
このチュートリアルでは、データ アナリストが使用する承認済みビューを BigQuery で作成します。承認済みのビューを使用すると、元のソースデータへのアクセス権を付与することなく、特定のユーザーやグループとの間でクエリ結果を共有できます。ビューには、ユーザーまたはグループではなくソースデータへのアクセス権が付与されます。ビューの SQL クエリを使用して、クエリ結果から列とフィールドを除外することもできます。
承認済みビューを使用する別の方法として、ソースデータに列レベルのアクセス制御を設定し、アクセス制御されたデータをクエリするビューへのアクセス権をユーザーに付与することもできます。列レベルのアクセス制御の詳細については、列レベルのアクセス制御の概要をご覧ください。
同じソース データセットにアクセスする承認済みビューが複数ある場合は、個々のビューを承認する代わりに、ビューを含むデータセットを承認できます。
目標
- ML モデルを格納するデータセットを作成する。
- クエリを実行して、ソース データセットの宛先テーブルにデータを読み込む。
- 承認済みビューを含むデータセットを作成する。
- SQL クエリから承認済みビューを作成し、データ アナリストがクエリ結果で表示できる列を制限する。
- データ アナリストにクエリジョブを実行する権限を付与する。
- 承認済みビューを含むデータセットへのアクセス権をデータ アナリストに付与する。
- 承認済みビューにソース データセットへのアクセス権を付与する。
費用
このドキュメントでは、課金対象である次の Cloud de Confiance by S3NSコンポーネントを使用します。
このドキュメントに記載されているタスクの完了後、作成したリソースを削除すると、それ以上の請求は発生しません。詳細については、クリーンアップをご覧ください。
始める前に
-
In the Cloud de Confiance console, on the project selector page, select or create a Cloud de Confiance project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Cloud de Confiance project.
-
Enable the BigQuery API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. - このドキュメントのタスクを実行するために必要な権限が付与されていることを確認します。
[BigQuery] ページに移動します。
左側のペインで、 [エクスプローラ] をクリックします。

左側のペインが表示されていない場合は、 [左ペインを開く] をクリックしてペインを開きます。
[エクスプローラ] ペインで、データセットを作成するプロジェクトの横にある [アクションを表示] > [データセットを作成] をクリックします。
[データセットを作成する] ページで、次の操作を行います。
[データセット ID] に「
github_source_data」と入力します。[ロケーション タイプ] で、[マルチリージョン] が選択されていることを確認します。
[マルチリージョン] で、US または EU を選択します。このチュートリアルで作成するすべてのリソースは、同じマルチリージョン ロケーションに配置する必要があります。
[データセットを作成] をクリックします。
Cloud de Confiance コンソールで、[BigQuery] ページに移動します。
クエリエディタで次のステートメントを入力します。
CREATE SCHEMA github_source_data;
[実行] をクリックします。
[BigQuery] ページに移動します。
クエリエディタで以下のクエリを入力します。
SELECT commit, author, committer, repo_name FROM `bigquery-public-data.github_repos.commits` LIMIT 1000;[展開] をクリックして、[クエリの設定] を選択します。
[送信先] で [クエリ結果の宛先テーブルを設定する] をオンにします。
[データセット] に「
PROJECT_ID.github_source_data」と入力します。PROJECT_IDは、実際のプロジェクト ID に置き換えます。[テーブル ID] に「
github_contributors」と入力します。[保存] をクリックします。
[実行] をクリックします。
クエリが完了したら、[エクスプローラ] ペインで [データセット] をクリックし、
github_source_dataデータセットをクリックします。[概要 > テーブル] をクリックし、[
github_contributors] テーブルをクリックします。データがテーブルに書き込まれたことを確認するには、[プレビュー] タブをクリックします。
[BigQuery] ページに移動します。
左側のペインで、 [エクスプローラ] をクリックします。
[エクスプローラ] ペインで、データセットを作成するプロジェクトを選択します。
[アクションを表示] オプションを開き、[データセットを作成] をクリックします。
[データセットを作成する] ページで、次の操作を行います。
[データセット ID] に「
shared_views」と入力します。[ロケーション タイプ] で、[マルチリージョン] が選択されていることを確認します。
[マルチリージョン] で、US または EU を選択します。このチュートリアルで作成するすべてのリソースは、同じマルチリージョン ロケーションに配置する必要があります。
[データセットを作成] をクリックします。
Cloud de Confiance コンソールで、[BigQuery] ページに移動します。
クエリエディタで次のステートメントを入力します。
CREATE SCHEMA shared_views;
[実行] をクリックします。
[BigQuery] ページに移動します。
クエリエディタで、次のクエリを入力します。
SELECT commit, author.name AS author, committer.name AS committer, repo_name FROM `PROJECT_ID.github_source_data.github_contributors`;
PROJECT_IDは、実際のプロジェクト ID に置き換えます。[保存] > [ビューを保存] の順にクリックします。
[ビューの保存] ダイアログで、次の操作を行います。
[Project] で、必要なプロジェクトが選択されていることを確認します。
[データセット] に「
shared_views」と入力します。[テーブル] に「
github_analyst_view」と入力します。[保存] をクリックします。
Cloud de Confiance コンソールで、[BigQuery] ページに移動します。
クエリエディタで次のステートメントを入力します。
CREATE VIEW shared_views.github_analyst_view AS ( SELECT commit, author.name AS author, committer.name AS committer, repo_name FROM `PROJECT_ID.github_source_data.github_contributors` );
PROJECT_IDは、実際のプロジェクト ID に置き換えます。[実行] をクリックします。
Cloud de Confiance コンソールで、[IAM] ページに移動します。
プロジェクト セレクタでプロジェクトが選択されていることを確認します。
[アクセス権を付与] をクリックします。
[アクセス権を付与] ダイアログで、以下を行います。
[新しいプリンシパル] フィールドに、データ アナリストを含むグループを入力します(例:
data_analysts@example.com)。[ロールを選択] フィールドで、[BigQuery ユーザー] ロールを検索して選択します。
[保存] をクリックします。
[BigQuery] ページに移動します。
左側のペインで、 [エクスプローラ] をクリックします。
[エクスプローラ] ペインで、[データセット] をクリックし、
shared_viewsデータセットを選択して [詳細] タブを開きます。[共有] > [権限] の順にクリックします。
[共有権限] ペインで、[プリンシパルを追加] をクリックします。
[新しいプリンシパル] に、データ アナリストを含むグループを入力します(例:
data_analysts@example.com)。[ロールを選択] をクリックし、[BigQuery] > [BigQuery データ閲覧者] を選択します。
[保存] をクリックします。
[閉じる] をクリックします。
[BigQuery] ページに移動します。
左側のペインで、 [エクスプローラ] をクリックします。
[エクスプローラ] ペインで、[データセット] をクリックし、
github_source_dataデータセットを選択して [詳細] タブを開きます。[共有] > [ビューを承認] をクリックします。
[承認済みビュー] ペインの [承認済みビュー] に
PROJECT_ID.shared_views.github_analyst_viewと入力します。PROJECT_ID は、実際のプロジェクト ID に置き換えます。
[承認を追加] をクリックします。
[BigQuery] ページに移動します。
クエリエディタで次のステートメントを入力します。
SELECT * FROM `
PROJECT_ID.shared_views.github_analyst_view`;PROJECT_IDは、実際のプロジェクト ID に置き換えます。[実行] をクリックします。
- In the Cloud de Confiance console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- In the Cloud de Confiance console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- BigQuery のアクセス制御の詳細については、BigQuery の IAM ロールと権限をご覧ください。
- BigQuery ビューの詳細については、論理ビューの概要をご覧ください。
- 承認済みビューの詳細については、承認済みビューをご覧ください。
- アクセス制御の基本コンセプトについては、IAM の概要をご覧ください。
- アクセス制御の管理方法については、ポリシーの管理をご覧ください。
ソースデータを保存するデータセットを作成する
まず、ソースデータを格納するデータセットを作成します。
ソース データセットを作成するには、次のいずれかのオプションを選択します。
コンソール
SQL
CREATE SCHEMA DDL ステートメントを使用します。
クエリの実行方法については、インタラクティブ クエリを実行するをご覧ください。
Java
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Java の設定手順を完了してください。詳細については、BigQuery Java API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
コードサンプルを実行する前に、GOOGLE_CLOUD_UNIVERSE_DOMAIN 環境変数を s3nsapis.fr に設定します。
Python
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Python の設定手順を完了してください。詳細については、BigQuery Python API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
コードサンプルを実行する前に、GOOGLE_CLOUD_UNIVERSE_DOMAIN 環境変数を s3nsapis.fr に設定します。
テーブルを作成してソースデータを読み込む
ソース データセットを作成したら、SQL クエリの結果を宛先テーブルに保存して、そのテーブルにデータを入力します。このクエリでは、GitHub 一般公開データセットからデータを取得します。
コンソール
Java
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Java の設定手順を完了してください。詳細については、BigQuery Java API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
コードサンプルを実行する前に、GOOGLE_CLOUD_UNIVERSE_DOMAIN 環境変数を s3nsapis.fr に設定します。
Python
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Python の設定手順を完了してください。詳細については、BigQuery Python API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
コードサンプルを実行する前に、GOOGLE_CLOUD_UNIVERSE_DOMAIN 環境変数を s3nsapis.fr に設定します。
承認済みビューを格納するデータセットを作成する
ソース データセットを作成したら、データ アナリストと共有する承認済みビューを格納する新しい別のデータセットを作成します。後のステップで、ソース データセット内のデータへのアクセス権を承認済みビューに付与します。データ アナリストには承認済みビューへのアクセス権が付与されますが、ソースデータへの直接アクセス権は付与されません。
承認済みビューは、ソースデータとは別のデータセットで作成する必要があります。これにより、データのオーナーは元のデータへのアクセス権を同時に付与することなく、承認済みビューへのアクセス権を付与できます。ソース データセットと承認済みビューのデータセットは、同じリージョンのロケーションに存在する必要があります。
ビューを保存するデータセットを作成するには、次のいずれかのオプションを選択します。
コンソール
SQL
CREATE SCHEMA DDL ステートメントを使用します。
クエリの実行方法については、インタラクティブ クエリを実行するをご覧ください。
Java
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Java の設定手順を完了してください。詳細については、BigQuery Java API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
コードサンプルを実行する前に、GOOGLE_CLOUD_UNIVERSE_DOMAIN 環境変数を s3nsapis.fr に設定します。
Python
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Python の設定手順を完了してください。詳細については、BigQuery Python API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
コードサンプルを実行する前に、GOOGLE_CLOUD_UNIVERSE_DOMAIN 環境変数を s3nsapis.fr に設定します。
新しいデータセットに承認済みビューを作成する
新しいデータセットに、承認用に使用するビューを作成します。このビューをデータ アナリストと共有します。このビューは SQL クエリで作成します。このクエリで、データ アナリストに見せない列を除外します。
github_contributors ソーステーブルには、RECORD 型の 2 つのフィールド(author と committer)があります。このチュートリアルでは、承認済みビューから作成者の名前を除き、作成者のデータはすべて除外します。また、実行者の名前を除き、実行者のデータもすべて除外します。
新しいデータセットにビューを作成するには、次のいずれかのオプションを選択します。
コンソール
SQL
CREATE VIEW DDL ステートメントを使用します。
クエリの実行方法については、インタラクティブ クエリを実行するをご覧ください。
Java
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Java の設定手順を完了してください。詳細については、BigQuery Java API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
コードサンプルを実行する前に、GOOGLE_CLOUD_UNIVERSE_DOMAIN 環境変数を s3nsapis.fr に設定します。
Python
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Python の設定手順を完了してください。詳細については、BigQuery Python API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
コードサンプルを実行する前に、GOOGLE_CLOUD_UNIVERSE_DOMAIN 環境変数を s3nsapis.fr に設定します。
データ アナリストにクエリジョブを実行する権限を付与する
データ アナリストがビューにクエリを実行するには、クエリジョブを実行するための bigquery.jobs.create 権限と、ビューへのアクセス権が必要です。このセクションでは、データ アナリストに bigquery.user ロールを付与します。bigquery.user ロールには bigquery.jobs.create 権限が含まれています。後のステップで、データ アナリストにビューへのアクセス権を付与します。
プロジェクト レベルでデータ アナリストのグループを bigquery.user ロールに割り当てるには、次の操作を行います。
承認済みビューにクエリを実行する権限をデータ アナリストに付与する
データ アナリストがビューにクエリを実行するには、データセット レベルまたはビューレベルで bigquery.dataViewer ロールが必要です。データセット レベルでこのロールを付与すると、アナリストはデータセット内のすべてのテーブルとビューにアクセスできるようになります。このチュートリアルで作成したデータセットには 1 つの承認済みビューが含まれているため、データセット レベルでアクセス権を付与することになります。アクセス権を付与する必要がある承認済みビューのコレクションがある場合は、代わりに承認済みデータセットの使用を検討してください。
データ アナリストに付与した bigquery.user ロールにより、クエリジョブの作成に必要な権限が付与されます。ただし、承認済みビューまたはビューを含むデータセットへの bigquery.dataViewer アクセス権がないと、ビューを正常にクエリすることはできません。
承認済みビューを含むデータセットに対する bigquery.dataViewer アクセス権をデータ アナリストに付与するには、次の操作を行います。
コンソール
Java
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Java の設定手順を完了してください。詳細については、BigQuery Java API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
コードサンプルを実行する前に、GOOGLE_CLOUD_UNIVERSE_DOMAIN 環境変数を s3nsapis.fr に設定します。
Python
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Python の設定手順を完了してください。詳細については、BigQuery Python API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
コードサンプルを実行する前に、GOOGLE_CLOUD_UNIVERSE_DOMAIN 環境変数を s3nsapis.fr に設定します。
ソース データセットの表示アクセスを承認する
承認済みビューを含むデータセットのアクセス制御を作成したら、承認済みビューにソース データセットへのアクセス権を付与します。この承認により、ビューはソースデータにアクセスできますが、データ アナリスト グループはアクセスできません。
承認済みビューにソースデータへのアクセス権を付与するには、次のいずれかのオプションを選択します。
コンソール
Java
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Java の設定手順を完了してください。詳細については、BigQuery Java API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
コードサンプルを実行する前に、GOOGLE_CLOUD_UNIVERSE_DOMAIN 環境変数を s3nsapis.fr に設定します。
Python
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Python の設定手順を完了してください。詳細については、BigQuery Python API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
コードサンプルを実行する前に、GOOGLE_CLOUD_UNIVERSE_DOMAIN 環境変数を s3nsapis.fr に設定します。
構成を確認する
構成が完了すると、データ アナリスト グループ(たとえば、data_analysts)のメンバーがビューにクエリを実行して、構成を確認できます。
構成を確認するには、データ アナリストは次のクエリを実行する必要があります。
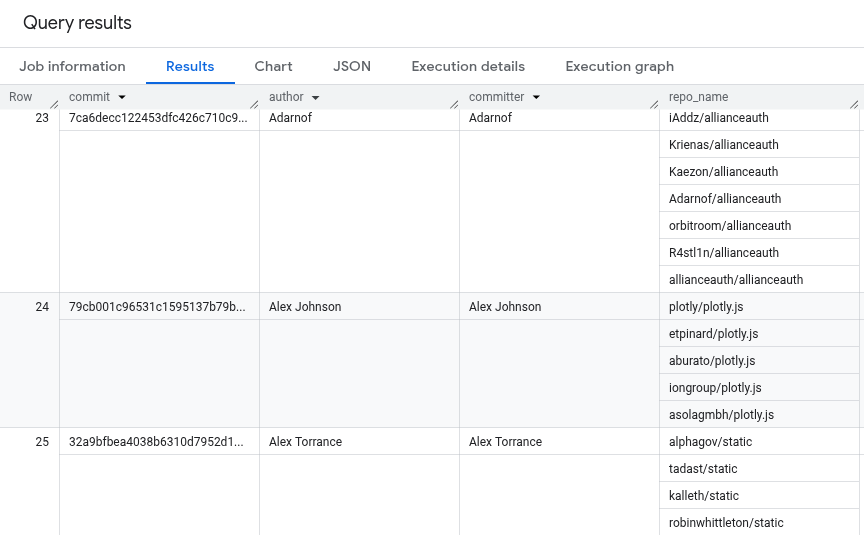
クエリの結果は次のようになります。結果には、作成者名とコミッター名のみが表示されます。
クエリの実行方法については、インタラクティブ クエリを実行するをご覧ください。
完全なソースコード
次に、このチュートリアル用のソースコード全体を示します。
Java
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Java の設定手順を完了してください。詳細については、BigQuery Java API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
コードサンプルを実行する前に、GOOGLE_CLOUD_UNIVERSE_DOMAIN 環境変数を s3nsapis.fr に設定します。
Python
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Python の設定手順を完了してください。詳細については、BigQuery Python API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
コードサンプルを実行する前に、GOOGLE_CLOUD_UNIVERSE_DOMAIN 環境変数を s3nsapis.fr に設定します。
クリーンアップ
このチュートリアルで使用したリソースについて、Google Cloud アカウントに課金されないようにするには、リソースを含むプロジェクトを削除するか、プロジェクトを維持して個々のリソースを削除します。
プロジェクトの削除
コンソール
gcloud
リソースを個別に削除する
もう一つの方法として、このチュートリアルで使用したリソースを個別に削除する場合は、次の操作を行います。
このチュートリアルで使用したリソースはご自身で作成したため、削除するための権限を追加する必要はありません。