
BigQuery DataFrames の概要
BigQuery DataFrames は、使い慣れた Python API を使用して BigQuery データ処理を活用できるオープンソースの Python ライブラリ群です。BigQuery DataFrames では、BigQuery エンジンをベースとした Pythonic DataFrame を使用できます。BigQuery DataFrames で SQL 変換を経て処理を BigQuery にプッシュダウンすることで、pandas API と scikit-learn API が実装されます。これにより、Python API を使用して、BigQuery でテラバイト単位のデータの探索と処理、ML モデルのトレーニングを行えます。
次の図は、BigQuery DataFrames のワークフローを示しています。
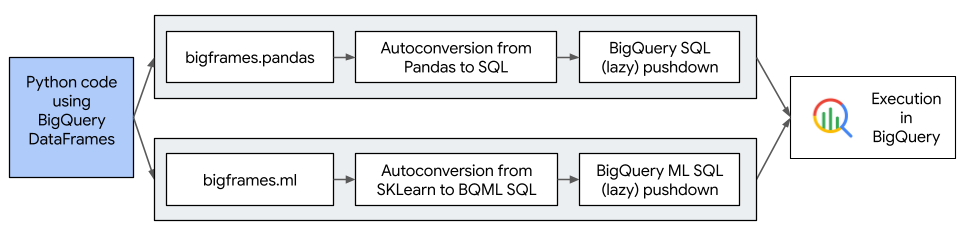
BigQuery DataFrames のメリット
BigQuery DataFrames を使うことで次の処理を行えます。
- BigQuery API と BigQuery ML API への透過的な SQL 変換によって実装された、750 を超える pandas API と scikit-learn API を使用できます。
- クエリの遅延実行により、パフォーマンスが向上します。
- ユーザー定義の Python 関数でデータ変換を拡張し、 Cloud de Confiance by S3NSでデータを処理できるようになります。これらの関数は、BigQuery のリモート関数として自動的にデプロイされます。
- Vertex AI とのインテグレーションにより、Gemini モデルを使用してテキストを生成できます。
ライセンス
BigQuery DataFrames には Apache-2.0 ライセンスが付随します。
BigQuery DataFrames には、次のサードパーティ パッケージから派生したコードも含まれています。
詳細については、BigQuery DataFrames GitHub リポジトリの third_party/bigframes_vendored ディレクトリをご覧ください。
割り当てと上限
- BigQuery の割り当ては、ハードウェア、ソフトウェア、ネットワーク コンポーネントを含む BigQuery DataFrames に適用されます。
- 一連の pandas API と scikit-learn API がサポートされています。詳細については、サポートされている pandas API をご覧ください。
- セッションのクリーンアップの一環として、自動的に作成された Cloud Run functions は、すべて明示的にクリーンアップする必要があります。詳細については、サポートされている pandas API をご覧ください。
料金
- BigQuery DataFrames は、追加料金なしでダウンロードできるオープンソースの Python ライブラリ群です。
- BigQuery DataFrames では、BigQuery、Cloud Run functions、Vertex AI などのCloud de Confiance by S3NS サービスが使用されます。これらのサービスには別途費用が発生します。
- 通常の使用中、BigQuery DataFrames は中間結果などの一時データを BigQuery テーブルに保存します。これらのテーブルはデフォルトで 7 日間保持され、テーブルに保存されたデータは課金の対象になります。テーブルは、
bf.options.bigquery.projectオプションで指定した Cloud de Confiance プロジェクトの_anonymous_データセットに作成されます。
次のステップ
- BigQuery DataFrames クイックスタートを試す。
- BigQuery DataFrames を使用する方法を確認する。
- BigQuery DataFrames を使用してグラフを可視化する方法を確認する。
dbt-bigqueryアダプターの使用方法を確認する。