computação local. Para mais informações sobre o armazenamento de dados intermédios do BigQuery de várias fases do seu plano de consulta, consulte o artigo Execução de consultas na memória no Google BigQuery.
Gestão de cargas de trabalho no BigQuery
O BigQuery oferece os seguintes controlos para a gestão de cargas de trabalho (WLM):
- Consultas interativas, que são executadas assim que possível (esta é a predefinição).
- Consultas em lote, que são colocadas em fila em seu nome e, em seguida, iniciadas assim que os recursos inativos estiverem disponíveis no conjunto de recursos partilhados do BigQuery.
Reservas de slots através de preços com base na capacidade. Em vez de pagar por consultas a pedido, pode criar e gerir dinamicamente grupos de espaços denominados reservas e atribuir projetos, pastas ou organizações a estas reservas. Pode comprar compromissos de slots do BigQuery (a partir de um mínimo de 100) em compromissos flexíveis, mensais ou anuais para ajudar a minimizar os custos. Por predefinição, as consultas executadas numa reserva usam automaticamente ranhuras inativas de outras reservas.
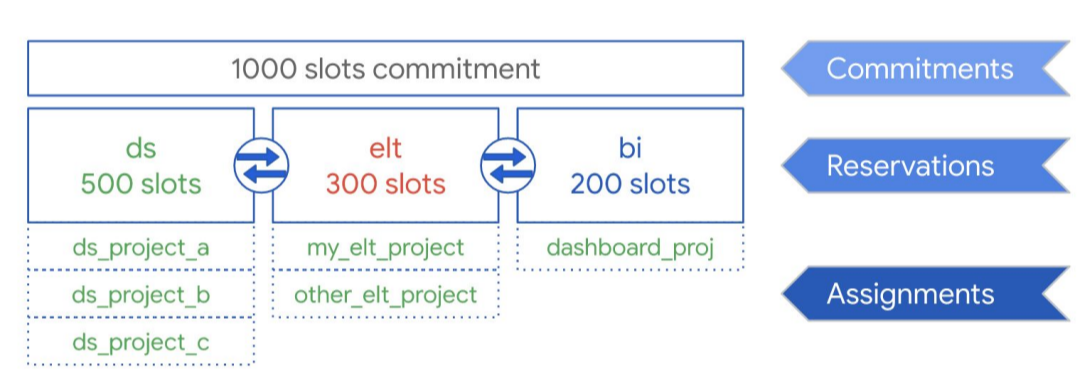
Como ilustra o diagrama seguinte, suponhamos que comprou uma capacidade de compromisso total de 1000 espaços para partilhar em três tipos de carga de trabalho: ciência de dados, ELT e inteligência empresarial (IE). Para suportar estes volumes de trabalho, pode criar as seguintes reservas:
- Pode criar o conjunto de dados ds com 500 espaços e atribuir todos os Cloud de Confiance projetos de ciência de dados a essa reserva.
- Pode criar o elt de reserva com 300 espaços e atribuir os projetos que usa para cargas de trabalho de ELT a essa reserva.
- Pode criar a bi de reserva com 200 vagas e atribuir projetos associados às suas ferramentas de BI a essa reserva.
Esta configuração é apresentada no gráfico seguinte:
Em vez de distribuir reservas para as cargas de trabalho da sua organização, por exemplo, para produção e testes, pode optar por atribuir reservas a equipas ou departamentos individuais, consoante o seu exemplo de utilização.
Para mais informações, consulte o artigo Gestão de cargas de trabalho com reservas.
Gestão de cargas de trabalho no Amazon Redshift
O Amazon Redshift oferece dois tipos de gestão de cargas de trabalho (WLM):
- Automático: Com o WLM automático, o Amazon Redshift gere a simultaneidade de consultas e a atribuição de memória. São criadas até oito filas com os identificadores de classe de serviço 100 a 107. A GCL automática determina a quantidade de recursos que as consultas precisam e ajusta a simultaneidade com base na carga de trabalho. Para mais informações, consulte Prioridade da consulta.
- Manual: Por outro lado, o WLM manual requer que especifique valores para a simultaneidade de consultas e a atribuição de memória. A predefinição para o GCL manual é a concorrência de cinco consultas, e a memória é dividida igualmente entre todas as cinco.
Quando a escalabilidade de concorrência está ativada, o Amazon Redshift adiciona automaticamente capacidade adicional do cluster quando precisa dela para processar um aumento nas consultas de leitura simultâneas. O dimensionamento da simultaneidade tem determinadas considerações regionais e de consultas. Para mais informações, consulte o artigo Candidatos à escalabilidade da simultaneidade.
Configurações do conjunto de dados e da tabela
O BigQuery oferece várias formas de configurar os seus dados e tabelas, como particionamento, agrupamento e localidade dos dados. Estas configurações podem ajudar a manter tabelas grandes e reduzir o carregamento de dados geral e o tempo de resposta das suas consultas, aumentando assim a eficiência operacional das suas cargas de trabalho de dados.
Partição
Uma tabela particionada é uma tabela dividida em segmentos, denominados partições, que facilitam a gestão e a consulta dos seus dados. Normalmente, os utilizadores dividem tabelas grandes em muitas partições mais pequenas, em que cada partição contém dados relativos a um dia. A gestão de partições é um fator determinante do desempenho e do custo do BigQuery quando se consultam dados num intervalo de datas específico, uma vez que ajuda o BigQuery a analisar menos dados por consulta.
Existem três tipos de particionamento de tabelas no BigQuery:
- Tabelas particionadas por tempo de ingestão: As tabelas são particionadas com base no tempo de ingestão dos dados.
- Tabelas particionadas por coluna:
As tabelas são particionadas com base numa coluna
TIMESTAMPouDATE. - Tabelas particionadas por intervalo de números inteiros: As tabelas são particionadas com base numa coluna de números inteiros.
Uma tabela particionada por tempo baseada em colunas elimina a necessidade de manter a consciência da partição independentemente da filtragem de dados existente na coluna associada. Os dados escritos numa tabela particionada por tempo baseada em colunas são entregues automaticamente à partição adequada com base no valor dos dados. Da mesma forma, as consultas que expressam filtros na coluna de particionamento podem reduzir os dados gerais analisados, o que pode gerar um desempenho melhorado e um custo de consulta reduzido para consultas a pedido.
A partição baseada em colunas do BigQuery é semelhante à partição baseada em colunas do Amazon Redshift, com uma motivação ligeiramente diferente. O Amazon Redshift usa a distribuição de chaves baseada em colunas para tentar manter os dados relacionados armazenados em conjunto no mesmo nó de computação, minimizando, em última análise, a reorganização de dados que ocorre durante as junções e as agregações. O BigQuery separa o armazenamento da computação, pelo que tira partido da partição baseada em colunas para minimizar a quantidade de dados que os slots leem do disco.
Assim que os trabalhadores de slots leem os respetivos dados do disco, o BigQuery pode determinar automaticamente a divisão de dados mais otimizada e reparticionar rapidamente os dados através do serviço de mistura na memória do BigQuery.
Para mais informações, consulte o artigo Introdução às tabelas particionadas.
Chaves de clustering e ordenação
O Amazon Redshift suporta a especificação de colunas de tabelas como chaves de ordenação compostas ou intercaladas. No BigQuery, pode especificar chaves de ordenação compostas através da agrupamento em clústeres da sua tabela. As tabelas agrupadas do BigQuery melhoram o desempenho das consultas porque os dados da tabela são automaticamente ordenados com base no conteúdo de até quatro colunas especificadas no esquema da tabela. Estas colunas são usadas para colocar dados relacionados. A ordem das colunas de agrupamento especificadas é importante porque determina a ordem de ordenação dos dados.
A agrupagem pode melhorar o desempenho de determinados tipos de consultas, como consultas que usam cláusulas de filtro e consultas que agregam dados. Quando os dados são escritos numa tabela agrupada por uma tarefa de consulta ou uma tarefa de carregamento, o BigQuery ordena automaticamente os dados através dos valores nas colunas de agrupamento. Estes valores são usados para organizar os dados em vários blocos no armazenamento do BigQuery. Quando envia uma consulta que contém uma cláusula que filtra dados com base nas colunas de agrupamento, o BigQuery usa os blocos ordenados para eliminar as análises de dados desnecessários.
Da mesma forma, quando envia uma consulta que agrega dados com base nos valores nas colunas de agrupamento, o desempenho é melhorado porque os blocos ordenados colocam as linhas com valores semelhantes.
Use a agrupagem nas seguintes circunstâncias:
- As chaves de ordenação compostas são configuradas nas tabelas do Amazon Redshift.
- A filtragem ou a agregação são configuradas em função de colunas específicas nas suas consultas.
Quando usa o clustering e a partição em conjunto, os dados podem ser particionados por uma coluna de data, data/hora ou número inteiro e, em seguida, agrupados num conjunto diferente de colunas (até um total de quatro colunas agrupadas). Neste caso, os dados em cada partição são agrupados com base nos valores das colunas de agrupamento.
Quando especifica chaves de ordenação em tabelas no Amazon Redshift, consoante a carga no sistema, o Amazon Redshift inicia automaticamente a ordenação usando a capacidade de computação do seu próprio cluster. Pode até ter de executar manualmente o comando
VACUUM
se quiser ordenar totalmente os dados da tabela o mais rapidamente possível, por exemplo, após um carregamento de dados grande. O BigQuery
processa automaticamente
esta ordenação por si e não usa os seus slots do BigQuery
atribuídos, pelo que não afeta o desempenho de nenhuma das suas consultas.
Para mais informações sobre como trabalhar com tabelas agrupadas, consulte a Introdução às tabelas agrupadas.
Chaves de distribuição
O Amazon Redshift usa chaves de distribuição para otimizar a localização de blocos de dados para executar as respetivas consultas. O BigQuery não usa chaves de distribuição porque determina e adiciona automaticamente fases num plano de consulta (enquanto a consulta está em execução) para melhorar a distribuição de dados entre os trabalhadores de consultas.
Fontes externas
Se usar o Amazon Redshift Spectrum para consultar dados no Amazon S3, pode usar de forma semelhante a funcionalidade de origem de dados externa do BigQuery para consultar dados diretamente a partir de ficheiros no Cloud Storage.
Além de consultar dados no Cloud Storage, o BigQuery oferece funções de consulta federada para consultar diretamente a partir dos seguintes produtos:
- Cloud SQL (MySQL ou PostgreSQL totalmente gerido)
- Bigtable (NoSQL totalmente gerido)
- Google Drive (CSV, JSON, Avro, Sheets)
Localidade dos dados
Pode criar os seus conjuntos de dados do BigQuery em localizações regionais e multirregionais, enquanto o Amazon Redshift só oferece localizações regionais. O BigQuery determina a localização para executar as tarefas de carregamento, consulta ou extração com base nos conjuntos de dados referenciados no pedido. Consulte as considerações sobre a localização do BigQuery para ver sugestões sobre como trabalhar com conjuntos de dados regionais e multirregionais.
Mapeamento de tipos de dados no BigQuery
Os tipos de dados do Amazon Redshift diferem dos tipos de dados do BigQuery. Para mais detalhes sobre os tipos de dados do BigQuery, consulte a documentação oficial.
O BigQuery também suporta os seguintes tipos de dados, que não têm um análogo direto no Amazon Redshift:
Comparação de SQL
O GoogleSQL suporta a conformidade com a norma SQL 2011 e tem extensões que suportam consultas de dados aninhados e repetidos. O SQL do Amazon Redshift baseia-se no PostgreSQL, mas tem várias diferenças detalhadas na documentação do Amazon Redshift. Para uma comparação detalhada entre a sintaxe e as funções do Amazon Redshift e do GoogleSQL, consulte o guia de tradução de SQL do Amazon Redshift.
Pode usar o tradutor de SQL em lote para converter scripts e outro código SQL da sua plataforma atual para o BigQuery.
Após a migração
Uma vez que migrou scripts que não foram concebidos a pensar no BigQuery, pode optar por implementar técnicas para otimizar o desempenho das consultas no BigQuery. Para mais informações, consulte o artigo Introdução à otimização do desempenho das consultas.
O que se segue?
- Receba instruções passo a passo para migrar o esquema e os dados do Amazon Redshift.
- Receba instruções passo a passo para migrar o Amazon Redshift para o BigQuery com a VPC.