
このチュートリアルでは、BigQuery ML の組み込みの TimesFM 単変量モデルで AI.FORECAST 関数を使用して、特定の列の過去の値に基づいてその列の将来の値を予測する方法について説明します。
このチュートリアルでは、一般公開テーブル bigquery-public-data.san_francisco_bikeshare.bikeshare_trips のデータを使用します。
目標
このチュートリアルでは、組み込みの TimesFM モデルで AI.FORECAST 関数を使用して、シェアサイクルの利用状況を予測する方法について説明します。最初の 2 つのセクションでは、単一の時系列の予測と、結果のを可視化する方法について説明します。3 つ目のセクションでは、複数の時系列での予測について説明します。
費用
このチュートリアルでは、課金対象となる以下の Cloud de Confiance by S3NSのコンポーネントを使用しています。
- BigQuery
- BigQuery ML
BigQuery の費用の詳細については、BigQuery の料金ページをご覧ください。
BigQuery ML の費用の詳細については、BigQuery ML の料金をご覧ください。
始める前に
-
In the Cloud de Confiance console, on the project selector page, select or create a Cloud de Confiance project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Cloud de Confiance project.
- 新しいプロジェクトでは、BigQuery が自動的に有効になります。既存のプロジェクトで BigQuery を有効にするには:
Enable the BigQuery API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
1 台のシェアサイクルの利用状況の時系列データを予測する
AI.FORECAST 関数を使用して、将来の時系列値を予測します。
次のクエリは、過去 4 か月間の履歴データに基づいて、翌月(約 720 時間)の 1 時間あたりのシェアサイクルの利用者数を予測します。confidence_level 引数は、クエリが 95% 信頼区間の予測間隔を生成することを表します。
次の手順でモデルを使用し、データを予測します。
Cloud de Confiance コンソールで、[BigQuery] ページに移動します。
クエリエディタに次のクエリを貼り付け、[実行] をクリックします。
SELECT * FROM AI.FORECAST( ( SELECT TIMESTAMP_TRUNC(start_date, HOUR) as trip_hour, COUNT(*) as num_trips FROM `bigquery-public-data.san_francisco_bikeshare.bikeshare_trips` WHERE subscriber_type = 'Subscriber' AND start_date >= TIMESTAMP('2018-01-01') GROUP BY TIMESTAMP_TRUNC(start_date, HOUR) ), horizon => 720, confidence_level => 0.95, timestamp_col => 'trip_hour', data_col => 'num_trips');
結果は次のようになります。
+-------------------------+-------------------+------------------+---------------------------------+---------------------------------+--------------------+ | forecast_timestamp | forecast_value | confidence_level | prediction_interval_lower_bound | prediction_interval_upper_bound | ai_forecast_status | +-------------------------+-------------------+------------------+---------------------------------+---------------------------------+--------------------+ | 2018-05-01 00:00:00 UTC | 26.3045959... | 0.95 | 21.7088378... | 30.9003540... | | +-------------------------+-------------------+------------------+---------------------------------+---------------------------------+--------------------+ | 2018-05-01 01:00:00 UTC | 34.0890502... | 0.95 | 2.47682913... | 65.7012714... | | +-------------------------+-------------------+------------------+---------------------------------+---------------------------------+--------------------+ | 2018-05-01 02:00:00 UTC | 24.2154693... | 0.95 | 2.87621605... | 45.5547226... | | +-------------------------+-------------------+------------------+---------------------------------+---------------------------------+--------------------+ | ... | ... | ... | ... | ... | | +-------------------------+-------------------+------------------+---------------------------------+---------------------------------+--------------------+
予測データを入力データと比較する
AI.FORECAST 関数の出力と関数入力データのサブセットを並べてグラフ化し、比較します。
関数出力をグラフに表示する手順は次のとおりです。
Cloud de Confiance コンソールで、[BigQuery] ページに移動します。
クエリエディタに次のクエリを貼り付け、[実行] をクリックします。
WITH historical AS ( SELECT TIMESTAMP_TRUNC(start_date, HOUR) as trip_hour, COUNT(*) as num_trips FROM `bigquery-public-data.san_francisco_bikeshare.bikeshare_trips` WHERE subscriber_type = 'Subscriber' AND start_date >= TIMESTAMP('2018-01-01') GROUP BY TIMESTAMP_TRUNC(start_date, HOUR) ORDER BY TIMESTAMP_TRUNC(start_date, HOUR) ) SELECT * FROM ( (SELECT trip_hour as date, num_trips AS historical_value, NULL as forecast_value, 'historical' as type, NULL as prediction_interval_lower_bound, NULL as prediction_interval_upper_bound FROM historical ORDER BY historical.trip_hour DESC LIMIT 400) UNION ALL (SELECT forecast_timestamp AS date, NULL as historical_value, forecast_value as forecast_value, 'forecast' as type, prediction_interval_lower_bound, prediction_interval_upper_bound FROM AI.FORECAST( ( SELECT * FROM historical ), horizon => 720, confidence_level => 0.99, timestamp_col => 'trip_hour', data_col => 'num_trips'))) ORDER BY date asc;
クエリの実行が完了したら、[クエリ結果] ペインの [可視化] タブをクリックします。作成されたグラフは次のようになります。
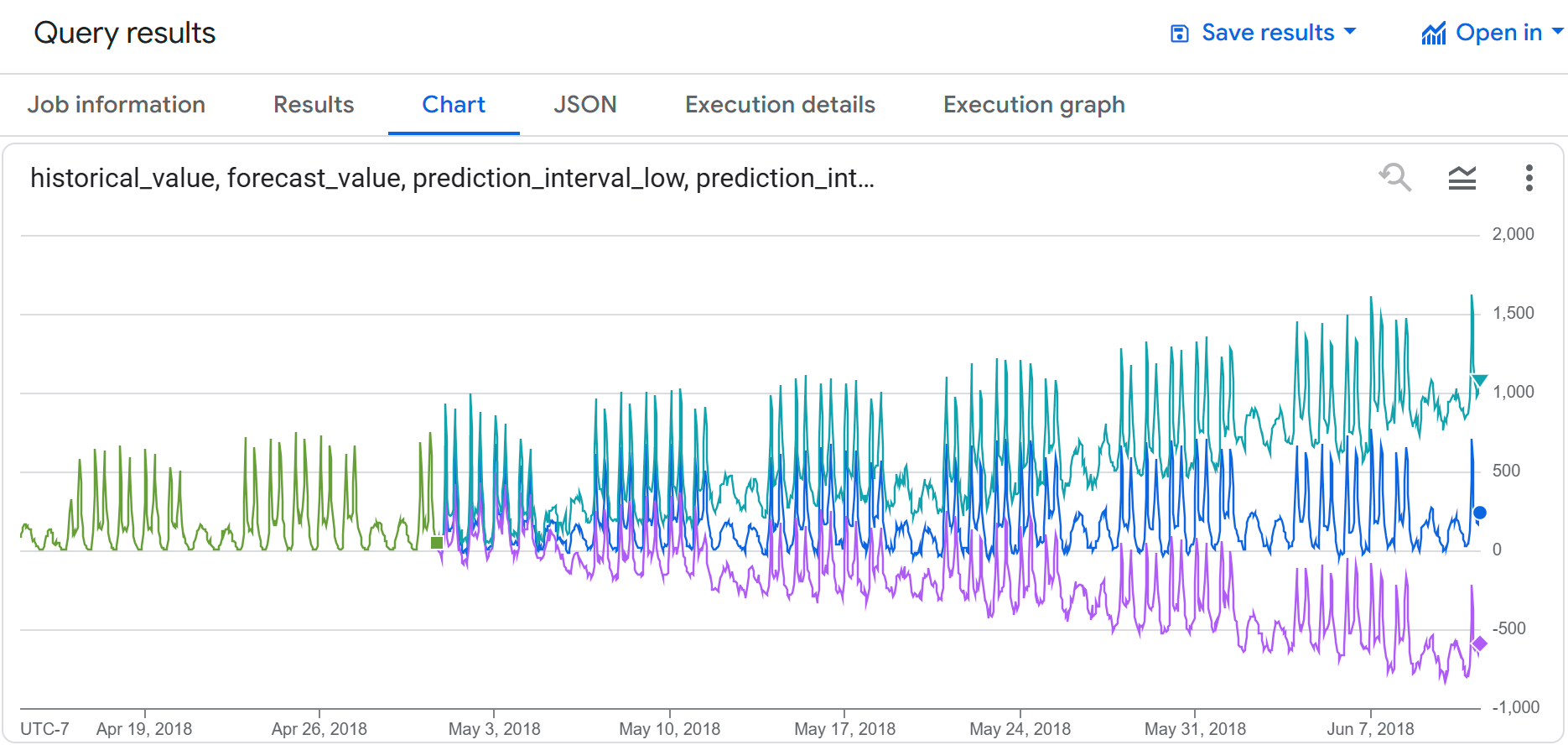
入力データと予測データで、シェアサイクルの使用状況が類似していることがわかります。また、予測時間点が将来に近づくにつれて、予測区間の下限と上限が増加することもわかります。
複数のシェアサイクルの利用状況の時系列データを予測する
次のクエリは、過去 4 か月間の履歴データに基づいて、次の 1 か月間(約 720 時間)の利用者のタイプ別、時間別のシェアサイクルの利用状況を予測します。confidence_level 引数は、クエリが 95% 信頼区間の予測間隔を生成することを表します。
次の手順でモデルを使用し、データを予測します。
Cloud de Confiance コンソールで、[BigQuery] ページに移動します。
クエリエディタに次のクエリを貼り付け、[実行] をクリックします。
SELECT * FROM AI.FORECAST( ( SELECT TIMESTAMP_TRUNC(start_date, HOUR) as trip_hour, subscriber_type, COUNT(*) as num_trips FROM `bigquery-public-data.san_francisco_bikeshare.bikeshare_trips` WHERE start_date >= TIMESTAMP('2018-01-01') GROUP BY TIMESTAMP_TRUNC(start_date, HOUR), subscriber_type ), horizon => 720, confidence_level => 0.95, timestamp_col => 'trip_hour', data_col => 'num_trips', id_cols => ['subscriber_type']);
結果は次のようになります。
+---------------------+--------------------------+------------------+------------------+---------------------------------+---------------------------------+--------------------+ | subscriber_type | forecast_timestamp | forecast_value | confidence_level | prediction_interval_lower_bound | prediction_interval_upper_bound | ai_forecast_status | +---------------------+--------------------------+------------------+------------------+---------------------------------+---------------------------------+--------------------+ | Subscriber | 2018-05-01 00:00:00 UTC | 26.3045959... | 0.95 | 21.7088378... | 30.9003540... | | +---------------------+--------------------------+------------------+------------------+---------------------------------+---------------------------------+--------------------+ | Subscriber | 2018-05-01 01:00:00 UTC | 34.0890502... | 0.95 | 2.47682913... | 65.7012714... | | +---------------------+-------------------+------------------+-------------------------+---------------------------------+---------------------------------+--------------------+ | Subscriber | 2018-05-01 02:00:00 UTC | 24.2154693... | 0.95 | 2.87621605... | 45.5547226... | | +---------------------+--------------------------+------------------+------------------+---------------------------------+---------------------------------+--------------------+ | ... | ... | ... | ... | ... | ... | | +---------------------+--------------------------+------------------+------------------+---------------------------------+---------------------------------+--------------------+
クリーンアップ
このチュートリアルで使用したリソースについて、Google Cloud アカウントに課金されないようにするには、リソースを含むプロジェクトを削除するか、プロジェクトを維持して個々のリソースを削除します。
プロジェクトを削除する
プロジェクトを削除するには:
- In the Cloud de Confiance console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
次のステップ
- BigQuery ML の概要について、BigQuery の AI と ML の概要で確認する。