
このチュートリアルでは、Amazon Elastic Compute Cloud(AWS EC2)上の Microsoft SQL Server データベースを Compute Engine に移行するために使用できるさまざまな方法について説明します。
このページでは、次のアプローチについて説明します。
移行方法ごとにメリットとデメリットが異なります。最適な移行戦略は、お客様の特定の状況と優先事項によって異なります。次の検討事項に基づいて、最適な移行方法を選択することをおすすめします。
可用性: 移行アプローチが SQL Server データベースのすべてのバージョンとライセンスでサポートされているかどうかを検討します。
データベースのサイズ: データベースのサイズは、実行可能な移行オプションに大きな影響を与える可能性があります。サイズが大きいデータベースでは、サイズが小さいデータベースとは異なる戦略が必要になる場合があります。移行アプローチを選択する際は、データ転送時間、潜在的なダウンタイム、リソース要件を考慮してください。
許容されるダウンタイム: 移行中に許容できるダウンタイムのレベルは重要な要素です。方法によっては、ダウンタイムを最小限に抑えることができますが、ダウンタイムが長くなる方法もあります。許容できるダウンタイムの移行方法を検討してください。
複雑さ: データベース スキーマ、アプリケーションの依存関係、環境全体の複雑さは、移行アプローチに影響する可能性があります。選択した移行方法が、SQL エージェント ジョブ、リンクされたサーバー、権限、ユーザー オブジェクトなどのデータベース以外のオブジェクトの移行をサポートしていることを確認します。
費用: 移行の費用面も考慮する必要があります。移行方法によって、データ転送、コンピューティング リソース、その他のサービスに関連する費用は異なります。最適な移行方法を検討します。
データのセキュリティとコンプライアンス: 選択した移行方法がデータのセキュリティとコンプライアンスの要件を遵守していることを確認します。データの暗号化、アクセス制御、データに適用される業界固有の要件を検討してください。
目標
このチュートリアルでは、次のタスクを完了して、SQL Server データベースを AWS EC2 から Compute Engine に移行する方法について説明します。
- Compute Engine に SQL Server インスタンスをデプロイする
- フル バックアップと復元を使用して移行する
- BACPAC ファイルを使用して移行する
- Always On 可用性グループを使用して移行する
- 分散可用性グループを使用して移行する
費用
このチュートリアルでは、以下を含む、 Cloud de Confiance by S3NSの課金対象となるコンポーネントを使用します。
料金計算ツールを使うと、予想使用量に基づいて費用の見積もりを出すことができます。
始める前に
始める前に、次のタスクを完了します。
-
In the Cloud de Confiance console, on the project selector page, select or create a Cloud de Confiance project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Cloud de Confiance project.
-
In the Cloud de Confiance console, activate Cloud Shell.
プロジェクトとネットワークを準備する
移行用に SQL Server をデプロイするために Cloud de Confiance プロジェクトと Virtual Private Cloud(VPC)を準備するには、次の操作を行います。
Cloud de Confiance コンソールで、Cloud Shell をアクティブにするアイコン
 をクリックして Cloud Shell を開きます。
をクリックして Cloud Shell を開きます。デフォルトのプロジェクト ID を設定します。
gcloud config set project
PROJECT_IDPROJECT_IDは、 Cloud de Confiance プロジェクトの ID に置き換えます。デフォルトのリージョンを設定します。
gcloud config set compute/region
REGIONREGIONは、デプロイするリージョンの ID に置き換えます。デフォルト ゾーンを設定します。
gcloud config set compute/zone
ZONEZONEは、デプロイするゾーンの ID に置き換えます。ゾーンが、前の手順で指定したリージョンで有効であることを確認します。
Compute Engine に SQL Server インスタンスを作成する
SQL Server データベースを Compute Engine に移行する前に、Compute Engine でデータベースをホストする仮想マシン(VM)を作成する必要があります。
次のコマンドを使用して、Compute Engine に SQL Server インスタンスを作成します。
2022 Standard
gcloud compute instances create sql-server-std-migrate-vm \ --project=
PROJECT_ID\ --zoneZONE\ --machine-type n4-standard-8 \ --subnetSUBNET_NAME\ --create-disk=auto-delete=yes,boot=yes,device-name=node-1,image=projects/windows-sql-cloud/global/images/sql-2022-standard-windows-2022-dc-v20250213,mode=rw,size=50,type=projects/PROJECT_ID/zones/ZONE/diskTypes/pd-balanced \ --scopes=https://www.googleapis.com/auth/compute,https://www.googleapis.com/auth/servicecontrol,https://www.googleapis.com/auth/service.management.readonly,https://www.googleapis.com/auth/logging.write,https://www.googleapis.com/auth/monitoring.write,https://www.googleapis.com/auth/trace.append,https://www.googleapis.com/auth/devstorage.read_write次のように置き換えます。
PROJECT_ID: Cloud de Confiance プロジェクトの ID。ZONE: ゾーンの ID。SUBNET_NAME:: VPC サブネットの名前。
2022 Enterprise
gcloud compute instances create sql-server-ent-migrate-vm \ --project=
PROJECT_ID\ --zoneZONE\ --machine-type n4-standard-8 \ --subnetSUBNET_NAME\ --create-disk=auto-delete=yes,boot=yes,device-name=node-1,image=projects/windows-sql-cloud/global/images/sql-2022-enterprise-windows-2022-dc-v20250213,mode=rw,size=50,type=projects/PROJECT_ID/zones/ZONE/diskTypes/pd-balanced \ --scopes=https://www.googleapis.com/auth/compute,https://www.googleapis.com/auth/servicecontrol,https://www.googleapis.com/auth/service.management.readonly,https://www.googleapis.com/auth/logging.write,https://www.googleapis.com/auth/monitoring.write,https://www.googleapis.com/auth/trace.append,https://www.googleapis.com/auth/devstorage.read_write次のように置き換えます。
PROJECT_ID: Cloud de Confiance プロジェクトの ID。ZONE: ゾーンの ID。SUBNET_NAME:: VPC サブネットの名前。
Compute Engine での SQL Server インスタンスの作成の詳細については、SQL Server インスタンスを作成するをご覧ください。
SQL Server VM を構成して接続する
SQL Server VM を構成して接続する手順は次のとおりです。
アカウントに Windows 初期パスワードを設定します。
Cloud de Confiance コンソールで、[VM インスタンス] ページに移動します。
SQL Server VM の名前をクリックします。
[Windows パスワードを設定] ボタンをクリックします。
新しい Windows パスワードを設定するよう求められたら、パスワードを入力して [設定] をクリックします。
ユーザー名とパスワードを保存します。
SQL Server VM に接続します。
[VM インスタンス] ページの SQL Server VM のパブリック IP アドレスと、前の手順で保存した認証情報を使用し、Microsoft リモート デスクトップ(RDP)から SQL Server VM に接続します。
管理者として SQL Server Management Studio(SSMS)を実行します。
[Trust server certificate] チェックボックスがオンになっていることを確認して、[接続] をクリックします。
これで SQL Server VM がデータベース移行に使用できる状態になりました。SQL Server VM に接続して管理するための新しいユーザー ログインを作成するには、ログインを作成するをご覧ください。
データベースのフル バックアップと復元
データベースのフル バックアップと復元は、データベース移行の最も一般的な方法であり、最も簡単な方法です。このアプローチでは、SQL Server データベースのフル バックアップが移行元の環境から取得され、移行先の Cloud de Confiance by S3NS 環境に復元されます。この方法は比較的簡単ですが、バックアップの作成と復元に時間がかかるため、大規模なデータベースでは時間がかかる可能性があります。
このセクションでは、SSMS を使用してサンプルの AdventureWorks2022 データベースを使用して SQL Server データベースをエクスポートする方法について説明します。
データベースのフル バックアップを作成する
データベースのフル バックアップを作成するには、次の操作を行います。
Microsoft RDP を使用して AWS EC2 VM にログインします。
SSMS を使用して SQL Server に接続します。
Object Explorer で databases フォルダを開きます。
データベース名を右クリックし、メニューから [Tasks] をクリックします。
[Back Up] をクリックしてデータベース バックアップ ウィザードを開きます。
バックアップするデータベース名と、バックアップの種類がフル バックアップに設定されていることを確認します。
フル バックアップの宛先の下にある [Add] をクリックします。
省略記号アイコン(...)をクリックして、バックアップ ファイルのフォルダと名前を選択します。
[OK] をクリックしてファイル名を設定し、もう一度 [OK] をクリックして保存先を設定します。
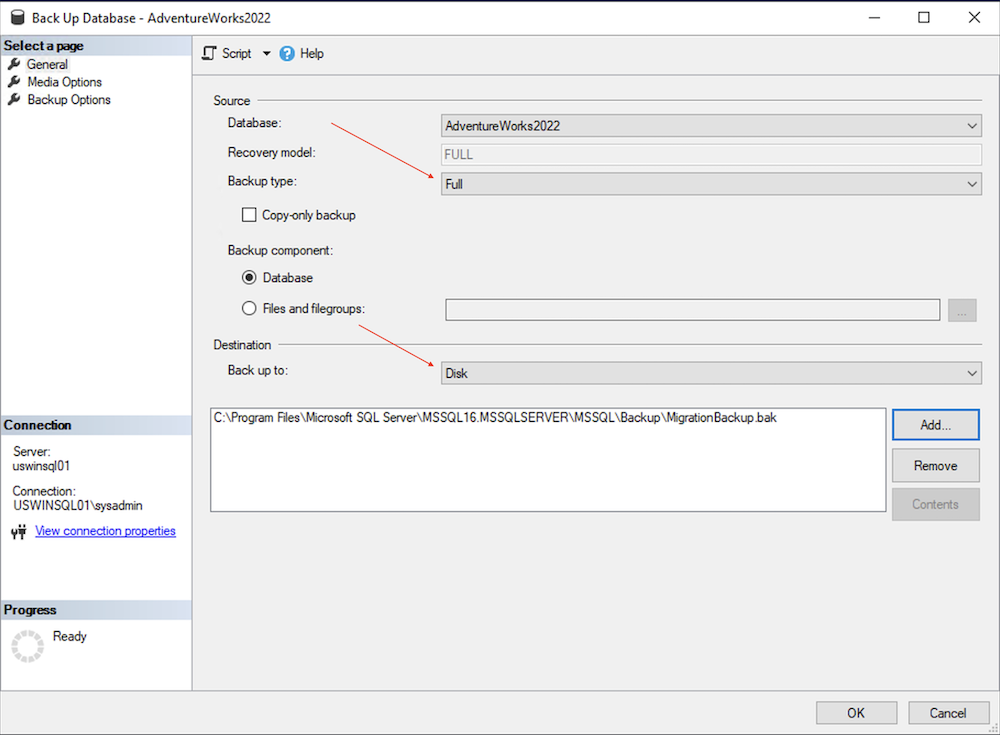
[OK] をクリックしてデータベースのバックアップを開始し、バックアップが完了するまで待ちます。
バックアップ プロセスが完了すると、バックアップ ファイルが作成されます。このバックアップ ファイルを使用して、データベースの内容を Compute Engine VM に移行できます。
[OK] をクリックして、データベース バックアップ ウィザードを終了します。
バックアップ ファイルを Compute Engine VM に転送する
SQL Server データベース コンテンツを移行するには、前の手順で作成したバックアップ ファイルを、作成した Compute Engine VM に転送する必要があります。さまざまな転送オプションについては、Windows VM にファイルを転送するをご覧ください。
バックアップ ファイルから SQL Server データベースを復元する
バックアップ ファイルからデータベースを復元する手順は次のとおりです。
RDP を使用して Compute Engine VM にログインします。
SSMS を使用して SQL Server に接続します。
Object Explorer で [Databases] フォルダを右クリックし、[Restore Database] をクリックします。
[Source] で [Device] と省略記号アイコン(...)をクリックして、[Select backup device] ページを開きます。
バックアップ メディアの種類が [File] に設定されていることを確認して、[Add] をクリックしてバックアップ ファイルを選択します。
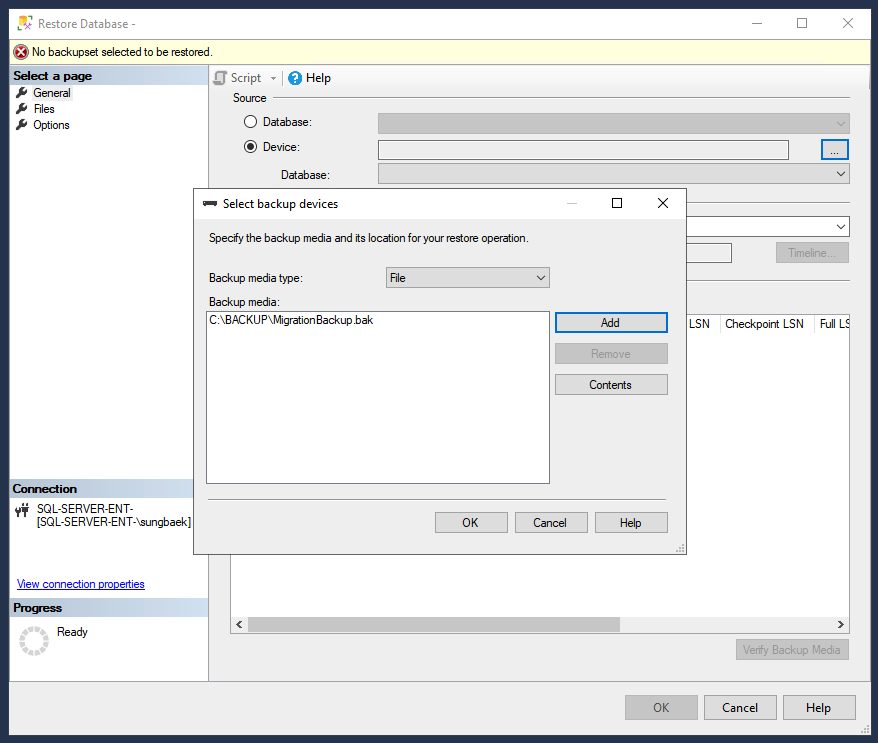
[OK] をクリックして、バックアップ ファイルを復元デバイスとして設定します。
[OK] をクリックしてデータベースを復元します。
プロセスが完了すると、データベースが Compute Engine の移行先 SQL Server に移行されます。
プロセスが正常に完了したかどうかを確認するには、Object Explorer で databases フォルダを開き、移行されたデータベースが表示されるかどうかを確認します。
BACPAC ファイルを使用して移行する
バックアップ パッケージ(BACPAC)ファイルは、SQL Server データベースの論理表現です。移行元の AWS 環境からエクスポートして、移行先の Cloud de Confiance by S3NS 環境にインポートできます。通常、この方法は小規模なデータベースではフル バックアップと復元よりも高速ですが、非常に大規模なデータベースや依存関係が複雑なデータベースには適さない場合があります。
以降のセクションでは、BACPAC ファイルを使用して SQL Server データベースを移行する方法について説明します。
BACPAC エクスポートを作成する
BACPAC エクスポートを作成するには、次の操作を行います。
Microsoft RDP を使用して AWS EC2 VM にログインします。
SSMS を使用して SQL Server に接続します。
Object Explorer で databases フォルダを開きます。
データベース名を右クリックして、[Tasks] をクリックします。
[Export Data-tier Application] をクリックして、エクスポート ウィザードを開きます。
[Next] をクリックします。
[Save to local disk] オプションで [Browse] をクリックし、BACPAC ファイルを選択します。
[Advanced] タブをクリックし、エクスポートするスキーマを選択します。
[Next] をクリックして概要に進みます。
[Finish] をクリックして BACPAC ファイルをエクスポートし、エクスポートが完了するまで待ちます。
[Close] をクリックしてウィザードを終了します。
前の手順で作成した BACPAC ファイルを、Compute Engine の宛先 VM に転送します。転送オプションについては、Windows VM にファイルを転送するをご覧ください。
BACPAC ファイルから SQL Server データベースを復元する
BACPAC ファイルからデータベースを復元する手順は次のとおりです。
RDP を使用して Compute Engine VM にログインします。
SSMS を使用して SQL Server に接続します。
Object Explorer で Databases フォルダを右クリックし、[Import Data-tier Application] をクリックします。
[Next] をクリックします。
[Browse] をクリックして、復元する BACPAC ファイルを選択し、[Next] をクリックします。
新しいデータベース名を確認して、[Next] をクリックします。
[Finish] をクリックし、インポートが完了するまで待ちます。
[Close] をクリックしてウィザードを終了します。
プロセスが正常に完了したかどうかを確認するには、Object Explorer で databases フォルダを開き、移行されたデータベースが表示されるかどうかを確認します。
Always On 可用性グループを使用して移行する
AOAG は、SQL Server の高可用性と障害復旧の機能です。AOAG を使用すると、既存の AOAG クラスタ、スタンドアロンの SQL Server、Windows Server フェイルオーバー クラスタ(WSFC)を移行できます。この方法では、宛先の Cloud de Confiance by S3NS 環境にデータベースのレプリカが作成され、ソースとターゲット間でデータが同期されます。同期が完了すると、移行先の Cloud de Confiance by S3NS 環境のレプリカをプライマリにできます。この方法ではダウンタイムを最小限に抑えることができますが、追加の構成と設定が必要です。ダウンタイムを大幅に許容できる簡単な移行の場合は、他の方法のほうが簡単で、費用対効果が高い場合があります。
始める前に
移行を開始する前に、次のことを確認してください。
データの安全でシームレスな移行を確保するには、AWS と Cloud de Confiance by S3NS間にピアリング接続を確立します。詳細については、 Cloud de Confiance by S3NS と AWS の間に HA VPN 接続を作成するをご覧ください。
移行元のデータベースがスタンドアロン モードで実行されており、ソースサーバーと移行先サーバーの両方が Active Directory(AD)に参加していることを確認します。移行元のデータベースが AOAG を使用する WSFC クラスタの一部である場合は、分散可用性グループを使用して移行するをご覧ください。
移行元の SQL Server データベースのすべての暗号鍵が、AOAG に参加するすべての SQL Server インスタンスにインストールされていることを確認します。
AOAG の一部となるように SQL Server を準備する
SQL Server を AOAG に追加するには、グループに追加するすべての SQL Server インスタンスで AOAG 機能を有効にする必要があります。
AOAG に追加するすべての SQL Server VM で AOAG 機能を有効にするには、次の操作を行います。
SQL Server で AOAG を有効にします。
RDP を使用して SQL Server VM にログインします。
管理者モードで PowerShell を開きます。
次のコマンドを実行して、SQL Server で AOAG を有効にします。
Enable-SqlAlwaysOn -ServerInstance $env:COMPUTERNAME -Force
次のコマンドを実行して、データ レプリケーション用のファイアウォール ポートを開きます。
netsh advfirewall firewall add rule name="Allow SQL Server replication" dir=in action=allow protocol=TCP localport=5022
AOAG に追加するすべての SQL Server VM に対して手順 1 を繰り返します。
AD に SQL Server の新しいユーザーを作成します。
$Credential = Get-Credential -UserName sql_server -Message 'Enter password' New-ADUser ` -Name "sql_server" ` -Description "SQL Admin account." ` -AccountPassword $Credential.Password ` -Enabled $true -PasswordNeverExpires $true
AOAG に含まれるすべての SQL Server インスタンスで、次の操作を行います。
- SQL Server 構成マネージャーを開きます。
- ナビゲーション パネルで [SQL Server Services] を選択します。
- サービスのリストで [SQL Server(MSSQLSERVER)] を右クリックし、[プロパティ] を選択します。
- [Log on as] でアカウントを次のように変更します。
- Account name:
DOMAIN\sql_server。DOMAIN は AD ドメインの NetBIOS 名です。 - Password: このセクションの前のステップ 2 で選択したパスワードを入力します。
- Account name:
[OK] をクリックします。
SQL Server の再起動を求めるプロンプトが表示されたら、[Yes] を選択します。
SQL Server がドメイン ユーザー アカウントで実行されるようになりました。
SQL Server データベースのミラーリング エンドポイントを設定する
AOAG のエンドポイントを作成するには、次の操作を行います。
移行元の SQL Server データベースが透過的データ暗号化(TDE)で暗号化されている場合は、この手順に沿って証明書と鍵をバックアップして転送し、移行先の SQL Server にインストールします。
SSMS を使用して、AWS のソース データベースにログインします。
次の T-SQL コマンドを実行して、可用性グループのエンドポイントを作成します。
USE [master] GO CREATE LOGIN [
NET_DOMAIN\sql_server] FROM WINDOWS GO USE [DATABASE_NAME] GO CREATE USER [NET_DOMAIN\sql_server] FOR LOGIN [NET_DOMAIN\sql_server] GO USE [master] GO CREATE ENDPOINT migration_endpoint STATE=STARTED AS TCP (LISTENER_PORT=5022) FOR DATABASE_MIRRORING (ROLE=ALL); GO GRANT CONNECT ON ENDPOINT::[migration_endpoint] TO [NET_DOMAIN\sql_server] GONET_DOMAINは AD ドメインの NetBIOS 名に置き換え、DATABASE_NAMEは移行するデータベースの名前に置き換えます。SSMS を使用して移行先の Cloud de Confiance by S3NS 上の SQL Server に接続し、次の T-SQL コマンドを実行してデータベース ミラーリング エンドポイントを作成します。
CREATE LOGIN [
NET_DOMAIN\sql_server] FROM WINDOWS GO CREATE ENDPOINT migration_endpoint STATE=STARTED AS TCP (LISTENER_PORT=5022) FOR DATABASE_MIRRORING (ROLE=ALL); GO GRANT CONNECT ON ENDPOINT::[migration_endpoint] TO [NET_DOMAIN\sql_server] GONET_DOMAINは、AD ドメインの NetBIOS 名に置き換えます。SSMS の Object Explorer で、[Server Objects] > [Endpoints] > [Database Mirroring] に移動して、エンドポイントを確認します。
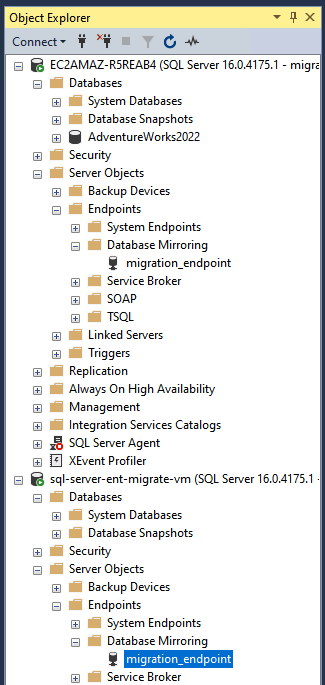
AOAG を作成する
AOAG を作成する手順は次のとおりです。
SSMS を使用して、AWS のソース データベースにログインします。
次の T-SQL コマンドを実行して、データベースの復旧モードを完全復旧に設定し、フル バックアップを行います。
USE [master] GO ALTER DATABASE [
DATABASE_NAME] SET RECOVERY FULL; BACKUP DATABASE [DATABASE_NAME] TO DISK = N'C:\Program Files\Microsoft SQL Server\MSSQL16.MSSQLSERVER\MSSQL\Backup\DATABASE_NAME.bak';DATABASE_NAMEは、移行するデータベースの名前に置き換えます。次の T-SQL コマンドを実行して、AOAG を作成します。
USE [master] GO CREATE AVAILABILITY GROUP [migration-ag] WITH ( AUTOMATED_BACKUP_PREFERENCE = SECONDARY, DB_FAILOVER = OFF, DTC_SUPPORT = NONE, REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT = 0 ) FOR DATABASE [DATABASE_NAME] REPLICA ON N'SOURCE_SERVERNAME' WITH ( ENDPOINT_URL = 'TCP://SOURCE_HOSTNAME:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, BACKUP_PRIORITY = 50, SEEDING_MODE = AUTOMATIC, SECONDARY_ROLE(ALLOW_CONNECTIONS = READ_ONLY) ), N'DEST_SERVERNAME' WITH ( ENDPOINT_URL = 'TCP://DEST_HOSTNAME:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, BACKUP_PRIORITY = 50, SEEDING_MODE = AUTOMATIC, SECONDARY_ROLE(ALLOW_CONNECTIONS = READ_ONLY) ); GO次のように置き換えます。
DATABASE_NAME: 移行するデータベースの名前。SOURCE_SERVERNAME: 移行元データベースのサーバー名。DEST_SERVERNAME: 宛先データベースのサーバー名。SOURCE_HOSTNAME: 移行元の完全修飾ドメイン名(FQDN)。DEST_HOSTNAME: 移行先の FQDN。
移行先のデータベースで次の T-SQL コマンドを実行して、AOAG に追加します。
USE [master] GO ALTER AVAILABILITY GROUP [migration-ag] JOIN WITH (CLUSTER_TYPE = EXTERNAL); ALTER AVAILABILITY GROUP [migration-ag] GRANT CREATE ANY DATABASE; GO
Object Explorer で、または次の T-SQL コマンドを実行して、新しく作成された AOAG とデータベースの状態を確認します。
SELECT * FROM sys.dm_hadr_availability_group_states GO
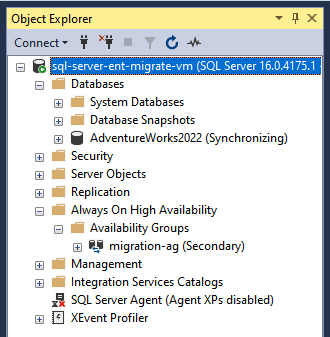
SQL Server AOAG が構成され、AWS と Cloud de Confiance by S3NSの間で同期が維持されます。次のステップとして、高可用性と障害復旧のために WSFC とリスナーを構成する必要があります。詳細については、Windows Server フェイルオーバー クラスタリングと SQL Server と可用性グループ リスナーとはをご覧ください。
分散可用性グループを使用して移行する
分散型可用性グループは、2 つの別々の可用性グループにまたがる特別なタイプの可用性グループです。地理的に分散したロケーション全体で高可用性と障害復旧機能を提供するように設計されています。このアーキテクチャでは、プライマリ可用性グループとセカンダリ可用性グループ間でシームレスなデータ レプリケーションとフェイルオーバーが可能になり、これはデータ移行に最適な方法です。詳細については、分散可用性グループをご覧ください。
以降のセクションでは、分散可用性グループを使用して SQL Server データベースを移行する方法について説明します。
始める前に
AWS で実行されている仮想ネットワーク名(VNN)リスナーを使用する可用性グループを使用する SQL Server の WSFC があることを確認します。
移行先の環境を準備する
移行先の環境を準備する手順は次のとおりです。
Cloud de Confiance by S3NSで内部ロードバランサを使用して可用性グループを使用する SQL Server を使用して WSFC を構成するには、内部ロードバランサを使用して同期 commit を行う SQL Server Always On 可用性グループを構成するをご覧ください。
Object Explorer で、
bookshelf-agが作成され、bookshelfデータベースを複製していることを確認します。検証が完了したら、次の手順に沿って、フェイルオーバー クラスタ内の両方のノードから可用性グループとデータベースの両方を削除します。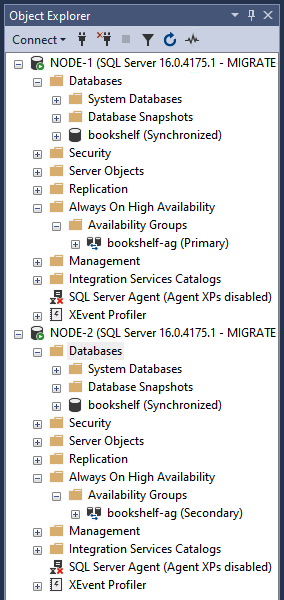
SSMS で
node-1に接続し、bookshelfリスナーの IP アドレスを保存します。SELECT * FROM sys.availability_group_listeners
次の T-SQL コマンドを実行して、
bookshelf-ag可用性グループとbookshelfデータベースを削除します。USE master GO DROP AVAILABILITY GROUP [bookshelf-ag] GO ALTER DATABASE [bookshelf] SET SINGLE_USER WITH ROLLBACK IMMEDIATE GO DROP DATABASE [bookshelf] GO
SSMS で
node-2に対して次の T-SQL を実行して、複製されたデータベースを削除します。USE master GO DROP DATABASE [bookshelf] GO
分散可用性グループを作成する
分散可用性グループに使用する新しい可用性グループを作成するには、次の操作を行います。
node-1で、次の T-SQL コマンドを実行します。USE master GO CREATE AVAILABILITY GROUP [gcp-dest-ag] FOR REPLICA ON N'NODE-1' WITH ( ENDPOINT_URL = N'TCP://NODE-1:5022', FAILOVER_MODE = MANUAL, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, BACKUP_PRIORITY = 50, SECONDARY_ROLE(ALLOW_CONNECTIONS = NO), SEEDING_MODE = AUTOMATIC ), N'NODE-2' WITH ( ENDPOINT_URL = N'TCP://NODE-2:5022', FAILOVER_MODE = MANUAL, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, BACKUP_PRIORITY = 50, SECONDARY_ROLE(ALLOW_CONNECTIONS = NO), SEEDING_MODE = AUTOMATIC ); GOリスナーを作成します。
USE master; GO ALTER AVAILABILITY GROUP [gcp-dest-ag] ADD LISTENER N'gcp-dest-lsnr' ( WITH IP ( (N'
LISTENER_IP', N'255.255.255.0') ), PORT = 1433); GOLISTENER_IPは、リスナーの IP アドレスに置き換えます。SSMS を使用して
node-2に接続し、次の T-SQL コマンドを実行してgcp-dest-ag可用性グループに追加します。USE master GO ALTER AVAILABILITY GROUP [gcp-dest-ag] JOIN; ALTER AVAILABILITY GROUP [gcp-dest-ag] GRANT CREATE ANY DATABASE;
SSMS を使用して AWS のソース SQL Server のプライマリ レプリカに接続し、次の T-SQL コマンドを実行して分散可用性グループを作成します。
USE [master] GO CREATE AVAILABILITY GROUP [distributed-ag] WITH (DISTRIBUTED) AVAILABILITY GROUP ON '
AWS_AG' WITH ( LISTENER_URL = 'tcp://AWS_LISTENER:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = AUTOMATIC ), 'gcp-dest-ag' WITH ( LISTENER_URL = 'tcp://gcp-dest-lsnr:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = AUTOMATIC ) GOAWS_AGは AWS の可用性グループの名前に、AWS_LISTENERは AWS 可用性グループのリスナーに置き換えます。node-1の SSMS で次の T-SQL コマンドを実行して、分散可用性グループに追加します。USE [master] GO ALTER AVAILABILITY GROUP [distributed-ag] JOIN AVAILABILITY GROUP ON '
AWS_AG' WITH ( LISTENER_URL = 'tcp://AWS_LISTENER:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = AUTOMATIC ), 'gcp-dest-ag' WITH ( LISTENER_URL = 'tcp://gcp-dest-lsnr:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, FAILOVER_MODE = MANUAL, SEEDING_MODE = AUTOMATIC ) GOAWS_AGは AWS の可用性グループの名前に、AWS_LISTENERは AWS 可用性グループのリスナーに置き換えます。「node-1」で次の T-SQL コマンドを実行して、すべての可用性グループが正常に動作し、分散可用性グループ全体で Cloud de Confiance by S3NSの新しい SQL Server クラスタに複製されていることを確認します。
SELECT * FROM sys.dm_hadr_availability_group_states GO
クリーンアップ
チュートリアルが終了したら、作成したリソースをクリーンアップして、割り当ての使用を停止し、課金されないようにできます。次のセクションで、リソースを削除または無効にする方法を説明します。
プロジェクトの削除
課金されないようにする最も簡単な方法は、チュートリアル用に作成したプロジェクトを削除することです。
プロジェクトを削除するには:
- In the Cloud de Confiance console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.