
dbt で BigQuery DataFrames を使用する
dbt(データビルド ツール)は、最新のデータ ウェアハウス内のデータ変換用に設計されたオープンソースのコマンドライン フレームワークです。dbt は、再利用可能な SQL ベースのモデルと Python ベースのモデルを作成することで、モジュラー データの変換を容易にします。このツールは、ELT パイプラインの変換ステップに焦点を当て、ターゲット データ ウェアハウス内でのこれらの変換の実行をオーケストレートします。詳細については、dbt のドキュメントをご覧ください。
dbt で、Python モデルは、dbt プロジェクト内の Python コードを使用して定義および実行されるデータ変換です。変換ロジックを SQL で記述する代わりに、dbt がオーケストレートしてデータ ウェアハウス環境内で実行する Python スクリプトを記述します。Python モデルを使用すると、SQL で表現するには複雑または非効率的なデータ変換を実行できます。これにより、dbt のプロジェクト構造、オーケストレーション、依存関係の管理、テスト、ドキュメント機能のメリットを享受しながら、Python の機能を活用できます。詳細については、Python モデルをご覧ください。
dbt-bigquery アダプタは、BigQuery DataFrames で定義された Python コードの実行をサポートしています。この機能は dbt Cloud と dbt Core で使用できます。この機能は、dbt-bigquery アダプタの最新バージョンをクローニングすることでも取得できます。
始める前に
dbt-bigquery アダプタを使用するには、プロジェクトで次の API を有効にします。
- BigQuery API(
bigquery.googleapis.com) - Cloud Storage API(
storage.googleapis.com) - Compute Engine API(
compute.googleapis.com) - Dataform API(
dataform.googleapis.com) - Identity and Access Management API(
iam.googleapis.com) - Vertex AI API(
aiplatform.googleapis.com)
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM
role (roles/serviceusage.serviceUsageAdmin), which
contains the serviceusage.services.enable permission. Learn how to grant
roles.
必要なロール
dbt-bigquery アダプタは、OAuth ベースの認証とサービス アカウント ベースの認証をサポートしています。
OAuth を使用して dbt-bigquery アダプタに対する認証を行う場合は、次のロールを付与するよう管理者に依頼してください。
- プロジェクトに対する BigQuery ユーザーロール(
roles/bigquery.user) - テーブルが保存されているプロジェクトまたはデータセットに対する BigQuery データ編集者ロール(
roles/bigquery.dataEditor) - プロジェクトに対する Colab Enterprise ユーザーロール(
roles/colabEnterprise.user) - コードとログのステージング用のステージング Cloud Storage バケットに対するストレージ管理者ロール(
roles/storage.admin)
サービス アカウントを使用して dbt-bigquery アダプタに対する認証を行う場合は、使用するサービス アカウントに次のロールを付与するよう管理者に依頼してください。
- BigQuery ユーザーロール(
roles/bigquery.user) - BigQuery データ編集者(
roles/bigquery.dataEditor)ロール。 - Colab Enterprise ユーザーロール(
roles/colabEnterprise.user) - ストレージ管理者ロール(
roles/storage.admin)
サービス アカウントを使用して認証を行う場合は、使用するサービス アカウントにサービス アカウント ユーザーロール(roles/iam.serviceAccountUser)が付与されていることも確認してください。
共有 VPC 環境で Colab Enterprise を使用している場合は、次のロールと権限を付与するよう管理者に依頼してください。
compute.subnetworks.use権限: ホスト プロジェクトまたは特定のサブネットで Colab Enterprise ランタイムが使用するサービス アカウントにこの権限を付与します。この権限は、Compute ネットワーク ユーザーのロール(roles/compute.networkUser)に含まれています。compute.subnetworks.get権限: ホスト プロジェクトまたは特定のサブネットで Colab Enterprise ランタイムが使用するサービス アカウントにこの権限を付与します。この権限は、Compute ネットワーク閲覧者のロール(roles/compute.networkViewer)に含まれています。Compute ネットワーク ユーザーのロール(
roles/compute.networkUser): 共有 VPC ホスト プロジェクト上の Vertex AI サービス エージェントservice-PROJECT_NUMBER@gcp-sa-aiplatform.s3ns-system.iam.gserviceaccount.comにこのロールを付与します。Compute ネットワーク ユーザーのロール(
roles/compute.networkUser): ノートブック実行ジョブ機能を使用している場合は、共有 VPC ホスト プロジェクト上の Colab Enterprise サービス エージェントservice-PROJECT_NUMBER@gcp-sa-vertex-nb.s3ns-system.iam.gserviceaccount.comにこのロールを付与します。
ロールの付与については、プロジェクト、フォルダ、組織へのアクセス権の管理をご覧ください。
必要な権限は、カスタムロールや他の事前定義ロールから取得することもできます。
Python 実行環境
dbt-bigquery アダプタは、Colab Enterprise ノートブック実行サービスを利用して、BigQuery DataFrames Python コードを実行します。Colab Enterprise ノートブックは、すべての Python モデルに対して dbt-bigquery アダプタによって自動的に作成され、実行されます。ノートブックを実行するCloud de Confiance プロジェクトを選択できます。ノートブックは、モデルの Python コードを実行します。このコードは、BigQuery DataFrames ライブラリによって BigQuery SQL に変換されます。BigQuery SQL は、構成されたプロジェクトで実行されます。次の図は、制御フローを示しています。
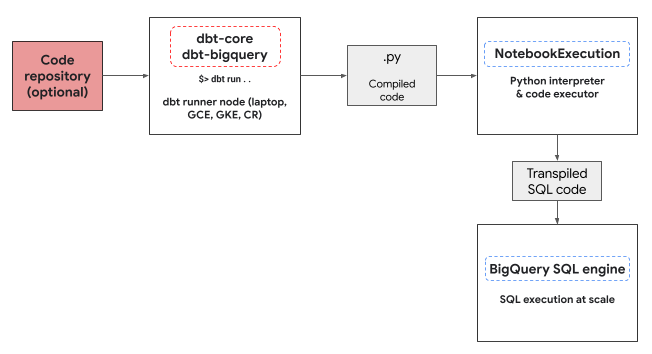
プロジェクトで使用可能なノートブック テンプレートがまだ存在せず、コードを実行するユーザーにテンプレートを作成する権限がある場合、dbt-bigquery アダプタはデフォルトのノートブック テンプレートを自動的に作成して使用します。dbt 構成を使用して、別のノートブック テンプレートを指定することもできます。
ノートブックの実行には、コードとログを保存するステージング Cloud Storage バケットが必要です。ただし、dbt-bigquery アダプタはログを dbt ログにコピーするため、バケットを確認する必要はありません。
サポートされている機能
dbt-bigquery アダプタは、BigQuery DataFrames を実行する dbt Python モデルに対して次の機能をサポートしています。
dbt.source()マクロを使用して、既存の BigQuery テーブルからデータを読み込みます。dbt.ref()マクロを使用して他の dbt モデルからデータを読み込み、依存関係を構築して、Python モデルで有向非巡回グラフ(DAG)を作成します。- Python コードの実行で使用できる PyPi の Python パッケージを指定して使用します。詳細については、構成をご覧ください。
- BigQuery DataFrames モデルのカスタム ノートブック ランタイム テンプレートを指定します。
dbt-bigquery アダプタは、次の実体化戦略をサポートしています。
- テーブルの実体化。データは実行ごとにテーブルとして再構築されます。
- マージ戦略を使用した増分実体化。新しいデータまたは更新されたデータが既存のテーブルに追加されます。多くの場合、マージ戦略を使用して変更を処理します。
BigQuery DataFrames を使用するための dbt の設定
dbt Core を使用している場合は、BigQuery DataFrames で使用するために profiles.yml ファイルを使用する必要があります。次の例では、oauth メソッドを使用します。
your_project_name:
outputs:
dev:
compute_region: us-central1
dataset: your_bq_dateset
gcs_bucket: your_gcs_bucket
job_execution_timeout_seconds: 300
job_retries: 1
location: US
method: oauth
priority: interactive
project: your_gcp_project
threads: 1
type: bigquery
target: dev
dbt Cloud を使用している場合は、dbt Cloud インターフェースで直接データ プラットフォームに接続できます。このシナリオでは、profiles.yml ファイルは必要ありません。詳細については、profiles.yml についてをご覧ください。
dbt_project.yml ファイルのプロジェクト レベルの構成の例を次に示します。
# Name your project! Project names should contain only lowercase characters
# and underscores. A good package name should reflect your organization's
# name or the intended use of these models.
name: 'your_project_name'
version: '1.0.0'
# Configuring models
# Full documentation: https://docs.getdbt.com/docs/configuring-models
# In this example config, we tell dbt to build all models in the example/
# directory as views. These settings can be overridden in the individual model
# files using the config(...) macro.
models:
your_project_name:
submission_method: bigframes
notebook_template_id: 7018811640745295872
packages: ["scikit-learn", "mlflow"]
timeout: 3000
# Config indicated by + and applies to all files under models/example/
example:
+materialized: view
一部のパラメータは、Python コード内の dbt.config メソッドを使用して構成することもできます。これらの設定が dbt_project.yml ファイルと競合する場合、dbt.config の構成が優先されます。
詳細については、モデル構成と dbt_project.yml をご覧ください。
構成
Python モデルの dbt.config メソッドを使用して、次の構成を設定できます。これらの構成は、プロジェクト レベルの構成をオーバーライドします。
| 構成 | 必須 | 用途 |
|---|---|---|
submission_method |
はい | submission_method=bigframes |
notebook_template_id |
いいえ | 指定しない場合は、デフォルトのテンプレートが作成されて使用されます。 |
packages |
いいえ | 必要に応じて、Python パッケージの追加リストを指定します。 |
timeout |
いいえ | 省略可: ジョブ実行のタイムアウトを延長します。 |
Python モデルの例
以降のセクションでは、シナリオの例と Python モデルを紹介します。
BigQuery テーブルからのデータの読み込み
既存の BigQuery テーブルのデータを Python モデルのソースとして使用するには、まずこのソースを YAML ファイルで定義します。次の例は、source.yml ファイルで定義されています。
version: 2
sources:
- name: my_project_source # A custom name for this source group
database: bigframes-dev # Your Google Cloud project ID
schema: yyy_test_us # The BigQuery dataset containing the table
tables:
- name: dev_sql1 # The name of your BigQuery table
次に、この YAML ファイルで構成されたデータソースを使用できる Python モデルを構築します。
def model(dbt, session):
# Configure the model to use BigFrames for submission
dbt.config(submission_method="bigframes")
# Load data from the 'dev_sql1' table within 'my_project_source'
source_data = dbt.source('my_project_source', 'dev_sql1')
# Example transformation: Create a new column 'id_new'
source_data['id_new'] = source_data['id'] * 10
return source_data
別のモデルの参照
次の例のように、他の dbt モデルの出力に依存するモデルを構築できます。これは、モジュラー データ パイプラインの作成に便利です。
def model(dbt, session):
# Configure the model to use BigFrames
dbt.config(submission_method="bigframes")
# Reference another dbt model named 'dev_sql1'.
# It assumes you have a model defined in 'dev_sql1.sql' or 'dev_sql1.py'.
df_from_sql = dbt.ref("dev_sql1")
# Example transformation on the data from the referenced model
df_from_sql['id'] = df_from_sql['id'] * 100
return df_from_sql
パッケージの依存関係の指定
Python モデルで MLflow や Boto3 などの特定のサードパーティ ライブラリが必要な場合は、次の例のように、モデルの構成でパッケージを宣言できます。これらのパッケージは実行環境にインストールされます。
def model(dbt, session):
# Configure the model for BigFrames and specify required packages
dbt.config(
submission_method="bigframes",
packages=["mlflow", "boto3"] # List the packages your model needs
)
# Import the specified packages for use in your model
import mlflow
import boto3
# Example: Create a DataFrame showing the versions of the imported packages
data = {
"mlflow_version": [mlflow.__version__],
"boto3_version": [boto3.__version__],
"note": ["This demonstrates accessing package versions after import."]
}
bdf = bpd.DataFrame(data)
return bdf
デフォルト以外のテンプレートの指定
実行環境をより細かく制御したり、事前構成された設定を使用するには、次の例のように、BigQuery DataFrames モデルにデフォルト以外のノートブック テンプレートを指定します。
def model(dbt, session):
dbt.config(
submission_method="bigframes",
# ID of your pre-created notebook template
notebook_template_id="857350349023451yyyy",
)
data = {"int": [1, 2, 3], "str": ['a', 'b', 'c']}
return bpd.DataFrame(data=data)
テーブルの実体化
dbt が Python モデルを実行するときに、結果をデータ ウェアハウスに保存する方法を認識する必要があります。これは実体化と呼ばれます。
標準テーブルの実体化の場合、dbt は実行するたびに、モデルの出力を使用してウェアハウス内のテーブルを作成または完全に置き換えます。これはデフォルトで行われるか、次の例のように materialized='table' プロパティを明示的に設定することで行われます。
def model(dbt, session):
dbt.config(
submission_method="bigframes",
# Instructs dbt to create/replace this model as a table
materialized='table',
)
data = {"int_column": [1, 2], "str_column": ['a', 'b']}
return bpd.DataFrame(data=data)
マージ戦略を使用した増分実体化により、dbt は新しい行または変更された行のみでテーブルを更新できます。テーブルを毎回完全に再構築すると非効率になる可能性があるため、この方法は大規模なデータセットで役立ちます。マージ戦略は、これらの更新を処理する一般的な方法です。
このアプローチでは、次の手順で変更をインテリジェントに統合します。
- 変更された既存の行を更新します。
- 新しい行を追加します。
- 構成によっては省略可: ソースに存在しなくなった行を削除します。
マージ戦略を使用するには、次の例のように、dbt がモデルの出力と既存のテーブルの間で一致する行を識別できるように、unique_key プロパティを指定する必要があります。
def model(dbt, session):
dbt.config(
submission_method="bigframes",
materialized='incremental',
incremental_strategy='merge',
unique_key='int', # Specifies the column to identify unique rows
)
# In this example:
# - Row with 'int' value 1 remains unchanged.
# - Row with 'int' value 2 has been updated.
# - Row with 'int' value 4 is a new addition.
# The 'merge' strategy will ensure that only the updated row ('int 2')
# and the new row ('int 4') are processed and integrated into the table.
data = {"int": [1, 2, 4], "str": ['a', 'bbbb', 'd']}
return bpd.DataFrame(data=data)
トラブルシューティング
dbt ログで Python の実行を確認できます。
また、[Colab Enterprise Executions] ページで、コードとログ(以前の実行を含む)を表示することもできます。
Colab Enterprise Executions に移動
課金
BigQuery DataFrames で dbt-bigquery アダプタを使用すると、次のことに対して Cloud de Confiance by S3NS の料金が発生します。
ノートブックの実行: ノートブック ランタイムの実行に対して課金されます。詳細については、ノートブック ランタイムの料金をご覧ください。
BigQuery クエリの実行: ノートブックで、BigQuery DataFrames は Python を SQL に変換し、BigQuery でコードを実行します。BigQuery DataFrames の料金で説明されているように、プロジェクトの構成とクエリに応じて課金されます。
BigQuery の課金コンソールで次の課金ラベルを使用すると、ノートブックの実行と dbt-bigquery アダプタによってトリガーされた BigQuery の実行の課金レポートを除外できます。
- BigQuery 実行ラベル:
bigframes-dbt-api
次のステップ
- dbt と BigQuery DataFrames の詳細については、dbt Python モデルで BigQuery DataFrames を使用するをご覧ください。
- dbt Python モデルの詳細については、Python モデルと Python モデルの構成をご覧ください。
- Colab Enterprise ノートブックの詳細については、 Cloud de Confiance コンソールを使用して Colab Enterprise ノートブックを作成するをご覧ください。
- Cloud de Confiance by S3NS パートナーの詳細については、Cloud de Confiance by S3NS Ready - BigQuery パートナーをご覧ください。